Rochester Institute of Technology
RIT Scholar Works
Theses
Thesis/Dissertation Collections
1992
Context sensitive optical character recognition
using neural networks and hidden Markov models
Steven C. Elliott
Follow this and additional works at:
http://scholarworks.rit.edu/theses
This Thesis is brought to you for free and open access by the Thesis/Dissertation Collections at RIT Scholar Works. It has been accepted for inclusion in Theses by an authorized administrator of RIT Scholar Works. For more information, please [email protected].
Recommended Citation
Rochester Institute of Technology
Computer Science Department
Context Sensitive Optical Character Recognition
.
uSIng
Neural Networks and Hidden Markov Models
by
Steven C. Elliott
A thesis, submitted to
The Faculty of the Computer Science Department in partial
fulfillment of the requirements for the degree of
Master of Science in Computer Science
Approved by:
Professor P. G. Anderson
Professor R. T. Gayvert
Professor
J. A. Biles
PERMISSION GRANTED
Title:
Context Sensitive Optical Character Recognition using Neural Networks and
Hidden Markov Models
I STEVEN C.
ELLIOTT
hereby
grant permission
to the Wallace Memorial Library of
the Rochester Institute of Technology to reproduce my thesis
in
whole or
in
part. Any
reproduction will not be for commercial use or profit
ABSTRACT
This
thesisinvestigates
a methodfor
using contextualinformation
in
text
recognition.This is based
on the premisethat,
while reading,humans
recognize words with
missing
or garbled charactersby
examining thesurrounding
characters and thenselecting
the appropriate character.The
correct characteris
chosenbased
on aninherent knowledge
ofthelanguage
andspelling techniques.
We
can then modelthis statistically.The
approach takenby
this
Thesis is
to combinefeature
extractiontechniques,
Neural Networks
andHidden
Markov Modeling. This
method ofcharacter recognition
involves
a three step process: pixelimage
preprocessing,neural network classification and contextinterpretation.
Pixel image
preprocessing
applies afeature
extraction algorithm tooriginal
bit
mappedimages,
which produces afeature
vectorfor
the originalimages
which areinput
into
a neural network.The
neural network performs theinitial
classification ofthe charactersby
producing ten weights, onefor
each character.The
magnitude of theweight
is
translatedinto
the confidence the networkhas
in
each of the choices.The
greater the magnitude and separation, the more confident the neural networkis
of a given choice.The
output ofthe neural networkis
theinput for
a contextinterpreter.
The
contextinterpreter
usesHidden Markov
Modeling
(HMM)
techniques todetermine
the most probable classificationfor
all charactersbased
on thecharacters that precede that character and character pair statistics.
The
HMMs
arebuilt
using an a prioriknowledge
ofthelanguage:
a statisticaldescription
oftheprobabilities ofdigrams.
Experimentation
and verification of this method combines thedevelopment
and use of a preprocessor program, aCascade Correlation
Neural Network
and aHMM
contextinterpreter
program.Results
from
these experiments show the neural network successfullyclassified
88.2
percent ofthe characters.Expanding
this to the wordlevel,
63
TABLE OF CONTENTS
1.0
Introduction
1
2.0
Artificial Language Generation
6
3.0
Project Description
3.1
Feature Extraction (Image
Preprocessor)
9
3.2
Neural Network Models
14
3.2.1
Hopfield
Network
143.2.2 Back
Propagation Network
16
3.2.3
Cascade Correlation
20
3.3
Context
Interpreter
(Hidden
Markov
Modelling)
26
4.0
Results
andConclusions
33
4.1
Feature
Extraction
Results
33
4.2
Neural Network Results
34
4.3
Hidden Markov Model Results
38
4.4
Conclusion
415.0
Recommendations
for Future
Research
426.0
Bibliography
43
7.0
Appendices
A
Handwritten
Digit Examples
B
List
ofWords
in
Vocabulary
C
Neural
Net Output
(Observation
Probabilities)
LIST OF FIGURES
Figure
1
Pattern
toObject Relationships
2
Figure
2
System Architecture
5
Figure 3
Initial Probabilities
6
Figure
4
Transition Probabilities
7
Figure
5
Sub-Feature
Graphic
10
Figure
6
Pixel
Map
Sub-Windows
11Figure
7
Feature Matrices
12
Figure
8
Hopfield
Network
Architecture
14Figure
9
2
Layer Perceptron
Architecture
16
Figure
10
Cascade Correlation Architecture
23
Figure
11Hidden
Markov
Model
Terms
28
Figure
12Viterbi Algorithm
29
Figure
13
Actual Transition Probabilities
31
Figure
14Network Results for Individuals
35
Figure
15
Network
Confusion
Matrix
36
[image:6.552.100.460.129.419.2]1.0
Introduction
This
thesis
investigates
a methodfor
using contextualinformation in
text recognition.
