A Robust Scalable Spatial Spread-Spectrum
Video Watermarking Scheme Based on a Fast
Downsampling Method
Cheng Wang 1, Shaohui Liu 2, Feng Jiang 3, Yan Liu4
School of Computer Science and Technology, Harbin Institute of Technology, Harbin, 150001, China Email: [email protected]
Abstract—This paper presents a robust spatial
spread-spectrum (SS) video watermarking scheme with adaptive detection for H.264/AVC and SVC. We introduce a fast image size change method in DCT domain to obtain a low-pass and downsized version of the video frame for embedding, which protects the watermarking signal from being damaged by downsampling during SVC encoding. And then we embed watermark bits by SS method with exploiting the Just Noticeable Distortion (JND) model to dynamically adjust the embedding strength. The watermark will be spread to the original video after the upsampling of the embedded downsized version. Furthermore, we deduce a detection model based on a likelihood ratio test to realize adaptive detection and design a different detection strategy for the base layer of SVC-encoded video. Simulation results prove the validity of the detection model and show that the proposed watermarking algorithm has strong robustness against not only H.264/AVC-encoded I-frames, P-frames and B-frames, but also SVC-encoded I-frames and P-frames while preserving the perceptual quality.
Index Terms—fast downsampling, spread-spectrum video
watermarking, JND model
I. INTRODUCTION
Video watermarking has been proposed as a technology for authentication and copyright protection by embedding an imperceptible, yet detectable signal into the video sequence [1]. Currently, the video coding standard H.264/AVC with high compression efficiency and strong network adaptability is utilized in a wide range of applications. And in order to adapt to different network environment and user terminals, the Joint Video Team (JVT) has also standardized a Scalable Video Coding (SVC) extension of the H.264/AVC standard which aims at encoding video in a single bit stream from which multiple spatial and temporal resolutions at different quality levels can be extracted. With the rapid increase of distribution of video content, it is necessary to devise new watermarking schemes for the two standards.
There are two embedding scenarios for video watermarking, embedding in raw data (namely spatial domain watermarking) and embedding in the coding process or directly in the compressed bitstream (namely compressed domain watermarking).
Recently, a few compressed domain watermarking algorithms on H.264/AVC have been proposed. In [2], the authors embed watermark information in the quantized residuals of I-frames and build a theoretical framework for watermark detection based on a likelihood ratio test. The authors in [3]-[4] modify the quantized DC coefficients of each DCT block, while in [3] they propose a drift compensation algorithm and in [4] they implement a blind video watermarking scheme. These compressed domain methods above commonly offer real-time processing of the video, however, they may not survive video format conversion including SVC coding because the watermark is tied to the H.264/AVC standard.
Spatial video watermarking method resistant to H.264/AVC has received continuous attention due to its high capacity, as well as avoiding error drift in the compressed domain. In [5], authors employ the JND model to improve the performance of [6] further, however, simply setting a threshold to detect the watermark causes higher error ratios under larger quantization step. Compared to [5], Huang et al. [7] apply 1D-DCT to temporal domain and use quantization index modulation (QIM) to embed watermark, but it is not robust to some attacks such as scaling and frame deleting.
For watermarking algorithm on SVC, few articles have appeared in the open literature. In [8], the authors propose a watermarking scheme using the Fourier-Mellin transform, but it is no longer robust when image size is scaling from 1920 1080× to 854 480× . The authors in [9] propose a robust compressed domain watermarking scheme for SVC but only focus on inter-layer intra prediction.
watermark detection, we follow the same theoretical framework in [2] and derive a similar detection model. Furthermore, we design a detection strategy for the base layer of SVC- encoded video.
The rest of the paper is organized as follows. In Section II, we briefly review the fast scheme for image size change in [10]. Section III analyses the correctness of our watermarking algorithm theoretically. In Section IV, we describe details about the proposed embedding scheme. In Section V, we present the derived detection model and the detection strategy for the base layer of SVC-encoded video. Simulation results are provided in Section VI followed by conclusion in Section VII.
