PROCESSING IMPROVEMENT OF MAPREDUCE FOR MINING
PROCESS IN BIG DATA
S. Latha, AP/CSE Mahendra Institute of Technology, Mahendhirapuri, Mallasamudram,
Namakkal [email protected]
C. Gayathri, AP/CSE Mahendra Institute of Technology, Mahendhirapuri, Mallasamudram,
Namakkal [email protected]
S.Suresh, AP/CSE Mahendra Institute of Technology, Mahendhirapuri, Mallasamudram,
Namakkal [email protected]
ABSTRACT
MapReduce is an important programming model for data-intensive applications. It depicts better performance for batch parallel data processing. It enables easy development of scalable parallel applications to process vast amount of data on large clusters of commodity machines. It’s a popular open source implementation, Hadoop, developed mainly by Yahoo and Apache, runs jobs on hundreds of terabytes of data. Most of the studies tend to change its framework as little as possible to achieve their requirements. Both CBP of Yahoo and Percolator of Google support incremental data processing framework based on MapReduce model. Incoop is a generic MapReduce framework, which allows existing MapReduce programs, not framed for incremental processing, to run transparently in an incremental manner. Incoop find changes to the inputs and enables the automatic update of the outputs by measuring an efficient, fine-grained result reuse method. Almost all these frameworks support incremental data processing by combining the new data with the data derived from previous batches or iteratively calculating the new data.
Keywords
Big Data, MapReduce, Incremental, and Datamining.
1. INTRODUCTION
In this work, the MapReduce framework offers techniques for convenient, distributed processing of data by enabling a simple coding model that reduces the burden of implementing a complex logic or infrastructure for parallelization, data transfer, fault tolerance and scheduling. An important property of the workloads processed by MapReduce applications is that they are often incremental by nature; i.e., MapReduce jobs often run repeatedly with small changes in their input. For example, search engines will periodically crawl the Web and perform various computations on this input, such as computing a Web index or the PageRank metric, often with very small modifications.
This growing nature of data suggests that performing large-scale computations incrementally can
method would be to develop systems that can reuse the results of prior computation transparently. This method would shift the complexity of incremental processing from the programmer to the processing system, essentially keeping the spirit of high-level models such as MapReduce. A few methods have taken this approach, e.g., DryadInc, and Nectar, in the context of the Dryad system by providing techniques for task-level or LINQ expression-level memorization.
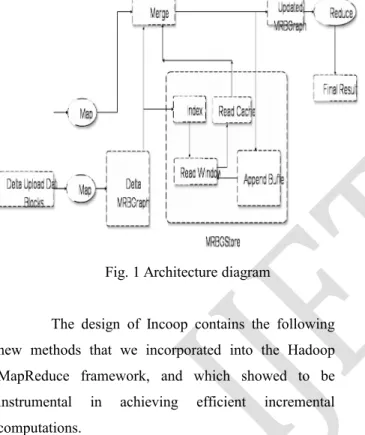
Fig. 1 Architecture diagram
The design of Incoop contains the following new methods that we incorporated into the Hadoop MapReduce framework, and which showed to be instrumental in achieving efficient incremental computations.
Incremental HDFS. Instead of relying on HDFS to store the input to MapReduce jobs, we devise a file system called Inc-HDFS that provides mechanisms to identify similarities in the input data of consecutive job runs. The idea is to divide the input into chunks whose boundaries depend on the file contents so that small changes to input don’t change all chunk boundaries. Therefore partitions the input in a way that maximizes the opportunities for reusing results from previous computations, while preserving compatibility with HDFS, by providing the same interface and semantics.
Contraction phase. We introduce methods for controlling the granularity of tasks so that large tasks can be divided into smaller subtasks that can be re-used even when the large tasks cannot. This is particularly challenging in Reduce tasks, whose granularity depends solely on their input. Our solution is to introduce a new Contraction phase that leverages Combiner functions, normally used to reduce network traffic by anticipating a small part of the processing done by Reducer tasks, to control the granularity of the Reduce tasks.
Memoization-aware scheduler. To increase effectiveness of memoization, we suggest an affinity-based scheduler that uses a work stealing algorithm to reduce the amount of data movement across machines. Our new scheduler strikes a balance between exploiting the locality of previously computed results and executing tasks on any available machine to prevent straggling effects.
When we design and implement an incremental computation framework, many factors including algorithm accuracy, run time, and space overhead need to be taken into consideration. This paper puts focus on the transplantation of parallel algorithms based on MapReduce model and compatibility of nonincremental and incremental processing. A parallel programming framework is presented, which aims to be compatible with the original MapReduce APIs so that programmers do not need to rewrite the algorithms. It makes the following contributions:
Incremental MapReduce framework. It supports incremental data input, incremental data processing, intermediate state preservation, incremental map and reduce functions. The input manager can dynamically discover new inputs and then submit jobs to the master node.
