Interfacing Random and Non-Random Genetic
Models by Chaotic Dynamical Systems
1Roberto N. Padua, 2Jay P. Picardal, 2Jezyl T. Cempron, 2Dexter S. Ontoy and
2Sherlenie Tecson
1Liceo de Cagayan 2Cebu Normal University
Date Submitted: May 8, 2011 Originality:
Date Revised: February 21, 2012 Readability:
ABSTRACT
The study tested whether genetic mutations (point mutations) are random or non-random phenomena through simulation experiments using the amino acid sequencing of human CD4 lymphocytes. The randomness or lack thereof of point mutations has crucial implications to Darwin‘s theory of evolution and natural selection. A single hypothesis is tested in the study , namely, that genetic mutations can be regarded as both random and deterministic. This hypothesis was accepted since no significant difference was noted in the mutations induced by a purely random process (Beta(.5,.5)) and a deterministic chaotic dynamical function (logistic function on [0,1]). The beta density was used as a representation of a random process since it is the ergodic distribution of the corresponding deterministic dynamical system. The implication is that if it were possible to discover the driving function for the genetic sequencing of nucleotide bases then point mutations can be predicted. However, as the study has demonstrated, even knowing that the point mutations are in fact deterministically generated, knowledge of the initial conditions is a crucial factor in predicting the mutation outcomes because chaotic dynamical systems are extremely sensitive to initial conditions.
Keywords: point mutation, insertion, deletion, substitution, chaotic dynamics, gene sequence
INTRODUCTION
The determination of whether or not genetic mutations occur randomly or non-randomly is crucial to Darwin‘s theory of evolution. Current thinking in the scientific community favors random genetic mutations, either point mutations or chromosomal mutations, rather than non-random mutation mechanisms. Consider, however, the case if mutation is not random, and if there is no evidence to suggest that it is, then there can be no such thing as natural selection, because there is nothing to select for. If there is no such thing as natural selection, then there can be no theory of evolution that justifies Darwin‘s claim.
The argument for a non-random genetic mutation model stems from the discovery by McClintock (1953) of a nucleic base sequence known as transposons. This sequence has the ability to remove itself from a DNA strand, move along the chromosome and then reinsert itself. If the transposon sets itself in the middle of a
89%
start codon, then the protein will not be coded at all, because the large molecule does not recognize where to begin. If, on the other hand, the transposon puts itself anywhere else along a gene, it alters the amino acid structure of the protein and thus changes its function. Barbara McClintock (1953), a genetic scientist, had purportedly discovered that the genetic mutation is "internally engineered" by a gene regulator; hence the genetic mutation is not a random event. McClintock discovered moving elements (transposons) and hypothesized that they acted as gene regulators. Her claim regarding the movable elements being the regulators was disproved in the 1960‘s (Jacob and Monod). Transposons are related to viruses and their insertion has preferred sites. While McClintock‘s discovery of transposable elements was accepted fairly quickly, her hypothesis that control is established by transposition turned out to be wrong.
There are two notions of randomness -- theoretical and practical. The practical definition, no predictable pattern or outcome, is the one used. Many mutation effects target specific entities with greater probability. Thus, some wavelengths of UV light can link two adjacent thymines. Given the huge number of adjacent thymine pairs in the genome, even if we can expect a few to be formed by giving a controlled amount of UV light exposure, we cannot determine which pair. Transposons behave similarly in the sense that there are sites receiving the element with greater probability, but the sites are too many, so that the insertion is, by practical consideration, considered random.
The purpose of this paper was to compare and analyze the two competing theories on genetic mutation: one theory espouses that such mutations occur randomly (in the practical sense mentioned above) and the other theory avers that genetic mutations occur in a deterministic, albeit unpredictable, fashion, i.e., that there is a deterministic rule that regulates mutations. Specifically, the paper attempted to test the following hypothesis through numerical simulations:
Hypothesis: Mutations at the point mutation level can be random or driven by a deterministic chaotic dynamical function.