This is based
on the premisethat,
while reading,humans
can use context to
help
identify
words garbledby
misspelling,bad
penmanship,
bad
printing
etc.,by
examining
the surroundingcharacters andthen
selecting the
appropriate character.The
correct characteris
chosenbased
onfamiliarity
of thelanguage
and spelling techniques.The
readerroutinely
usesknowledge
about the syntactic, semantic andfeatural
dependencies between
characters andbetween
words[1]
.The
use ofknowledge
aboutdependencies between
characters withinwords
is
exploredin
thisThesis.
The
method we usein
thisThesis
does
notexplore the
dependencies between
wordsbut
our method could easilybe
expandedto
include
"global context".This
paper proposes a methodfor
pattern recognition combined withthe
knowledge
ofthe character context to successfullyinterpret handwritten
digits
combined as words.Two
aspects of this recognition process areinvestigated:
the recognition oftheindividual
patterns(characters)
and thecombination ofthepatterns
into
specific words.Pattern
recognitionhas
traditionally
been
groupedinto
two generalcategories: the "statistical" or "decision theoretic"
approach and the
"structural/syntactic"
approach
[2].
The
statistical ordecision
theoreticapproach
is
often referred to as a geometric approach.This
methodologyfocuses
onhow
a patternis
constructed andhow
that pattern maps to theobjectthat
it
represents.Within
the geometric approach, patterns aredescribed
by
theircomponents, which can
be
viewed as vectorsin
a coordinate space ofN
dimensions.
Each
pattern then corresponds to a pointin
that space.With
this type of representation,
familiar
mathematicsbecome
availablefor
pattern recognition.
Euclidean
distances between
two pointsbecome
asimilarity metric
for
characters.Two
patterns that represent similar oridentical
objects wouldbe
expected tobe
very close to each otherin
patternspace;
however
it is
usually necessary to replace thepixel arrays withfeature
vectors.
The
relationshipbetween
the geometricdescription
of a pattern andon one ofthree classifications.
The
relationship
between
a pattern and theobject
is
deterministic
if
there
is
a one to one, or a many to one relationshipbetween
the
pattern or patterns and the objectbeing
represented.A
non-deterministic
relationship
existsif
a pattern can represent more than oneobject
(or
class).The
non-deterministic relationshipis
probabilisticif
different
probabilities canbe
attachedto
the various relationships.A
representation
is
stochasticif
thereis
afinite
probability that an object canbe
representedby
points anywherein
thepattern space.These
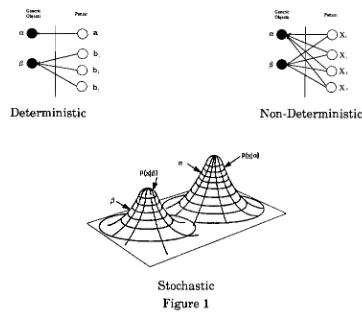
relationshipsare shown
graphically
in
Figure
1.