Dynamic resource allocation based on the state. The state provides an important reference for resource request and allocation of the next execution. State information includes prior processing results, intermediate results, execution time, and the number of reduce tasks. Input data, acting as the observation, will change the current state into a new state after the job finishes. Friendly APIs for applications. Method submitJob() in Class JobClient is overloaded. Users only need to follow the method parameters to submit their jobs without modifying
their algorithms or application programs. Furthermore, for continuous inputs, users can get updated outputs in time.
2 RELATED WORKS
The Page Rank algorithm computes ranking scores of web pages based on the web graph structure for supporting web search. The web graph structure is
constantly evolving web pages and hyper-links are created, deleted, and updated. As the underlying web graph evolves, the PageRank ranking results gradually become stale, potentially lowering the quality of web search. It is desirable to refresh the PageRank computation regularly. Incremental processing is a promising approach to refreshing mining results. Given the size of the input big data, it is often very expensive to rerun the entire computation from scratch. Incremental processing exploits the fact that the input data of two subsequent computations A and B are similar. Only a very small fraction of the input data has changed. The idea is to save states in computation A, use A’s states in computation B, and perform re-computation only for states that are affected by the changed input data.
A number of existing studies have followed this principle and designed new programming models to support incremental processing. The new programming models are drastically different from MapReduce, requiring programmers to completely re-implement their algorithms.
may gradually propagate to affect a large portion of intermediate states after a number of iterations, resulting in costly global re-computation afterwards.
The computation is broken down into a sequence of supersteps. In every superstep, a Compute function is invoked on each vertex. It communicates with other vertices by sending and receiving messages and performs computation for the current vertex. This method can efficiently support a large number of iterative graph algorithms. It provides a group wise processing operator Translate that takes state as an explicit input to support incremental analysis. But it adopts a new programming model that is very different from MapReduce. Several research studies support incremental processing by task-level re-computation, but they require users to manipulate the states on their own. In contrast, i2MapReduce exploits a fine-grain kv-pair level re-computation that are more advantageous.
Incremental processing for iterative application, Proposes a timely dataflow paradigm that allows state full computation and arbitrary nested iterations. To support incremental iterative computation, programmers have to completely rewrite their MapReduce programs. Extend the widely used MapReduce model for incremental iterative computation. Previous Map-Reduce programs can be slightly changed to run on i2MapReduce for incremental processing.
A. Limitations of MapReduce
MapReduce programming model is popular due to its simplicity and high efficiency. In MapReduce framework, when a job is submitted, the related input is portioned into fixed size pieces called blocks which are located in different data nodes. A job creates multiple splits according to the number of blocks and each split is processed independently as the input of a separate map task. A map task in a worker node runs the
user-defined map function for each record in the split and writes its output to the local disk. When there are multiple reducers, the map task divides their outputs and each partition is for one reduce task. Reduce tasks will write their outputs to the distributed file system. Despite its powerful automatic parallelization with strong fault-tolerance, the original MapReduce exhibits the following limitations.
Stateless. When map and reduce tasks finish, they write their outputs to a local disk or a distributed file system, and then inform the scheduler. When a job completed, related intermediate outputs will be deleted by a cleanup mechanism. When new data or input arrives, a new job needs to be created to process it. This is just like HTTP, a stateless protocol, which provides no means of storing a user’s data between requests. To some extend, we can also say that MapReduce model is stateless.
Stage independent. A MapReduce job can be divided into two stages: map stage and reduce stage. Each stage will not interrupt the other’s execution. In the map stage, each computing thread executes the map method according to the input split allocated to it, and writes the output to the local node. In the reduce stage, each reduce thread fetches input from designate nodes, executes the reduce method, and writes the output to the specified file system. All map tasks and reduce tasks execute their codes without disturbing each other.
Singe-step. Map tasks and reduce tasks will execute only once orderly for a job. Map tasks may finish at different times, and reduce tasks start copying their outputs as soon as all map tasks complete successfully.
B. Extension of MapReduce
separate or coupled control approaches between state and dataflow, compatible or new added interfaces. Batch parallel processing refers to those that provide high efficient large scale parallel computation with one batch input and produce one output such as Google MapReduce, Hadoop and Dyrad/DryadLINQ. Incremental algorithms, more complicated than the original algorithms, can improve the runtime by modifying algorithms. Its input includes newly added data and the latest running result. Continuous bulk processing is another kind of solution to support incremental processing by providing new primitives for developers to design delicate dataflow oriented applications. It takes the secondary results of the prior executions as a part of explicit input. CBP of Yahoo and Percolator of Google both provide such incremental computation frameworks.
