Development of E-Learning System using
Transliteration
V. NARASIMHULU
Department of Computer Science, Pondicherry Central University,
Pondicherry, India.
P. SUJATHA
Department of Computer Science, Pondicherry Central University,
Pondicherry, India.
P. DHAVACHELVAN
Department of Computer Science, Pondicherry Central University,
Pondicherry, India.
S. PARTHIBAN
Sr. Technical Analyst Department of Computer Science,
Pondicherry Central University, Pondicherry, India
Abstract: E-learning has migrated from an alternative training delivery mechanism to a platform for delivering innovative, creative, and transformational learning experiences. Simply interactive e-learning programs deliver content that is engaging and allows in-depth user interactivity coupled with sound instructional philosophies.It provides the mutual communication between the users and they can share information and knowledge. It is the emerging research area where different technological issues have been introduced. In this paper, our attempt is to incorporate transliteration technique to avoid difficulties faced by the clients or users who could not read the language easily but he or she can understand. It is a new approach in web based e-learning systems. The advantage of the proposed system is flexible and clients may use vividly. The system is evaluated with four different language documents collection.
Keywords: E-learning, Transliteration, Grapheme, Phoneme, Hybrid.
1. Introduction
E-learning is the delivery of a learning, training or education program by electronic means [21]. It involves the use of a computer or electronic device (e.g. a mobile phone) in some way to provide training, educational or learning material. E-learning can involve a greater variety of equipment than online training or education, for as the name implies, "online" involves using the Internet or an Intranet.
of critical information. E-coaching and e-mentoring are becoming more popular as Internet technologies match mentors and mentees and provide a communication avenue for remote mentoring. The present technological landscape of modern E-Learning is dominated by so-called learning management systems [5] such as [4] [22]. Learning management systems (LMS) are powerful integrated systems that support a number of activities performed by teachers and students during the E-Learning process. Teachers use an LMS to develop Web-based course notes and quizzes, to communicate with students and to monitor and grade student progress. Students use it for learning, communication and collaboration.
Transliteration is the process of transforming a word written in a source language into a word in a target language without the aid of a resource like a bilingual dictionary. The major techniques for transliteration can be classified into three categories: grapheme-based, phoneme-based and Hybrid transliteration models [19]. Grapheme refers to the basic unit of written language. In grapheme-based transliteration spelling of the original string is considered as a basis for transliteration. It is referred to as the direct method because it directly transforms source language graphemes into target language graphemes without any phonetic knowledge. Here transliteration is identified by mapping the source language words to their equivalent words in a target language and generating them. Phoneme refers to the simplest significant unit of sound. In phoneme-based transliteration pronunciation rather than spelling of the original string is considered as a basis for transliteration. It is referred as a pivot method because it uses source language phonemes as a pivot, when it produces target language graphemes from source language graphemes. It usually needs two steps: Produce source language phonemes from source language graphemes and produce target language graphemes from source phonemes. These two steps are explicit if the transliteration system produces target language transliterations after producing the pronunciations of the source language words; they are implicit if the system uses phonemes implicitly in the transliteration stage and explicitly in the learning stage [2]. ARPAbet symbols are used to represent source phonemes. ARPAbet is one of the methods used for coding source phonemes into ASCII characters [11]. Grapheme-based and phoneme-based transliteration is referred to as hybrid transliteration. It makes use of both source language graphemes and phonemes, to produce target language transliterations.
This paper follows web based training approach and proposed an e-learning system based on grapheme based transliteration. This type of system is useful to the users in the following scenario: consider a client or user named “John”, who cannot read and write the document in French language, but understands the French language. He knows (read and write) English language very well. For example John opened a document, which is uploaded in any e-learning system and it is in French language. He is unable to read the document but he is able to understand the document by transliterating it into the English language, since he knows English language. In the real world, many clients or users are coming under this category. Our system enables them to use the e-learning system very efficiently and effectively.
2. Related Works
The first semantic transliteration of individual names was given in [15]. It is a phoneme-based transliteration and based on the word’s original semantic attributes. It is a probabilistic model for transliterating person names in Latin script into Chinese script. The author [19] proposed a model for improving machine transliteration using an ensemble of three different transliteration models for English to Korean and English to Japanese languages. Three transliteration models are grapheme, phoneme and both. Punjabi machine transliteration was given by [16]. It addresses the problem of transliteration for Punjabi language from Shahmukhi (Arabic script) to Gurmukhi using a set of transliteration rules (character mappings and dependency rules). A discriminative, Conditional Random Field (CRF)–Hidden Markov Model (HMM) model for transliterating words from Hindi to English was used in [8]. The model is a statistical transliteration model, which generates desired number of transliterations for a given source word. It is based on grapheme-based model and language independent. A phrase or grapheme-based statistical machine transliteration of named entities from English to Hindi using a small set of training and development data was shown by [20]. A CWF mapping model for transliterating named entities from English to Tamil was given by [10]. This is based on grapheme-based model in which transliteration equivalents are identified by mapping the source language names to their equivalents in target language database.