We note that acceptance of the hypothesis implies that although mutations are deterministic, they cannot be distinguished from a random process because of the chaotic and complex behaviour of the deterministic driving mechanism. Finally, the idea of using a deterministic chaotic dynamical system as a driving mechanism for mutations may not have been tried out in the past because the discovery of deterministic chaotic dynamics did not occur until the latter part of the 1960‘s and early 1970‘s with the pioneering work of Lorentz. Even then, progress in the area of chaotic dynamical systems had been slow and its re-emergence in the early part of 2000 is attributed to the rapid advancement in computing technology.
LITERATURE REVIEW
randomness in mutation has been challenged, suggesting that simple organisms have the mechanisms to direct mutations (Sniegowski and Lenski, 1995). However, several experiments reported the non-randomness of mutations which did not fare well, but resurfaced under the name of ―adaptive mutation‖ (it was initially called “directed mutation”). Over the years, this concept has received strong criticism. However, these criticisms did not invalidate the argument of non-randomness, but rather necessitated concrete evidences to support such evolutionary hypotheses (Sniegowski and Lenski, 1995).
To the proponents of random mutations, unpredictable mutations constantly occur in the genomes of organisms and these mutations create genetic variation. Some studies in the fly Drosophila melanogaster appear to show that if a mutation alters a protein produced by a gene, data appear to support the contention that this will probably be harmful, with about 70% of these mutations having damaging effects, and the remainder being either neutral or weakly beneficial. (Lodish et al., 2004). Due to the damaging effects that mutations can have on cells, organisms have evolved mechanisms such as DNA repair to remove mutations. Therefore, the optimal mutation rate for a species is a trade-off between costs of a high mutation rate, such as deleterious mutations, and the metabolic costs of maintaining systems to reduce the mutation rate, such as DNA repair enzymes. Viruses that use RNA as their genetic material have rapid mutation rates, which can be an advantage since these viruses will evolve constantly and rapidly, and thus evade the defensive responses of humans, e.g. the human immune system.
In 1952, Esther and Joshua Lederberg performed an experiment that helped to show that many mutations are random, not directed. The hypothesis for the experiment was that antibiotic resistant strains of bacteria surviving an application of antibiotics had the resistance before their exposure to the antibiotics, not as a result of the exposure. The experiment proved that penicillin-resistant bacteria were there in the population before they encountered penicillin. They did not evolve resistance in response to exposure to the antibiotic (as cited in Lodish, 2004).
experiments demonstrating spontaneous mutation and raised a new controversy over the possibility of non-Darwinian adaptation.
Drake et al.(1991) and Stahl (1992) seemed to have found the evidence for directed mutation convincing, since claims for such emerged from some powerful experimental systems as the original demonstrations of random mutation. However, two important aspects of the classic experiments have been overlooked by directed mutation proponents. First, the authors of the classic experiments were careful about the assumptions of their tests. For example, in its simplest form, the sib selection experiment assumes that putative mutants and their progenitors grow at equal rates (are equally fit) in the absence of selective agents. If , instead, mutants grow more slowly (less fit), then the results of the experiment will deviate from randomness in a manner consistent with directed mutation. Rather than immediately invoke directed mutation on such evidence, Cavalli-Sforza and Lederberg (1956) considered and quantitatively tested the alternative hypothesis of differential growth rates. Second, the observation that some mutations occur after cells are exposed to a selective agent does not indicate that mutations are caused by selection. To imply that postselection per se challenges the Darwinian view of adaptation is to confuse the method of the classic experiments( variation arises before the imposition of selection) with the logical interpretation of the results (variation is not caused by selection).
Sniegowski and Lenski (1995) provide an incise review of all experimental attempts at demonstrating directed mutation up to 1995. They suggested three (3) possible approaches in the future that may shed light on the controversy: theoretical analysis (as the current paper purports to do), comparative approach, where organismal traits are correlated with features of their environment, and bacterial experiments.