Deterministic
Non-Deterministic
Stochastic
Figure
1In
character recognition of machine printedtext,
if
onlya singlefont is
used, and the system
is
completelyfree
ofnoise, then each pixel array wouldmap to a single object.
A
deterministic
geometric representation wouldbe
realized.If
multiplefonts
were used, multiple pixel arrays would represent the same object(i.e.,
different
version of theletter
"A").
In
this case, adeterministic
representationis
also realized.In
the case of recognition of [image:8.552.109.471.223.543.2]different
objects(such
as the confusionbetween
the characters"I",
"1" and"1").
This
resultsin
the generation of non-deterministic relationships.If
finite
probabilities canbe
assigned to each case then the relationshipis
saidto
be
stochastic.In
the
case where non-deterministic or stochastic relationships exist,additional
intelligence
mustbe built into
the systemto
differentiate between
similar patterns.
The
use ofthis
intelligence is
referred to as contextdirected
pattern recognition[3].
Context directed
pattern recognition canbe
either syntactic or stochastic
in
nature.To
use the syntax ofalanguage for
pattern recognition, weneed to
have
theproduction rules which were used togenerate the
language.
This
approachhas been
taken with the use ofAugmented Transition Networks (ATN).
Using
this method, characters arerepresented as nodes.
The
transition,
or arc,from
one node to another canonly
be
completedif
the conditionsimposed
on those arcshave been
meet.One
majordifficulty
associated with the use ofthis type of contextin
patternrecognition
is
determining
how
the grammaris
tobe
inferred.
The
stochastic approach to contextdirected
pattern recognitionis
notbased
ontheproduction rulesthatgeneratethelanguage,
but
ratheris
based
on the statisticalmake-up ofthe
language. This
approach usesthe statisticswhich
indicate
what characters occur and what order those characters occur.This
statisticalknowledge
ofthelanguage
canbe
obtainedfrom
thelanguage
without
knowing
any of the syntax or production rules that were used togeneratethe
language.
The
use ofHidden Markov
Models
best describes
thistypeof context
directed
patternrecognition.For
thisThesis,
wedeveloped
an artificiallanguage
which consisted of100
words, each5
charactersin
length.
The
charactersfor
thewords are thedigits
0
thru9.
These
digits
were eachhandwritten,
scanned and thendigitized. The
statistical characteristics ofthelanguage
wasdetermined
andused as part ofthepatternrecognition process.
The
approach takenby
thisThesis
was to combine three separaterecognition techniques
into
a single system, utilizing thebenefits from
eachtechnique.
These
three techniques were:feature
extraction, neural networksand Hidden
Markov Modeling.
The feature
extraction processlooked
withincharacters as words and,
based
onits
knowledge
ofthelanguage,
helped
toresolve
the
correctword classification.The
feature
extractionalgorithm examined the original pixel mapsfor
features
corresponding
toevidencefor lines
(strokes)
at various placesin
four
orientations
in
the
image.
The
output ofthe
feature
extraction algorithm was afeature
vector representativeoftheoriginalimage.
The feature
vectors were used asinput into
aneuralnetwork.The
neural network wasused toperformtheinitial
classificationofthecharacters.
The
training
data for
the neural network consisted ofhalf
ofthehandwritten
characterdatabase,
while the secondhalf
of thedatabase
was usedfor
testing
purposes.The
neural network selected thedigit
most closelyidentified
by
thefeature
vector.The
neural networkhad
ten output nodes, each output node represented a specificdigit.
The
magnitude of the output value was translatedinto
the confidence ofthe neural networkfor
that classification.The
greaterthe magnitude, thegreaterthe confidence.These
confidencesfor
each classification were recordedfor
usein
the nextstep ofthe process.The
output of the neural network was then usedby
the contextinterpreter.