3. E-learning System using Transliteration
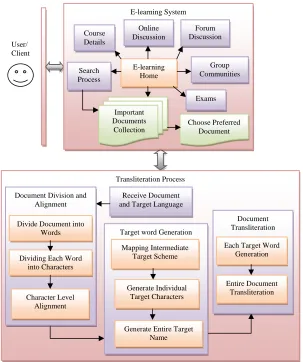
An e-learning system is proposed which mainly contains three modules: Login module, E-learning system and Transliteration process and is shown in Fig 1. Transliteration is included into the system for the purpose of those who are not familiar with the document language; they can transliterate the entire document into their interested language and read the document in the easiest way and learn the content quickly. The system modules are described below.
1. ‘Login module’ —this module is designed for authorized persons to enter into the e-learning system, which makes the system secure. The right persons to enter into system are administrator, lecture, student, and client. They can enter into the system and perform their operations according to their given rights. After finishing their job, they can logout from the system. More than one person can make use of the system simultaneously. Every one who wants to access the e-learning system they must register with unique id, using that they can enter into e-learning system. Otherwise they are not allowed to access the system. Anytime they can enter into the system, do their operations and logout at anytime.
2. ‘E-learning system’—it is the important part of the whole system. It provides the mutual communication between the client and administrator or student and lecturer. Administrator or lecturer logon to the system and modifies the course curriculum according to the technology. They can add or update the documents collection according to the course curriculum. Lecture teaches the course content to the students through online (online lectures) and discusses the content (online discussions). They provide the solutions to the questions posed by the students in the forum. They can conduct the exams through online. They can provide video lectures and conduct student competitive activities (e.g. quiz, paper presentations etc). Students or clients logon to the e-learning system and checks the course curriculum, read the materials provided by the lecturer, if the material is not found, they can search through the search option provided by the system and pose the questions regarding concepts which are not understood properly in the forum discussion. Students can sit anywhere and does the above activities through online. They can write exams at anywhere and submit their answers through online. The system provides group communities creation (technological, programming, etc) and discuss about that community current issues.
3. ‘Transliteration process’—client or student will enter into the system and select the preferred document. If he or she does not understood properly then select the transliteration process for studying in his preferred or native language so that they can clearly understood what the concept is.
4. Transliteration Process using Word Compression and Generation
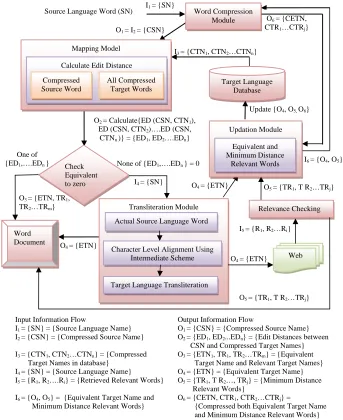
Transliteration is the process of transforming a word written in a source language into a word in a target language. The complete process for transliteration from source word to target word is described in Fig 2. This process uses both compression and generation methods. This process mainly contains with the following modules: Word Compression, Mapping, Transliteration, Web Retrieval and Updation. The working principle of individual modules can be described in the following paragraphs.
4.1.Word compression module
For a given source language word (SN), this module compress as it into a minimum consonant skeleton form or CWF form based on a set of linguistic rules. Linguistic rules are an ordered set of, combination of rewrite and remove rules as specified in (Bilac and Tanaka, 2004). The output of this module is named as compressed source language word (CSN). The target language words {TN1, TN2…TNn} in the database are compressed in the same manner by using the linguistic rules, but their rule sets are different. Target language database index is in the form of tuples, where each tuple contains both compressed word and actual word.