Information on the CD4 Gene Sequence
Official name: CD4 gene (Homo sapiens). Other Designations: CD4 antigen (p55); CD4 receptor; OTTHUMP00000238897; T-cell surface antigen T4/Leu-3 (NCBI, 2011).
Locus Description
CD4 is located on chromosome 12 at 12pter-p12 (Isobe et al., 1986; Kozbor et al., 1986). It is also known that CD4 gene spans at least 33 kb and is composed of 10 exons (Maddon et al., 1987).
Structure and function of CD4 membrane glycoprotein:
CD4 is a molecule on the surface of a T-lymphocyte and brain cells that serves as the attachment point for the human immunodeficiency virus. Each CD4 molecule contains 433 amino acids. (Alcamo 1997). Aside from its basic role in immune response, CD4 also serves as human immunodeficiency virus (HIV) receptors, binding directly to the envelope protein gp120 on HIV (Lyerly et al., 1987). The cytoplasmic part of CD4 is known to be essential for interaction with the HIV-1 proteins Vpu and Nef (Willbold and Rosch, 1996).
A CD4 count is the measured level of a certain type of protein, which is often present in certain types of white blood cells. CD4 stands for "cluster of differentiation four," and is an important component of the body's ability to produce an immune response to a would-be infection. A CD4 count can also refer to the specific lab work that is done to determine its level, as a routine part of treatment for someone with the human immunodeficiency virus (HIV), which can lead to acquired immune deficiency syndrome (AIDS).
CD4 is often present in T-cells and other cells which form and coordinate the body's immune system. The HIV virus can take over and use these cells to make copies of itself, which go on to use other immune cells to make other copies. For a while, the body can replace T-cells at a fast enough rate to combat this pattern. As HIV progresses, a person's CD4 count will go lower and lower, indicating that the presence of the virus is stronger. The results of a CD4 count are usually expressed in the number of cells per microliter of blood, an amount which is roughly the size of a pea. A person who is free of HIV will normally have upwards of 750 T-cells in this amount of blood. Someone who is HIV positive is considered to have a normal CD4 count if this number is around 500 in the same amount of blood. Should this number be lowered below 200, this will be an indication of serious immune damage.
HIV positive patients are harboring the HIV virus in their bodies in the CD4 lymphocytes cells in their bodies. CD4 cells are better known as T cells. The acronym CD4 is an equivalent for the words "cluster of differentiation". These cells protect the body from infection. We obtained the complete CD4 antigen (p55) CD4 gene amino acid sequence which has a length of n = 11,697 amino acids (roughly 35,000+ nucleotide bases) from the gene data bank.
The Simulation Experiments
The Mutation Program
We investigated the phenomenon of mutations at the point mutation level i.e. changes in the nucleotide bases. The general framework for testing each of the hypotheses earlier presented is provided below:
Mutation Program
The algorithm for the mutation program is based on the following considerations and steps: First, we inputted the nucleotide base of the CD4 antigen amino acid sequence in the first column of a worksheet. Then, using a statistical software, we generated Beta (First shape parameter: 0.5; Second shape parameter: 0.5) random data and copied them on the second column of the work sheet, pairing each nucleotide base with a point mutation probability (pmp). For each pair, we evaluated if the point mutation probability (pmp) was greater than the point mutation probability constant p, in this case p = 0.999; if this was true, we replaced the nucleotide base with another nucleotide base based on the following table; otherwise, we retained the original nucleotide base.
The choice of the beta density, β(0.5, 0.5), is based on the ergodic distribution of the logistic map (see Ruelle, Berliner et al., 2001) and was used in this experiment for convenience. We could, if desired, begin with any member of the family of beta densities and then fit a corresponding logistic dynamical function to the result. Ergodicity begins to appear only when the observed trajectory is large, n →∞. In this study, the CD4 antigen (p55) CD4 gene amino acid sequence had a length of n = 11,697 amino acids (roughly 35,000+ nucleotide bases) which can be considered large.