The
contextinterpreter
usedHidden
Markov
Modeling
techniques todetermine
the most probable classificationfor
all characters.The HMMs
werebuilt
using an a prioriknowledge
of thelanguage
-a
language
model.The
modelincluded
theinitial
state probabilities(the
probability a
digit
was thefirst digit
of a word) and the transition probabilitiesfor
a specificdigit
tofollow
anotherdigit
within the word(digram
statistics).The
contextinterpreter
examines the probabilities of allof the characters within word
boundaries.
The
output of theHMM
was a sequence ofdigits
thatbest
correspond to theinput
ofobserveddigits.
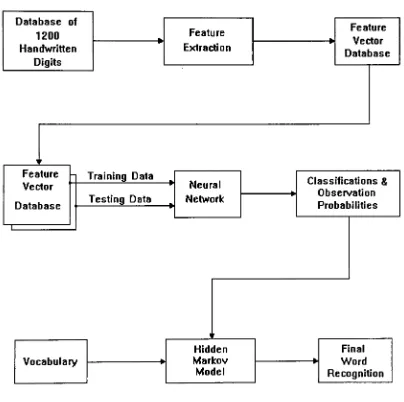
System Architecture
Database of
1200 Handwritten
Digits
Feature Extraction
Feature
Vector
Database
Feature
Vector
Database
Training
DataTesting
DataNeural
Network
Classifications & Observation
Probabilities
Vocabulary
Hidden Markov Model
Final
[image:11.552.75.479.149.551.2]Word Recognition
2.0
Artificial Language Generation
Input
into
the
system wasfrom
adatabase,
suppliedby
Bell
Laboratories
[4],
consisting
of1200
handwritten digits.
The database
was generatedby
having
12
individuals
writethe
set ofdigits (0
thru9)
ten times.Each
set ofdigits
0
through9,
for
eachindividual
was considered anattempt.
Each
digit
waslabeled
according to
who wroteit
andduring
which attemptthe
digit
was created.The
attempts werelabeled
"A" through "J".This
resultedin
120
distinguishable
attempts of the10
digit
set.These
sampleswere then scanned and normalized
into
1200
separate16
by
16
pixel maps.The
maps were then convertedinto
anASCII
readableformat.
Within
the maps, a "#" character represents alogical
1
(black
pixel), while the " "(space)
characterrepresents alogical 0
(white
pixel).Examples
ofthehandwritten digits
andthenormalized pixel maps are shownin
Appendix
A.
These digits
provided thebasis for
the generation of the artificiallanguage. The language
vocabularyconsisted of100
words, each word was5
digits
in
length.
The language
was generatedby
first
selecting aninitial
character probability.
This
determined
thefirst digit
for
each word.The
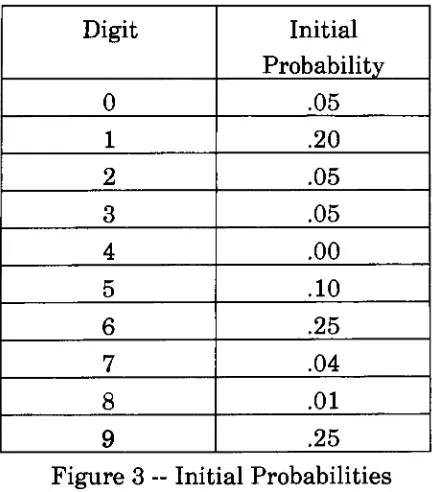
initial
probabilities, shownin
Figure
3,
were chosenat random.Digit
Initial
Probability
0
.051
.202 .05
3
.054 .00
5
.106
.257
.048
.019
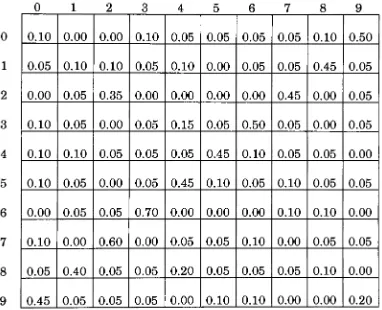
.25 [image:12.552.167.384.412.658.2]In
additiontothe
initial
probabilities,
the transitionprobabilities wereselected.