Incremental computation based on MapReduce, making full use of MapReduce programming model, supports incremental processing by modifying the kernel implementation of map and reduces stages. Because HDFS does not support appends currently, some approaches also modify the distributed file system to support incremental data discovery and intermediate result storage.
IncMR is an improved method for large-scale incremental data processing. The framework, inherits the simplicity of the original MapReduce model. It doesn’t modify HDFS and still uses the same APIs of MapReduce. All algorithms or programs can complete incremental data processing without any modification.
Compatibility. Original MapReduce interfaces are retained to avoid incompatibility with the existing implementation of applications. New interfaces are added by overloading methods. HDFS is still used without modification.
Transparency. Users don’t need to know how their incremental data are processed. All state data including their storage paths are transparent to users.
Reduced resource usage. Computing resource request and allocation are determined by the historical state information and current added data size. Dynamic scheduling decision is useful for minimizing the overhead. Several important modules are added in IncMR framework. The input manager is used to find the newly added data automatically. According to the execution delay configuration or input size threshold, it determines if a new data processing will be started. Job scheduler, different from traditional job scheduler which determines the number of tasks to run only according to the configuration file defined in advance, takes the state into consideration when choosing nodes for reduce tasks. A state manager store all needed information for incremental jobs and provides decision support for job scheduler. Output manager is responsible for the storage and update of all outputs.
C. Locality control and optimization
Job scheduler is responsible for creating map tasks and reduce tasks. The main overhead of IncMR lies in the storage and transmission of many intermediate results. In the shuffle phase, the framework fetches the relevant partition of the output of all the mappers to each reduce task node via HTTP. The shuffle and sort phases occur simultaneously; while mapoutputs are being fetched they are merged. Locality control is always used for optimization of job and task scheduling.
Complex locality control. If the number of reduce tasks is more than 1 and is not changed, job scheduler will try to allocate reduce tasks to the nodes that have performed reduce tasks recently because they have cached related state. What’s more, the fetched prior results are also sorted. This locality control will save plenty of time for data transferring. If the number of reduce tasks or the position of reduce task is changed, state fetching and data repartition operations can’t be avoided.
Iterative MapReduce. Iterative computing widely exists in data mining, text processing, graph processing, and other data intensive and computing-intensive applications. MapReduce programming paradigm is designed initially for single step execution. Its high efficiency and simplicity attract a lot of enthusiasm of applying it in iterative environment and algorithms. HaLoop, a runtime based on Hadoop, supports iterative data analysis applications especially for large-scale data. By caching the related invariant data and reducers’ local outputs for one job, it can execute recursively. Twister is a lightweight MapReduce runtime. It uses publish/subscribe messaging infrastructure for communication and supports iterative task execution. In order to provide solutions for applications such as data mining or social network analysis with relational data, iMapReduce is designed to support automatically processing iterative tasks by reusing the prior task processors and eliminating the shuffle load of the static data. Additionally, iterative computing is an indispensable part in incremental processing. We also apply related iterative computing methods in our IncMR framework.
Continuous MapReduce. Ad-hoc data processing is a critical paradigm for wide-scale data processing especially for unstructured data. Reference implements an ad-hoc data
processing abstraction in a distributed stream processor based on MapReduce programming model to support continuous inputs. MapReduce Online adopts pipelining technique within a job and between jobs, supports single-job and multi-job online aggregation, and also provides database continuous queries over data streams. Reference combines MapReduce programming model with the continuous query model characterized by Cut-Rewind to process dynamic stream data chunk. CMR, continuous MapReduce, is an architecture for continuous and large-scale data analysis. Continuous processing is a special case of incremental processing. Although the input is continuous, the processing is discrete. Time interval or delay is an important factor to be considered. IncMR presented in this paper supports continuous processing.
Applications based on MapReduce. When programming in MapReduce framework, all we should do is to prepare the input data, implement the mapper, the reducer, and optionally, the combiner and the partitioner. The execution is handled transparently by the framework in clusters ranging from a single node to thousands of nodes with the data-set ranging from gigabytes to petabytes and different data structures including rational database, text, graph, video and audio. Through a simple interface with two functions, map and reduce, MapReduce model facilitates parallel implementation of many real-world tasks such as data processing for search engines and machine learning. MapReduce is now popularly used in scientific computing fields too. When the new input arrives, it is a challenge for applications to continuously deal with it based on the original MapReduce. This paper addresses the problem in general.