Function
MUTATE
NO
YES K kind Random
Chaotic Dynamics
Subst
Insert
Delete
Subst
Insert
Delete
YES
YES K FIT.
K FIT. NO
NO
Natural Selection
Natural Selection A
Su
bst
B
Su
Original
Nucleotide Base Replace with this Nucleotide Base if pmp > p=0.999
A T
C G
G C
T A
T U
U T
We then proceeded to identify the amino acid sequence of the original nucleotide base and did the same for the evaluated nucleotide base to determine whether a silent, mis-sense or non-sense mutation occurred. We counted the number of observations for each instance: silent, mis-sense, non-sense, no mutation and we found the percentage of each instance. The process is repeated 100 times. Instead of generating Beta Random Data, we repeated the steps but with the use of Logistic Data.
To test the first J-D Hypothesis:
The algorithm for testing the J2-D hypothesis is as follows:
1. Start with a correct and known sequence of amino acids for the production of a protein. Take the CD4 antigen (p55) CD4 gene amino acid sequence which has a length of n = 11,697 amino acids (roughly 35,000+ nucleotide bases) because the complete sequencing is known.
2. Input the sequence into the point mutation program.
3. Make two separate columns for mutation mechanisms for this Cd4 polypeptide: random and chaotic dynamics. The chaotic dynamical system is the logistic x→4x(1-x) while the random process is the ergodic distribution of this dynamical system which is the beta (.5,.5) probability distribution.
4. Compare the two mechanisms in terms of the number of incorrect proteins derived by mutation, i.e., analyze the codons derived by mutations.
5. Classify the mutations observed as ―silent‖, non-sense or stop. 6. Repeat steps 3-5 one hundred times.
7. Compare the frequencies of each type of mutation for the random and deterministic mutation mechanisms by appropriate statistical tests.
Statistical Analysis of Simulated Data
The simulated data were compared using a multinomial probability distribution framework. In effect, we compared multivariate vectors X derived from
a chaotic dynamical system and vectors Y derived from a purely random mechanism. The comparison was made by computing for large n, the statistic:
(6)
which obeys a chi – square distribution under the null hypothesis. It follows that we:
(7) Reject Ho iff (df = 3.)
In practice, the purely random sequence was first observed and a beta density was fitted. Given the fitted probability density function, we applied an inversion process using the Frobenius-Perron operator to obtain the corresponding chaotic dynamical function, or else, we fit a logistic distribution to the same random sequence observed. In either case, we obtained two sequences of numbers, one that was purely random and the other a chaotic dynamical system.
RESULTS
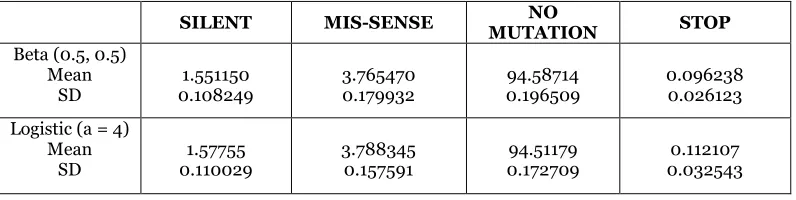
Table 1 summarizes the statistics computed from the simulation experiment. The table provides the means and standard deviations for the observed silent, mis-sense, non mutation and stop codons over one hundred (100) repetitions.
Table 1. Summary statistics
SILENT MIS-SENSE MUTATION NO STOP Beta (0.5, 0.5)
Mean
SD 0.108249 1.551150 3.765470 0.179932 0.196509 94.58714 0.096238 0.026123
Logistic (a = 4) Mean
SD 0.110029 1.57755 3.788345 0.157591 0.172709 94.51179 0.032543 0.112107
The vectors are the first row elements of the beta (0.5, 0.5) and logistic options, respectively. The covariance matrix S is was computed and the corresponding chi-square statistic was found to be:
, while (df = 3) = 9.348 and .