II.FAST SCHEME FOR IMAGE SIZE CHANGE
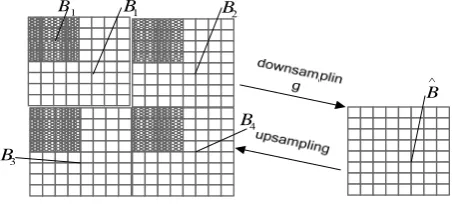
In order to keep the paper self-contained, we describe the fast scheme for image size change in [10] briefly as follow. 1 B ∧ 1 B B ∧ 2 B 3 B 4 B
Figure 1. Macroblock downsampling and upsampling
Let B1 , B2 , B3 and B4 denote the DCTs of four consecutive 8 8× blocks as shown in Fig. 1. Let b1 , b2 , b3 and b4 denote these four adjacent
8 8× blocks in the spatial domain, respectively. Let
1 B
∧
,B2
∧
,B3
∧
andB4
∧
denote the 4 4× matrices containing the low-pass coefficients of B1 , B2 , B3 and B4 ,
respectively. Letb1
∧
,b2
∧
,b3
∧
and b4
∧
denote the4 4× inverse DCT of B1
∧
, B2
∧
, B3
∧
and B4
∧
respectively.
Then 1 2
3 4
def b b
b b b ∧ ∧ ∧ ∧ ∧ ⎡ ⎤ ⎢ ⎥ =⎢ ⎥ ⎢ ⎥ ⎣ ⎦
denotes the low-pass and
downsampled version of 1 2 3 4
def b b
b
b b
⎡ ⎤
= ⎢ ⎥
⎣ ⎦. Let ( )
def B DCT b
∧ ∧
= .
Let T8 denote the 8-point DCT operator matrix and let T4 denote the 4-point operator matrix. Let TLandTRdenote the first and last four columns of T8,respectively. Our goal is to obtain B
∧
directly fromB1
∧
, B2
∧
, B3
∧
andB4
∧ . We have
[
]
[
]
1 2 8 8 3 44 1 4 4 2 4
4 3 4 4 4 4
4 1 4 4 2 4
4 3 4 4 4 4
( ) ( ) ( ) ( )
( ) ( ) ( ) ( )
t
t L
L R t
R
t t t
L
L R t
t t R
t t t t t
L L L R
t t t t t
R L R R
b b T
B T bT T T
T b b
T B T T B T T T T
T T B T T B T T T B T T T T B T T
T T B T T T T B T T ∧ ∧ ∧ ∧ ∧ ∧ ∧ ∧ ∧ ∧ ∧ ∧ ∧ ∧ ⎡ ⎤ ⎡ ⎤ ⎢ ⎥ = = ⎢ ⎢ ⎥ ⎥ ⎣ ⎦ ⎢ ⎥ ⎣ ⎦ ⎡ ⎤ ⎡ ⎤ ⎢ ⎥ = ⎢ ⎥ ⎢ ⎥ ⎣ ⎦ ⎢ ⎥ ⎣ ⎦ = + + + (1)
Finally we have
( ) t ( ) t
B X Y C X Y D ∧
= + + − (2)
It should be noted that the matrices C and D in equations (3) are very sparse and can be computed in advance.
1 3 1 3 4
2 4 2 4 4
( ) ( ); ( ) ( ); t L t R
X C B B D B B T T C D Y C B B D B B T T C D
∧ ∧ ∧ ∧
∧ ∧ ∧ ∧
= + + − = +
= + + − = −
(3)
During the upsampling, givenB ∧
, we have
1 4 4 2 4 4
3 4 4 4 4 4
( ) ( ); ( ) ( )
( ) ( ); ( ) ( )
t t t t t t
L L L R
t t t t t t
R L R R
B T T B T T B T T B T T B T T B T T B T T B T T
∧ ∧ ∧ ∧
∧ ∧ ∧ ∧
= =
= =
(4)
In the next section, the correctness of our watermarking algorithm based on this fast size change scheme is proved.