Fig 1 E-Learning System using Transliteration User/
Client
E-learning System
E-learning Home
Forum Discussion
Search Process
Important Documents
Collection
Group Communities Online
Discussion Course
Details
Exams
Choose Preferred Document
Transliteration Process
Receive Document and Target Language Document Division and
Alignment
Divide Document into Words
Dividing Each Word into Characters
Character Level Alignment
Target word Generation
Mapping Intermediate Target Scheme
Generate Individual Target Characters
Generate Entire Target Name
Document Transliteration
Each Target Word Generation
4.2.Mapping model
This model receives CSN as input and searches all compressed target words {CTN1, CTN2…CTNn} from the database index using indexing (clustered indexing) method. It converts CSN and {CTN1, CTN2…CTNn} into intermediate scheme for finding exact equivalent compressed target name (CETN). Intermediate scheme acts as a mediator for mapping between source and target languages because both have different character representations. Roman scheme is the intermediate scheme developed for mapping or aligning characters between source and target languages. A scheme having one-to-one configuration is used here for mapping between CSN and {CTN1, CTN2…CTNn}.
Calculate{ED (CSN, CTN1), (ED (CSN, CTN2)… (CSN, CTNn)} = {ED1, ED2…EDn}
The model then calculates edit distance between compressed source word and each compressed target words {ED (CSN, CTN1), (ED (CSN, CTN2)… (CSN, CTNn)}. Modified Levenshtein algorithm is used for finding edit distances between CSN and {CSN1, CSN2…CSNn} as described in the paper [10]. Levensthtein edit distance is normally used for finding number of changes, between two strings of same language and contains insertion, deletion or substitution of a single character [14]. Here, it is used for finding the changes between two different language strings. After finding {ED1, ED2…EDn}, each edit distance is checked with
Fig 2 Transliteration Process using Compression and Generation Input Information Flow
I1 = {SN} = {Source Language Name} I2 = {CSN} = {Compressed Source Name}
I3 = {CTN1, CTN2…CTNn} = {Compressed Target Names in database}
I4 = {SN} = {Source Language Name} I5 = {R1, R2….Ri} = {Retrieved Relevant Words}
I6 = {O4, O5} = {Equivalent Target Name and Minimum Distance Relevant Words}
Output Information Flow
O1 = {CSN} = {Compressed Source Name} O2 = {ED1, ED2...EDn} = {Edit Distances between
CSN and Compressed Target Names} O3 = {ETN1, TR1, TR2…TRm} = {Equivalent
Target Name and Relevant Target Names} O4 = {ETN} = {Equivalent Target Name} O5 = {TR1, T R2…, TRj} = {Minimum Distance Relevant Words}
O6 = {CETN, CTR1, CTR2…CTRj} =
{Compressed both Equivalent Target Name and Minimum Distance Relevant Words}
I5 = {R1, R2…Ri} Source Language Word (SN)
O2 = Calculate{ED (CSN, CTN1), ED (CSN, CTN2)….ED (CSN,
CTNn )} = {ED1, ED2….EDn}
I6 = {O4, O5}
O5 = {TR1, T R2…TRj}
O4 = {ETN} Web I3 = {CTN1, CTN2…CTNn}
I1 = {SN}
O1 = I2 = {CSN}
O4 = {ETN}
O4 = {ETN}
O5 = {TR1, T R2…TRj} Update {O4, O5, O6}
I4 = {SN}
O6 = {CETN, CTR1…CTRj}
One of
{ED1,….EDn } None of {ED1,….EDn } = 0
O3 = {ETN, TR1, TR2…TRm} Word Document Check Equivalent to zero Mapping Model
Calculate Edit Distance
Compressed Source Word All Compressed Target Words Word Compression Module Target Language Database Relevance Checking Updation Module Equivalent and Minimum Distance Relevant Words Transliteration Module
Actual Source Language Word
Character Level Alignment Using Intermediate Scheme
equivalent to zero for finding exact target equivalent. If one of {ED1, ED2…EDn} is equivalent to zero, then CETN is found. Therefore, the corresponding actual target word (ETN) and relevant actual target words {TR1, TR2….TRm} are retrieved from the database based on the minimum edit distance value. Finally ETN and {TR1, TR2….TRm} are stored in a word document file. When there is more than one candidate at the same edit distance, finer ranking can be made based on the edit distance between the actual forms of source and target strings. There is no chance for two candidates having zero edit distance, because one string can have only one equivalent not more than one. Suppose none of {ED1, ED2…EDn} is equivalent to zero, exact ETN is not found and there is a need to transliterate SN for ETN. Only, relevant words can be retrieved based on the minimum edit distance, but not the required ETN.
4.3.Transliteration module
It generates or transliterates source language word into target language word which is not having ETN in the target language database index. Transliteration is done on the SN, not on the CSN. This work used the major technique of transliteration called grapheme based model, where transliterations are generated using character level alignments between source and target languages. Intermediate scheme is used to align the characters between source and target languages. The roman scheme is used as intermediate scheme for transliteration. Mapping is done with either one-to-many and one-to-one configuration or many-to-one and one-to-one configuration, which is because of given source word is in SN not in the CSN. The selection of the configuration depends on source and target languages. The output of transliteration module is the generation of ETN, which is not found in the database index. Finally, the generated ETN is stored in a word document file for compressing and updating the database.