DISCUSSIONS
The present results indicate that the patterns of mutations induced by a pure random process (beta density) cannot be statistically differentiated from a deterministic dynamical system. In order words, the patterns of mutations induced by a purely random process can be replicated deterministically. The implication is that, for all practical purposes, point mutations can be viewed as having been triggered by deterministic driving mechanisms.
Once the deterministic driving mechanism is discovered, then the kind and frequency of mutations that will occur in a gene sequence can be exactly predicted. Biologically, this means that mutations do not just happen by ―chance‖ but certain factors trigger the occurrence of such deviations from normal amino acid sequences. The occurrence of point mutations, thereafter, is deterministically defined, although they would appear random because the deterministic driving mechanism is chaotic. Note that this result neither contradicts nor confirms Lederbergs‘ (1952) experimental results on resistant bacteria since in their study, penicillin-resistant bacteria were already present in the population.
In the light of the current research, if the initial conditions (trigger factors) are determined and defined, then it is possible to predict the outcomes of the evolutionary process due to mutations. For instance, an analysis has been made of erythrocyte glycophorin A (GPA) gene mutations in 1,226 atomic bomb survivors in Hiroshima and Nagasaki ( M. Akiyama et al., The Radiation Effects Foundation, Japan, 2007) . The findings are consistent with the hypothesis that somatic mutations are the main cause of excess cancer risk from radiation exposure.
Furthermore, there are other evidences of mutations induced by initial conditions (trigger factors) which could be cited. Weinberg et al. (2001) found very high mutation rates in offspring of Chernobyl accident liquidators. Exposure to ionizing radiation has long been suspected to increase the mutation load in humans. The research team used the offspring of accident liquidators, with children conceived before exposure to ionizing radiation serving as controls. An unexpectedly high sevenfold increase in the number of new bands in CA individuals compared with the level seen in controls was recorded. These results indicate that low doses of radiation can induce multiple changes in human germline DNA.
Evidences for directed mutation (non-random mutation) as illustrated in the preceding studies used lethal selective agents, and the commentaries of Sniegowski and Lenski (1995) might be invoked to contradict them. However, we maintain that in the light of our current theoretical analysis, these evidences appear consistent with the hypothesis of non-random but chaotic mutation.
The controversy over random viz. non-random mutation mechanism as re-awakened by the Cairns et al. (1988) paper will remain an unresolved issue unless one considers the alternative of a chaotic dynamical system operating in the context.
For all practical purposes, the trajectory followed by a chaotic dynamical function will appear random. Tong et al. (1999), for instance, concluded that the outputs of a logistic function Xt = 4Xt-1(1-Xt-1), t= 1, 2, 3, … , n, appear to be independent and identically distributed random numbers. This is precisely why proponents of a mutation model unwittingly insist on the random occurrence of mutations (because they appear random) despite the possibility of a purely deterministic driving mechanism.
The challenge is to discover the driving mechanism, e.g. logistic functions that triggered the sequence of trajectories resulting in the observed point mutation. Incidentally, this is the same problem being considered in mathematical dynamical systems. One approach suggested in the literature (Ruelle, Berliner et al., 2001) is to consider a dynamical system with a random noise model:
where εt are idd ―white noise‖ process. The approach is to recover by some non – parametric estimation procedure.
Although we have demonstrated the equivalence of ―random‖ mutations model and a ―deterministic‖ mutation model, the problem is far from being resolved. In fact, even assuming that a deterministic chaotic driving function is obtained, the starting value or initial condition remains unknown. Furthermore, chaotic functions are known to be extremely sensitive to initial conditions, so that a wrong initial value can lead to an entirely different sequence of amino acids.