III.CORRECTNESS OF THE WATERMARKING
ALGORITHM
Suppose we add a watermarkW to B ∧
, due to the linearity property of the DCT, the equation is easily derived from (1) as follows:
[
]
[
]
4 1 1 4 4 2 2 4
4 3 3 4 4 4 4 4
4 1 4 4 2 4
4 3 4 4 4 4
( ) ( )
( ) ( )
t t t
L
L R t
t t R
t t t
w w L
L R t
t t R
w w
T B W T T B W T T B W T T
T T B W T T B W T T B T T B T T T T
T T B T T B T
∧ ∧ ∧ ∧ ∧ ∧ ∧ ∧ ∧ ⎡ + + ⎤ ⎡ ⎤ ⎢ ⎥ + = ⎢ ⎢ ⎥ ⎥ ⎣ ⎦ + + ⎢ ⎥ ⎣ ⎦ ⎡ ⎤ ⎡ ⎤ ⎢ ⎥ = ⎢ ⎢ ⎥ ⎥ ⎣ ⎦ ⎢ ⎥ ⎣ ⎦ (5)
where W ii( ∈{1, 2, 3, 4}) denotes the change of Bi ∧
(i∈{1, 2, 3, 4}) caused by embedding and Bwi ∧
is defined
as ( {1, 2, 3, 4}) def
wi i i
B B W i
∧ ∧
= + ∈ .
While observing (5) from right to left, we can obtain
B W ∧
+ for detection through downsampling by collecting
wi B
∧
from the DCT blocks of the watermarked video frame. Equation (5) forms the basis of our proposed algorithm for watermark embedding and extraction.
IV. WATERMARK EMBEDDING
In this section we describe the embedding scheme in details and present several optional methods to get a low-pass and downsampled version of a video frame. We use a bipolar watermark W∈ −{ 1,1}with zero mean and variance one.
Watermarking embedding procedure is described as follows:
1. Partition the luminance component into 8×8 blocks and then apply 2D-DCT to each block;
2. Compute the JND value for every coefficient in the top left 4 4× corner of each block using the JND model described in [11];
3. Implement the downsampling procedure for each
16 16× macroblock MBl to obtain Bl ∧
. The corresponding JND values go through the same
process to obtainJl ∧
;
4. Select the location ( , )j k inBl ∧
to embed watermark with SS method. The process can be described as:
( , ) ( , ) l( , )
l l l
B j k B j k αJ j k W
∧ ∧ ∧
= + (6) where αis the global parameter for watermark, which will be set to 1 in our experiments and Wlis the lth watermark bit;
5. Solve (4) to obtain Bl1 ∧
, Bl2 ∧
, Bl3 ∧
and Bl4 ∧
and then replace the top left 4 4× corner of corresponding blocks inMBl;
6. Apply 2D-IDCT to each block to get the watermarked frame.
Note that, the corresponding JND values go through the same downsampling process in step 3, which ensures that the change of original video frame caused by embedding in the downsampled video frame would not be perceived by Human Visual System (HVS). In step 4,
we find that the first four AC coefficients of Bl ∧
are suitable for embedding in order to achieve good robustness. The selection of embedding position can be controlled by private key to enhance the security of watermark information.
There are several optional methods to obtain the low-pass version of a video frame. We can use the top
left2 2× corner of each block asBlx(x {1, 2, 3, 4})
∧
∈ in step
2 to get a 4 4× matrixBl ∧
as the low-pass version ofMBi. And if we only use the top left 1 1× corner of each block (i.e. the DC coefficient) as Blx(x {1, 2, 3, 4})
∧
∈ , our
embedding scheme is similar to [5]. Note that matricesCandDneed to be recalculated.
V. WATERMARK DETECTION
Watermark detection can be formulated as a hypothesis test to choose between
0: l l( , ) 1: l l( , ) l l( , ) H Y B j k H Y B j k W J j k
∧ ∧ ∧
= , = + (7)
where B j kl( , )
∧
is the selected DCT coefficient
ofBl ∧
,Jl( , )j k
∧
is the corresponding JND value, and Wlis the watermark bit.