4.4.Web Retrieval module
It is mainly designed for searching the relevant target words {R1, R2…Ri} from the web for the generated ETN. After retrieving {R1, R2…Ri}, they are stored in a file. Edit distances are calculated between SN and {R1, R2…Ri} for relevance checking. The words which have less or minimum edit distance are taken as relevant to the source word. The words that have minimum distance {TR1, TR2…TRj} are stored in the same word document file as it contains generated ETN. These words {ETN, TR1, TR2…TRj} are given to the Word Compression Module to compress into CWF by using a set of linguistic rules. These compressed words {CETN, CTR1, CTR2…CTRj} and their actual words ETN, TR1, TR2…TRj} are stored in a separate document file.
4.5.Updation module
It is mainly designed for updating the database with the generated ETN and retrieved target words from the web which has good relevance {TR1, TR2…TRj}, so that they need not transliterate and search again. This module updates {CETN, CTR1, CTR2…CTRj} and {ETN, TR1, TR2…TRj} in the form of tuples that contains compressed word with the actual name. The processing time of Transliteration Module and Web Retrieval Module has been reduced, when already specified source word is given again for transliteration.
The final result contains both right equivalent matching target word (ETN) and relevant equivalent target words. These are stored in the word document file as shown in Fig 2.
Input:
Input1 Source Language Word-1 (SN1) Input2 Source Language Word-2 (SN2)
Output1: ETN Found in database
Equivalent Target Word (ETN) Target Relevant Word-1 (TR1)
Output2: ETN not found in database
Equivalent Target Word (ETN) Target Relevant Word-1(TR1)
Target Relevant Word-j (TRj)
5. Evaluation of the System
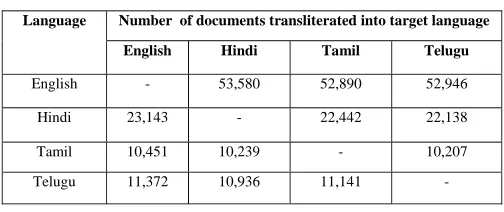
The performance of the system depends on the total execution time. The system is fast and all users can access at a time and do their operations. Users can share their knowledge with other users, pose questions in the forum and get the replies on time or over a period of time. The time taken to transliterate into the user preferred language depends on the length of the document. The system is tested on English, Hindi, Tamil and Telugu language documents. To test the system for the transliteration collected 1,00,216 documents. The documents are collected over a period of six to seven months. The collection of the documents according to the language is given below Table 1.
Table 1. Documents Collection
The documents all specified above are in word format (only word (.doc) documents). The collected documents are tested in the above languages. i.e. English language documents are tested with all other three languages (Hindi, Tamil, and Telugu). Other language documents are tested in the same fashion. For most of the documents the system is transliterated properly, because most of the collected documents support UTF-8 encoding format [7]. With the collected documents, the system is tested and accuracy is measured. The number of documents transliterated into the target language is given in Table 2. The performance measure for the proposed e-learning system is shown in Table 3. The system is accurate for the tested languages. All the documents are not transliterated into the corresponding target language, because the documents which are not transliterated are very old and the format is undecided.
Table 2. Documents Transliterated into Target Language
Language Number of documents transliterated into target language
English Hindi Tamil Telugu
English - 53,580 52,890 52,946
Hindi 23,143 - 22,442 22,138
Tamil 10,451 10,239 - 10,207
Telugu 11,372 10,936 11,141 -
Table 3. E-learning System Performance using Accuracy Measure
Language Accuracy
English Hindi Tamil Telugu
English - 98.62% 97.35% 97.46%
Hindi 98.57% - 95.58% 94.29%
Tamil 97.10% 95.13% - 94.83%
Telugu 97.61% 93.87% 95.63% -
Language English Hindi Tamil Telugu
6. Conclusion and Future Work
E-learning is the delivery of a learning, training or education program by electronic means. It is the emerging area in the current research field. As the technology improving every day, this made a lot of challenges in the e-learning. The main challenge is make the system as simple as possible to the users and learn the e-content as quickly as possible. An e-learning system with transliteration is proposed in the paper. The system is purely useful to those who cannot read and write the language, but they can understand the language. This type of system makes the users to study the documents in their preferred languages.
