DOI :
https://doi.org/10.32628/CSEIT11953130
Differential Study of Deep Network Based Image Retrieval Methods
Arpana Mahajan1, Dr. Sanjay Chaudhary2
1Research Scholar, Department of Computer Engineering, Madhav University, Rajasthan, India
2Research Supervisor, Department of Computer Engineering, Madhav University, Rajasthan, India
ABSTRACT
Learning successful component portrayals and likeness measures are essential to the recovery execution of a substance based image recovery (CBIR) framework. In spite of broad research endeavors for quite a long time, it stays one of the most testing open issues that extensively thwarts the accomplishments of genuine world CBIR frameworks. The key test has been ascribed to the outstanding “semantic hole” issue that exists between low -level image pixels caught by machines and elevated -level semantic ideas saw by a human. Among different methods, AI has been effectively examined as a conceivable course to connect the semantic hole in the long haul. Propelled by late triumphs of profound learning strategies for PC vision and different applications, in this paper, we endeavor to address an open issue: if profound learning is a desire for spanning the semantic hole in CBIR and how much upgrades in CBIR undertakings can be accomplished by investigating the cutting edge profound learning procedures for learning highlight portrayals and comparability measures. In particular, we research a structure of profound learning with application to CBIR assignments with a broad arrangement of exact investigations by inspecting cutting edge profound learning strategies for CBIR undertakings under shifted settings. From our experimental investigations, we locate some promising outcomes and abridge some significant bits of knowledge for future research.
Keywords : Image Retrieval, CNN, Alexnet, RCNN, RESNET, GoogleNet.
I. INTRODUCTION
Image recovery is the way toward recovering images applicable to a question from huge database frameworks. The fast development in web and web-based social networking stages like Flickr, Instagram, and so forth has brought about the gigantic development of images accessible on the web. Consequently, to get images of intrigue, image recovery frameworks assume a significant job. This is a difficult issue as the framework ought to comprehend the subcomponents of an image and comprehend the total setting of the image. A perfect image recovery framework should show images that are increasingly pertinent to the inquiry. Image recovery by a printed question is being utilized in the
vast majority of the image search frameworks. The inquiry of images utilizing a printed question principally relies upon metadata of images. Images with metadata like the printed inquiry are shown as results. The abovementioned approach depends on people to comment on images. Wanted outcomes probably won't be gotten if there is a blunder in human comments of metadata or if the metadata doesn't characterize the setting behind a image.
Research in picture recovery by picture subtitling has expanded because of the progression in neural systems and preparing power as of late. Subtitles are generally produced utilizing profound learning by utilizing Convolutional Neural Networks (CNN) to identify highlights from pictures and Recurrent Neural Networks (RNN) to create inscriptions for the recognized highlights. This writing study and task centers around investigating different procedures utilized in picture recovery inquire about.
II. RELATED WORKS
Earlier, the retrieval of content and images has been founded on physically made lists put away as back of the book lists or card records. Most libraries, image files, and video files still utilize these files. In the most recent decades, systems have been created to consequently record huge volumes of content and a portion of these strategies are likewise used to list images based on related content (setting based image retrieval). In the most recent years, image preparing systems have been built up that permit the ordering of images dependent on their visual substance (content-based image retrieval). This area depicts these two distinct ways to deal with image retrieval. In the following subsections, the essential techniques and issues of separately setting based image retrieval and substance based image retrieval will be examined.
Done low-level dream What's more PC illustrations, for understanding mostly Differential Equations (PDEs), those for the most part used Multigrid method [3] reformulates that system as sub-issues toward different scales, the spot each sub-issue is liable for the rest of the outcome the center of A coarser Furthermore A better scale. An elective ought to Multigrid might be dynamic help preconditioning [14, 15], which depends around factors that representable residual vectors the center of two scales. It should be been demonstrated [3, 14, 15] that these solvers satisfy significantly speedier over guideline solvers that need help oblivious of the
waiting idea of the outcomes. These frameworks suggest that an extraordinary reformulation or preconditioning camwood improve the streamlining.
Backup course of action affiliations. Cleans Also speculations that brief backup way to go affiliations have been examined for a long time. A speedily demonstration about readiness multi-layer perceptron's (MLPs) might be on incorporate a straight layer got beginning together with those sort out data of the yield [6, 16]. Secured nearby [16], several middle layers are direct connected with collaborator classifiers for having a tendency to disappear/detonating angles. The current schedules to centering layer reactions, slopes, besides engendered blunders, executed Eventually Tom's examining backup course of action affiliations. Secured close by [13], an "initiation" layer might be made of a backup course of action expansion and several more profound augmentations.
Synchronous with our work, "roadway systems" accessible backup course of action relationship with gating limits [15]. These gateways need help information subordinate Also need parameters, as contradicted will our character alternate ways that need help sans parameter. At the point when a gated backup way to go will be "shut" (moving toward zero), those layers secured nearby roadway systems representable non-leftover limits. Despite what might be expected, our itemizing reliably takes in residual capacities; our character card easy routes are rarely shut, Furthermore at information is constantly gone through, with additional waiting attempts to an opportunity to be made sense of how.