CONCLUSION
We have demonstrated the equivalence of a random genetic mutation with a deterministic genetic mutation model in the case where the sequence of random numbers representing the occurrence of nucleotide bases in a polypeptide can be described by in appropriate member of the class of beta densities. The deterministic dynamical function describing such ―random‖ mutations is the logistic map x →4x (1-x). In effect, we have numerically shown that for certain classes of stationary and ergodic deterministic systems, a corresponding probability distribution f(x) can equally represent the mutations observed. Evidences culled from recent studies (Weinberg et al. (2001) and Akiyama et al. (2000)) appeared to support the theoretical analysis in this paper.
LITERATURE CITED
Akiyama,M., Kyoizumi,S., et al. (1996). Monitoring exposure to atomic bomb radiation by somatic mutation. ( Environmental Health Perspectives, Vol. 104, 493-496)
Cairns J, Foster PL. (1988). The origins of mutants. (Nature, Vol. 335, 142-145)
Cavalli-Sforza LL, Lederberg J. (1956). Isolation of preadaptive mutants in bacteria by sib selection. (Genetics, Vol. 41, 367-381)
Isobe M, Huebner K, Maddon PJ, Littman DR, Axel R, Croce CM. (1986). The gene encoding the T-cell surface protein T4 is located on human chromosome 12 (. Proc. Natl. Acad. Sci. U. S. A. 83:4399-402).
Kendrew J, Bodo G, Dintzis H, Parrish R, Wyckoff H, Phillips D (1958). "A three-dimensional model of the myoglobin molecule obtained by X-ray analysis".( Nature 181 (4610): 662–66).
Kozbor D, Finan J, Nowell PC, Croce CM. (1986). The gene encoding the T4 antigen maps to human chromosome 12".( J. Immunol. 136:1141-3).
Lyerly HK, Matthews TJ, Langlois AJ, Bolognesi DP, Weinhold KJ. (1987). Human T-cell lymphotropic virus IIIB glycoprotein (gp120) bound to CD4 determinants on normal lymphocytes and expressed by infected cells serves as target for immune attack.( Proc. Natl. Acad. Sci. U. S. A. 84:4601-5).
Lodish,M. and Murnane J.P. et al. (2004). Protein alteration in the fly Drosophila melanogoster.(Genetics, Vol 178,314-320)
Maddon PJ, Molineaux SM, Maddon DE, Zimmerman KA, Godfrey M, Alt FW, Chess L, Axel R. (1987). Structure and expression of the human and mouse T4 genes.( Proc. Natl. Acad. Sci. U. S. A. 84:9155-9).
Nachman,M. and Crowell,S.L.(2000). Estimate of the mutation rate per nucleotide in humans.(Genetics, Vol. 156, 297-304).
National Center for Biotechnology Information [NCBI]. (2011). CD4 molecule. Available as http://www.ncbi.nlm.nih.gov/gene/920
Nelson DL, Cox MM (2005). Lehninger's Principles of Biochemistry (4th ed.).( New York, New York: W. H. Freeman and Company).
Ruelle, S, Berliner, D. (2001) ―Ergodic Distributions of Random Dynamical Systems‖ (Journal of Dynamical Systems,Vol. 40, 218-229)
Sniegowski P.D. and Lenski , R.E. (1995). Mutation and Adaptation: The directed mutation controversy in evolutionary perspective. (Annual Reviews of Ecological Systems, Vo. 26, 553-578)
Tong, W. and Chang, S. (1994) ― Estimation of the Parameters of a Logistic Map‖ (Journal of Dynamical Systems, Vol. 27, 321-336).
Weinberg, Sh. H, Korol,A.B. et al.(2001). Very high mutation rate in offsprings of Chernobyl accident liquidators.(Proceedings of the Royal Society of London, Vol. 268, 1001-1005).