Here we adapt a theoretical framework built in [2] for watermark detection. Assume that the ac coefficients of the DCT has a generalized Gaussian distribution, which can be written as
| ( )|
( ) c
l
b X m Y
p X =ae− − (8)
where aand b are defined as
1 2 ( )
bc a
c =
Γ
3 ( ) 1
1 ( )
c b
c σ
Γ =
Γ (9)
and Γ(.) is the gamma function, σ is the standard deviation of the DCT coefficients.
The optimal detector compares the likelihood ratio to a threshold
1
1
0
0
| 1
| 0
( | ) ( | ) H Y H
Y H
H
p Y H
p Y H η
>
< (10)
where ηcontrols the tradeoff between missed detections and false alarms.
Assume that the watermarked DCT coefficients are statistically independent, substitute the joint probability density into (10) to get
1
0
| ( ( , ))|
1
| |
1
c
l l l
c l
N H
b Y W J j k l
N bY
H l
ae
ae
η
∧
− − =
− =
Π >
<
Π (11)
whereNis the number of selected DCT coefficients from the video.
Algebraic simplification reduces this to equivalent test
1
0
2 2
2
1
1 ln ( ) ( , )
3 2
2 ( )
H c
N
l l l l
H
N J c
Y Y W J j k
c
σ η
∧
=
Γ >
= +
< Γ
where 2 2 1
1 N l( , ) l
J J j k
N ∧
=
=
∑
.Till now, we derived a detection model similar with [2], in order to lower the complexity of watermark detection, we set η=1 (i.e. PD+Pf =1, where PD denotes the probability of a detection and PFdenotes the probability of a false alarm) and have
1
0
2
1
( , ) 2 H N
l l l l
H N J Y Y W J j k
∧
=
> =
<
∑
(13)In our experiments, we employ (13) to detect watermark in H.264/AVC-encoded video and the enhancement layer of H.264/SVC-encoded video. When we extend the detection model to the base layer of
H.264/SVC-encoded video, in order to get Jl ∧
, we
implement the upsampling procedure for each Bl ∧
to obtainMBlwhose four corresponding blocks are defined
as def
lx lx
B O B
O O ∧
⎡ ⎤
= ⎢ ⎥
⎢ ⎥
⎣ ⎦
, where Blx(x {1, 2, 3, 4})
∧
∈ are obtained
by solving (4) andOdenotes a 4 4× zero matrix. Note that computing Jl
∧
from received video sequence is not exactly accurate because of the lossy encoding and watermark embedding process. Watermarking detection procedure is described as follows:
1. Partition the luminance component into 8×8 blocks and then apply 2D-DCT to each block;
2. If the frame is H.264/AVC-encoded or SVC-encoded enhancement layer, go to step 4; If the frame is SVC-encoded base layer, go to step 3;
3. Implement the upsampling procedure by solving (4)
for eachBl ∧
to obtainMBl; Go to step 5;
4. Implement the downsampling procedure for each
16 16× macroblockMBlto obtainBl ∧
; Go to step 5; 5. Compute the JND value for every coefficient in the top
left 4 4× corner of MBl using the JND model described in [11];
6. Compute Jl ∧
by the corresponding JND values going through the downsampling process;
7. Use (13) to determine whether the watermark signal exists.
In the next section, we will give the experimental results and compare it with another similar algorithm published in [5].
VI. SIMULATION RESULTS
The proposed watermarking algorithm is implemented in the H.264/AVC reference software version JM10.0 and the SVC reference software version 9.19.10. The first 100 frames of four standard video sequences (CITY, CREW, HARBOUR, SOCCER) in 4CIF format ( 704 576× ) are used in our experiments. We opt for always selecting the
second 8 8× DCT AC coefficient of Bl ∧
in zig-zag order as the embedding location.