3 OUR WORK
processing for both one step and iterative computation. Compared to previous solutions, i2MapReduce incorporates the following three novel features:
Fine-grain incremental processing using MRBG-Store
Incoop, i2MapReduce supports kv-pair level fine-grain incremental processing in order to minimize the amount of re-computation as much as possible. Model the kv-pair level data flow and data dependence in a MapReduce computation as a bipartite graph, called MRBGraph. A MRBG-Store is designed to preserve the fine-grain states in the MRBGraph and support efficient queries to retrieve fine-grain states for incremental processing.
General-purpose iterative computation
With modest extension to MapReduce API, previous work proposed iMapReduce to efficiently support iterative computation on the MapReduce platform. It targets types of iterative computation where there is a one-to-one/all-to-one correspondence from Reduce output to Map input. In comparison, our current method provides general-purpose support, including not only one-to-one, but also one-to-many, many-to-one, and many-to-many correspondence. Enhance the Map API to allow users to easily express loop-invariant structure data, and propose a Project API function to express the correspondence from Reduce to Map. While users need to slightly change their algorithms in order to take full advantage of i2MapReduce, such modification is modest compared to the effort to re-implement algorithms on a completely different programming paradigm.
Incremental processing for iterative computation. Incremental iterative processing is substantially more challenging than incremental one-step processing because even a small number of updates may propagate to affect a large portion of secondary
states after a number of iterations. To address this problem, propose to reuse the converged state from the previous computation and employ a change propagation control (CPC) mechanism. We also enhance the MRBG-Store to better support the access patterns in incremental iterative processing. i2MapReduce is the first MapReduce-based solution that efficiently supports incremental iterative computation.
TECHNIQUES i2MapReduce
Query Algorithm in MRBG-Store
PageRank in MapReduce
Kmeans in MapReduce
GIM-V (Generalized Iterated
Matrix-Vector multiplication) in MapReduce
CONCLUSIONS
We have described i2MapReduce, a MapReduce-based framework for incremental big data processing. i2MapReduce combines a fine-grain incremental engine, a general-purpose iterative model, and a set of effective techniques for incremental iterative computation. Real-machine experiments show that i2MapReduce can significantly reduce the run time for refreshing big data mining results compared to re-computation on both plain and iterative MapReduce.
In Future evaluate MapReduce computation using a one-step algorithm and within four iterative algorithms with diverse computation characteristics. Experimental applications results show significant performance improvements MapReduce performing re-computation of compared to i2MapReduce.
[1] J. Dean and S. Ghemawat, “Mapreduce: Simplified data processing on large clusters,” in Proc. 6th Conf. Symp. Opear. Syst. Des. Implementation, 2004, p. 10.
[2] M. Zaharia, M. Chowdhury, T. Das, A. Dave, J. Ma, M. McCauley, M. J. Franklin, S. Shenker, and I. Stoica, “Resilient distributed datasets: A fault-tolerant abstraction for, in-memory cluster computing,” in Proc. 9th USENIX Conf. Netw. Syst. Des. Implementation, 2012, p. 2.
[3] R. Power and J. Li, “Piccolo: Building fast, distributed programs with partitioned tables,” in Proc. 9th USENIX Conf. Oper. Syst. Des. Implementation, 2010, pp. 1–14.
[4] G. Malewicz, M. H. Austern, A. J. Bik, J. C. Dehnert, I. Horn, N. Leiser, and G. Czajkowski, “Pregel: A system for large-scale graph processing,” in Proc. ACM SIGMOD Int. Conf. Manage. Data, 2010, pp. 135–146.
[5] S. R. Mihaylov, Z. G. Ives, and S. Guha, “Rex: Recursive, deltabased data-centric computation,” in Proc. VLDB Endowment, 2012, vol. 5, no. 11, pp. 1280–1291.
[6] Y. Low, D. Bickson, J. Gonzalez, C. Guestrin, A. Kyrola, and J. M. Hellerstein, “Distributed graphlab: A framework for machine learning and data mining in the cloud,” in Proc. VLDB Endowment, 2012, vol. 5, no. 8, pp. 716–727.
[7] S. Ewen, K. Tzoumas, M. Kaufmann, and V. Markl, “Spinning fast iterative data flows,” in Proc. VLDB Endowment, 2012, vol. 5, no. 11, pp. 1268–1279.
[8] Y. Bu, B. Howe, M. Balazinska, and M. D. Ernst, “Haloop: Efficient iterative data processing on large clusters,” in Proc. VLDB Endowment, 2010, vol. 3, no. 1–2, pp. 285– 296.
[9] J. Ekanayake, H. Li, B. Zhang, T. Gunarathne, S.-H. Bae, J. Qiu, and G. Fox, “Twister: A runtime for iterative mapreduce,” in Proc. 19th ACM Symp. High Performance Distributed Comput., 2010,pp. 810–818.