III.DIFFERENT APPROACH CNN
The subsequent part comprises of the completely associated layer which performs non-straight changes of the removed highlights and goes about as the classifier.
Fig 2. CNN Architechture
In the above chart, the information is encouraged to the system of stacked Conv, Pool, and Dense layers. The yield can be a softmax layer showing whether there is a feline or something different. You can likewise have a sigmoid layer to give you a likelihood of the picture being a feline. Give us a chance to see the two layers in detail.
ALEXNET
AlexNet is the name of a convolutional neural system that has largely affected the field of AI, explicitly in the use of profound figuring out how to machine vision. It broadly won the 2012 ImageNet LSVRC-2012 challenge by a huge edge (15.3% VS 26.2% (second spot) blunder rates). The system had fundamentally the same as engineering as LeNet by Yann LeCun et al, however, it was more profound, with more channels per layer, and with stacked convolutional layers. It comprised of 11×11, 5×5,3×3, convolutions, max pooling, dropout, information expansion, ReLU initiations, SGD with energy. It joined ReLU actuations after each convolutional and completely associated layer. AlexNet was prepared for 6 days all the while on two Nvidia Geforce GTX 580 GPUs which is the purpose behind why their system is part of two pipelines.
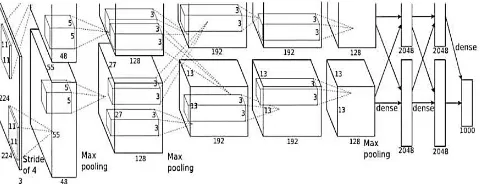
Fig 3. Alexnet Architechture
The design portrayed in Figure, the AlexNet contains eight layers with loads; the initial five are convolutional and the staying three are completely associated. The yield of the last completely associated layer is encouraged to a 1000-way softmax which delivers a dispersion over the 1000 class marks. The system boosts the multinomial strategic relapse objective, which is identical to augmenting the normal crosswise over-preparing instances of the log-likelihood of the right mark under the expectation appropriation. The parts of the second, fourth, and fifth convolutional layers are associated uniquely to those portion maps in the past layer which dwell on the equivalent GPU. The portions of the third convolutional layer are associated with all part maps in the subsequent layer. The neurons in the completely associated layers are associated with all neurons in the past layer.
To put it plainly, AlexNet contains 5 convolutional layers and 3 completely associated layers. Relu is applied after a very convolutional and completely associated layer. Dropout is applied before the first and the second completely associated year. The system has 62.3 million parameters and necessities 1.1 billion calculation units in a forward pass. We can likewise observe convolution layers, which records for 6% of the considerable number of parameters, devours 95% of the calculation.
RCNN
(R-CNN), consolidates rectangular locale proposition with convolutional neural system highlights. R-CNN is a two-organize recognition calculation. The main stage distinguishes a subset of areas in a picture that may contain an article. The subsequent stage orders the article in every district.
Fig 4. R-cnn learning
Models for object location utilizing areas with CNNs depend on the accompanying three procedures: 1. Discover areas in the picture that may contain an item. These districts are called area proposition. 2. Concentrate CNN highlights from the locale proposition.
3. Order the items utilizing the separated highlights. There are three variations of an R-CNN. Every variation endeavors to enhance, accelerate, or improve the consequences of at least one of these procedures.
RESNET
Profound convolutional neural systems have accomplished the human level picture characterization result. Profound systems concentrate low, center and elevated level highlights and classifiers in a start to finish multi-layer design, and the number of stacked layers can improve the "levels" of highlights.
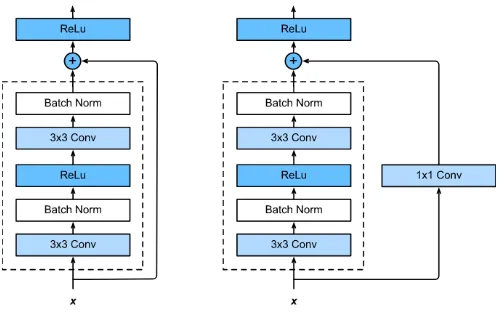
Fig 5. Bbuilding block of Residual learning
At the point when the more profound system begins to merge, a corruption issue has been uncovered: with the system profundity expanding, precision gets soaked (which may be obvious) and afterward debases quickly. Such debasement isn't brought about by overfitting or by adding more layers to a profound system prompts higher preparing mistake. The crumbling of preparing precision shows that not all frameworks are anything but difficult to improve.
To defeat this issue, Microsoft presented a profound leftover learning system. Rather than trusting each few stacked layers legitimately fit an ideal hidden mapping, they expressly let these layers fit a lingering mapping. The detailing of F(x)+x can be acknowledged by feedforward neural systems with alternate route associations. Alternate route associations are those skirting at least one layers appeared in Figure 1. The easy route associations perform personality mapping, and their yields are added to the yields of the stacked layers. By utilizing the lingering system, there are numerous issues which can be unraveled.