TABLEI
PERFORMANCE OF H.264/AVC COMPRESSION WITH ALL I-FRAMES
Sequence Payload PSNR QP20 QP24 QP28 QP32
D
P PF PD PF PD PF PD PF
CITY 1584bits 43.9dB >0.999 0.010 >0.999 0.010 >0.999 0.012 >0.999 0.014 CREW 1584bits 47.5dB >0.999 0.016 >0.999 0.015 >0.999 0.018 0.998 0.020 HARBOUR 1584bits 42.0dB >0.999 0.020 >0.999 0.021 >0.999 0.028 >0.999 0.028 SOCCER 1584bits 43.8dB >0.999 0.022 0.999 0.023 0.998 0.025 0.997 0.025
Four different experiments are conducted. In the first experiment, we validate the robustness of the watermarking method against H.264/AVC compression with each watermarked and unwatermarked video sequence of all I-frames. We test 10 randomly generated watermark messages to obtain an estimate of the error rates (shown in TABLE I). In the second experiment, we compare the detection performance of our scheme with the algorithm in [5]. Fig. 2 shows the watermark detection performance for the CITY and HARBOUR sequences underQP=32. All the cases have the same structure of the group picture (GOP) with IBBPBB. We can see that simply setting a threshold is no longer valid
III). The detection results of the enhancement layer not listed here are slightly different from the first experiment. Note that the probability of false alarmPFis decreased in the base layer. For the detection of all I-frames, our algorithm works as well as that in [9] which only embeds watermark in intra-coded blocks, while we can detect watermark from the H.264/SVC-encoded P-frames with
high probability. Simulation results of the forth experiment in TABLE IV with GOP structure of IPPP show this clearly.
VII. CONCLUSION
Many robust spatial domain watermarking methods cannot be applied to H.264/SVC-encoded video mainly
TABLEII
PERFORMANCE OF H.264/AVC COMPRESSION WITH GOP STRUCTURE OF IBBPBB
Sequence
Number of Error (Total 200) Payload Decrease of Y-PSNR
(QP28) QP24 QP28 QP32 Our
Scheme
Method in [5]
Our Scheme
Method in [5]
I P B I P B I P B
CITY 0 0 0 0 0 6 0 1 16 1584bits 792bits 0.3371dB 0.0615dB
CREW 0 1 1 0 1 4 0 1 11 1584bits 792bits 0.2490dB 0.2332dB
HARBOUR 0 0 0 0 0 0 0 0 0 1584bits 792bits 0.5913dB 0.1666dB
SOCCER 0 0 1 0 0 1 0 0 1 1584bits 792bits 0.4774dB 0.1761dB
1 11 21 31 41 51 61 71 81 91
-40 -20 0 20 40 60 80
Frame Index
C
o
rre
(%
)
Watermarked(CITY,QP32) Watermarked(HARBOUR,QP32) Without watermark(HARBOUR,Q Without watermark(CITY,QP32)
Fig. 2. Correlation detection using method in [5]
TABLEIII
PERFORMANCE OF H.264/SVC COMPRESSION WITH ALL I-FRAMES
Sequence PD(L0) PF(L0)
QP20 QP24 QP28 QP32 QP20 QP24 QP28 QP32
CITY 0.986 0.985 0.972 0.953 0.005 0.005 0.006 0.007 CREW 0.995 0.991 0.978 0.956 0.012 0.014 0.015 0.006
HARBOUR 0.996 0.991 0.982 0.980 0.015 0.016 0.018 0.019
SOCCER 0.981 0.976 0.959 0.951 0.015 0.015 0.015 0.017
TABLEIV
PERFORMANCE OF H.264/SVC COMPRESSION WITH GOP STRUCTURE OF IPPP
Sequence
Number of Error (L0)
I-frames (Total 50) P-frames (Total 150)
QP20 QP24 QP28 QP32 QP20 QP24 QP28 QP32
CITY 0 0 1 1 1 5 10 17
CREW 0 0 0 0 1 3 4 3
HARBOUR 0 0 0 0 0 0 0 0
because the downsampling of the original size video has a fatal impact on the embedded watermark signal. In this paper, a fast image size change method is used to obtain a low-pass and downsized version of the video frame for embedding, it protects the watermarking signal from being damaged by downsampling during SVC encoding. The JND model is also exploited to dynamically adjust the embedding strength for preserving perceptual quality. We deduce an adaptive detection model based on a likelihood ratio test and gain a good detection performance. The watermark can be detected from not only the H.264/AVC-encoded I-frames, P-frames and B-frames but also the enhancement layer and base layer of H.264/SVC-encoded I-frames and P-frames with high probability.