The system is having the following drawbacks. It is not two way process. i.e. if the student have any doubts, to clarify he or she should pose the questions in the transliterated language, there is no faculty provided to answer the transliterated language question posed by the student. The system is evaluated only with word (.doc) documents because it supports word documents only. It could not support other format documents like power point presentations (.ppt) and acrobat reader documents (.pdf) formats.
The current work can be extended to adding other languages to the proposed system and make the system to support for other format documents also. In future, we may try to automate the process. i.e. the documents which are uploaded will be transliterated without human intervention. As we developed the system using transliteration, in future planned to introduce translation of the uploaded documents in required languages.
References
[1] Bates, A. and Poole, G. (2003). Effective teaching with technology in higher education San Francisco. Jossey Bass/John Wiley. [2] Bilac, S. and Tanaka, H. (2003). Improving back-transliteration by combining information sources. In Proceedings of IJC-NLP, pp.
542–547.
[3] Bilac, S. and Tanaka, H. (2004). A hybrid back-transliteration system for Japanese. In: Proc. Of the 20th International Conference on Computational Linguistics (COLING 2004), pp. 597–603.
[4] Blackboard Inc. (2002). Blackboard Course Management System, Blackboard Inc., available online at http://www.blackboard.com/ [5] Brusilovsky, P. and Miller, P. (2001). Course delivery systems for the virtual university. In: Tschang, T. and Della Senta,T. (eds.):
Access to Knowledge: New Information Technologies and the Emergence of the Virtual University. Elsevier Science, Amsterdam, 167-206.
[6] Dublin, L. (2003). If you only look under the street lamps or nine e-learning myths. The eLearning Developers' Journal, 1-7,2003. [7] Durst, M. J. (1997). The properties and promizes of UTF-8. In Proceedings of 11th International Conference on Unicode, available
online at http://www.ifi.unizh.ch/staff/mduerst/
[8] Ganesh, S., Harsha, S., Prasad, P., and Varma, V. (2008). Statistical transliteration for cross language information retrieval using HMM aligment and CRF. In Proceedings of International Joint Conference on Natural Language Processing(IJCNLP).
[9] Hoppe, G. and Breitner, M. H. (2004). Business models for e-learning. Subconference on E-Learning: Models, Instruments, Experiences of the Multikonferenz Wirtschaftsinformatik 2004 in Essan, German
[10] Janarthanam, S. C., Sethuramalingam, S., and Nallasamy, U. (2008). Named entity transliteration for cross-language information retrieval using compressed word format mapping algorithm. In Proceedings of 2nd International ACM Workshop on Improving Non-English Web Searching (iNEWS08), CIKM.
[11] Jurafsky, D. and Martin, J. H. (2007). Speech and Language processing: An introduction to natural language processing. Computational Linguistics and Speech Recognition.
[12] Karrer, T. (2008). Corporate long tail learning and attention crisis. http://Elearningtech.blogspot.com
[13] Kerkman, L. (2004). Convenience of online education attracts midcareer students. Chronicle of Philanthropy. 16(6), 11-12. Retrieved from Academic Search Premier database.
[14] Levenshtein, V. I. (1996). Binary codes capable of correcting deletions, insertions and reversals. Sov. Phys. Dokl., vol. 6, pp. 707-710. [15] Li, H., Sim, K. C., Kuo, J. S. and Dong, M. (2007). Semantic transliteration of person names. In proceedings of the 45th Annual
Meeting of the Association of Computational Linguistics, pp. 720-727.
[16] Malik. M. G. A. (2006). Punjabi machine transliteration. In Proceedings of the 21st International Conference on Computational Linguistics and the 44th annual meeting of the ACL, pp. 1137–1144.
[17] Nagy, A. (2005). The Impact of E-Learning in: Bruck, P.A.; Buchholz, A.; Karssen, Z.; Zerfass, A. (Eds). E-Content: Technologies and Perspectives for the European Market. Berlin: Springer-Verlag, pp.79-96, 2005.
[18] OECD. (2005). E-Learning in Tertiary Education: Where Do We Stand? Paris: OECD
[19] Oh, J. H. and Choi, K. S. (2006). An ensemble of transliteration models for information retrieval. Information Processing and Management: an International Journal, v.42 n.4, pp. 980-1002, July 2006.
[20] Rama, T. and Gali, K. (2009). Modeling machine transliteration as a phrase based stastistical machine translation problem. In proceedings of the Named Entities Workshop, ACL–IJCNLP’09, pp. 124-127.
[21] Rossett, A. and Sheldon, K. (2001). Beyond The Podium: Delivering Training and Performance to a Digital World. San Francisco: Jossey-Bass/Pfeiffer, pp: 274.