ResNets are anything but difficult to improve, however the "plain" organizes (that essentially stack layers) shows higher preparing blunder when the profundity increments.
GoogleNet
GoogLeNet utilizes a heap of a sum of 9 commencement squares and worldwide normal pooling to produce its appraisals. Most extreme pooling between beginning squares diminished the dimensionality. The initial segment is indistinguishable from AlexNet and LeNet, the pile of squares is acquired from VGG and the worldwide normal pooling maintains a strategic distance from a heap of completely associated layers toward the end. The design is delineated beneath.
Fig 6. GoogleNet
Comparative Study
Fig 7. Comparative graph
IV.CONCLUSION
Image retrieval has turned into a significant issue as of late because of the exponential development of images via web-based networking media and the web. This paper talks about the different research in the profound systems utilized previously and it additionally features the different procedures and philosophies utilized in the examination. Among them, RESNET gives player execution with time and precision parameters. Along these lines, this examination can be additionally upgraded later on to improve the recognizable proof of classes which has a lower accuracy via preparing it with more image inscribing datasets. This strategy can likewise be joined with a past image retrieval techniques setting and substance-based methodology.
V. REFERENCES
[1]. Available at: http://wn-
similarity.sourceforge.net/ [Accessed on 15 may 2017].
[2]. C.-Y. Lee, S. Xie, P. Gallagher, Z. Zhang, and Z. Tu. Deeplysupervised nets. arXiv:1409.5185, 2014.
[4]. Dong-Chul Park, “Image Classification Using Naïve Bayes Classifier”, in International Journal of Computer Science and Electronics Engineering, vol. 4 , pp. 135-139, 2016
[5]. Finlayson and Mark Alan “Java Libraries for Accessing the Princeton Wordnet: Comparison and Evaluation” in Proceedings of the 7th International Global WordNet Conference, 2014, pp. 78-85 .
[6]. G. Mont´ufar, R. Pascanu, K. Cho, and Y. Bengio. On the number of linear regions of deep neural networks. In NIPS, 2014.
[7]. I. J. Goodfellow, D. Warde-Farley, M. Mirza, A. Courville, and Y. Bengio. Maxout networks. evaluation of recent feature encoding methods. In BMVC, 2011.
[10]. K. He and J. Sun. Convolutional neural networks at constrained time cost. In CVPR, 2015.
[11]. K. He, X. Zhang, S. Ren, and J. Sun. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In ICCV, 2015.
[12]. K. Simonyan and A. Zisserman. Very deep convolutional networks for large-scale image recognition. In ICLR, 2015.
[13]. M. D. Zeiler and R. Fergus. Visualizing and understanding convolutional neural networks. In ECCV, 2014.
[14]. M. Everingham, L. Van Gool, C. K. Williams, J. Winn, and A. Zisserman. The Pascal Visual Object Classes (VOC) Challenge. IJCV, pages 303–338, 2010.
[15]. MATLAB and Statistics Toolbox Release 2013a, The MathWorks, Inc., Natick, Massachusetts, United States
[16]. R. Girshick, J. Donahue, T. Darrell, and J. Malik. Rich feature hierarchies for accurate object detection and semantic segmentation. In CVPR, 2014.
[17]. R. Girshick. Fast R-CNN. In ICCV, 2015. [18]. R. K. Srivastava, K. Greff, and J. Schmidhuber.
Highway networks. arXiv:1505.00387, 2015. [19]. R. K. Srivastava, K. Greff, and J. Schmidhuber.
Training very deep networks. 1507.06228, 2015.
[20]. T.-Y. Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan, P. Doll´ar, and C. L. Zitnick. Microsoft COCO: Common objects in context. In ECCV. 2014.
[21]. Ted Pedersen, WordNet::Similarity. [Online] [22]. X. Li, T. Uricchio, L. Ballan, M. Bertini, C.
Snoek, and A. Del Bimbo, “Socializing the semantic gap: A comparative survey on image tag assignment, refinement and retrieval,” in ACM Computing Surveys, 2016, in press. [23]. Y. Jia, E. Shelhamer, J. Donahue, S. Karayev, J.
Long, R. Girshick, S. Guadarrama, and T. Darrell. Caffe: Convolutional architecture for fast feature embedding. arXiv:1408.5093, 2014.
Cite this article as :
Arpana Mahajan, Dr. Sanjay Chaudhary, "Differential Study of Deep Network Based Image Retrieval Methods", International Journal of Scientific Research in Computer Science, Engineering and Information Technology (IJSRCSEIT), ISSN : 2456-3307, Volume 5 Issue 2, pp. 1311-1316, March-April 2019.
Available at doi :
https://doi.org/10.32628/CSEIT11953130