ACKNOWLEDGMENT
This work was supported by the Natural Science Foundation of China (60803147), the New Teacher Program Foundation (200802131023), the Fundamental Research Funds for the Central Universities (HIT.NSRIF.2009068), the Development Program for Outstanding Young Teachers in Harbin Institute of Technology (HITQNJS.2008.048)and Major State Basic Research Development Program of China (973 Program) (2009CB320905).
REFERENCES
[1] I.J. Cox, M. Miller, J. Bloom., J. Fridrich and T. Kalker, Digital Watermarking and Steganography, Morgan Kaufmann, 2007.
[2] M.Noorkami and R.M. Mersereau, “A framework for robust watermarking of H.264-encoded video with controllable detection performance, ” IEEE Transactions on Information Forensics and Security, vol.2, No.1, pp.14-23, Mar 2007.
[3] X. Gong and H.M. Lu, “Towards fast and robust watermarking scheme for H.264 video,” Proceedings of ISM’08, IEEE, Berkeley, CA, USA, pp.649-653, Dec 2008. [4] D.W. Xu, R.D. Wang and J.C. Wang, “Blind digital watermarking of low bit-rate advanced H.264/AVC compressed video,” IWDW 2009, Guildford, UK, vol.5703, pp.96-109, 2009.
[5] S.H. Liu, F. Shi, J.G. Wang and S.P. Zhang, “An improved spatial spread-spectrum video watermarking,” International Conference on Intelligent Computation Technology and Automation 2010, ChangSha, China, pp.587-590, May 2010.
[6] T.H. Chen, S.H. Liu, H.X. Yao and W. Gao, “Spatial video watermarking based on stability of DC coefficients,” ICMLC’05, vol.9, pp. 5273-5278, Aug 2005.
[7] H.Y. Huang, C.H. Yang and W.H. Hsu, “A video watermarking technique based on pseudo-3-D DCT and quantization index modulation,” IEEE Transactions on Information Forensics and Security, vol.5, No.4, pp.625-637, Dec 2010.
[8] R.V. Caenegem, A.Dooms, J.Barbarien and P.Schelkens, “Design of an H.264/SVC resilient watermarking scheme,” Proceedings of SPIE, Multimedia on Mobile Devices 2010 ,vol.7542.SPIE, San Jose, CA, USA, Jan 2010. [9] P.Mee. and A.Uhl., “Robust watermarking of
H.264/SVC-encoded video: quality and resolution scalability,” Proceedings of IWDW 2010, Seoul Korea, Oct 2010. [10]R.Dugad and N.Ahuja, “A fast scheme for image size
change in the compressed domain,” IEEE Transactions on Circuits and Systems for Video Technology, 11(4): 461-474, Apr 2001.
[11]A.B. Watson, “DCT quantization matrices visually optimized for individual images,” Proc. SPIE. Int. Conf. Human Vision, Visual Processing and Digital Display, San Jose, CA, vol.1913, pp.202-216, Feb 1993.
Cheng Wang Hebei Province, China.
Birthdate: March, 1985. is a master graduated from School of Computer Science and Technology, Harbin Institute of Technology. And research interests on data hiding in video.
Shaohui Liu Hunan Province, China.
Birthdate: Jan., 1977. is Computer Application Technology Ph.D., graduated from School of Computer Science and Technology, Harbin Institute of Technology. And research interests on multimedia security, image processing, video coding, video surveillance and tracking.