This information indicated
with what probability onedigit
wouldfollow
anotherdigit
within a word.This
only
applies within words anddoes
not cross word
boundaries.
For
example,
a "2" willfollow
a"1" ten percent ofthe
time,
while a "1" willfollow
a "2"only
five
percent ofthe time.These
values were chosen
arbitrarily in
order to provide some type of selectionprocess.
The
transition
probabilitiesare shownin
Figure
4.
The
digits down
the
left
side are thefirst
of a pair, while thedigits
across thetop
are the second.0
12
3
45
6
7
8
9
0
0.10
0.00
0.00
0.10
0.05
0.05
0.05
0.05
0.10
0.50
1
0.05
0.10
0.10
0.05
0.10
0.00
0.05
0.05
0.45
0.05
2
0.00
0.05
0.35
0.00
0.00
0.00
0.00
0.45
0.00
0.05
3
0.10
0.05
0.00
0.05
0.15
0.05
0.50
0.05
0.00
0.05
4
0.10
0.10
0.05
0.05
0.05
0.45
0.10
0.05
0.05
0.00
5
0.10
0.05
0.00
0.05
0.45
0.10
0.05
0.10
0.05
0.05
6
0.00
0.05
0.05
0.70
0.00
0.00
0.00
0.10
0.10
0.00
7
0.10
0.00
0.60
0.00
0.05
0.05
0.10
0.00
0.05
0.05
8
0.05
0.40
0.05
0.05
0.20
0.05
0.05
0.05
0.10
0.00
9
0.45
0.05
0.05
0.05
0.00
0.10
0.10
0.00
0.00
0.20
Figure
4 -Transition
Probabilities
A
program was written to use thedata from Figure
3
andFigure
4
togenerate theartificial
language.
This language is
shownin
Appendix
B.
The data from
Figure 3
andFigure
4
was also usedfor
theHidden
Markov
Modeling,
thisis
discussed
in
section3.3.
The database
ofhandwritten digits
was used to generate the words [image:13.552.74.456.240.550.2]the neural network, while attempts
F
thruJ
were usedfor
testing
of the neural network andthe
contextinterpreter.
All
of thedigits
in
all of the attemptswerepassed throughthe
feature
extraction algorithm.3.0
Project
Description
3.1
Feature
Extraction
Sub-System
The
first
process within the recognition systemis
thefeature
extraction sub-system.Feature
extraction allowsfor
statistical characterrecognition.
With
this
method, the classification of the patterns wasbased
on selectedfeatures
whichhave been
extractedfrom
the original pixel map, rather thantemplate matching
of the pixel maps themselves.This
makes the system moretolerant
of minor variations[5].
Pixel
map matching wouldbe
effectiveif
thedistortions
were of the"salt
and pepper noise" type.Handwritten
charactershave
"plastic
distortion".
The
difficulty
withfeature
extractionis
knowing
whatfeatures
to extract andhow
thosefeatures
shouldbe
represented.The
selection ofthesefeatures
waslargely
empirical and adhoc,
anddrew
upon ourknowledge
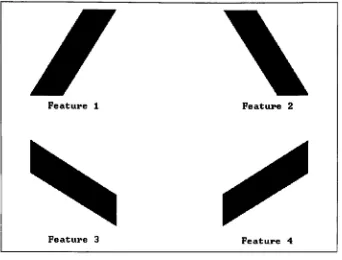
of the problem.Four
primitivefeatures
were selectedfor
extractionfrom
the original patterns.All
of thefeatures
werelines,
each withdifferent
slopes.These
features,
known
asConvolution Kernels for
Feature
Extraction,
are shownin
Figure
5.
These features
wereimplemented
because
of their simplicity.Additional
features
such asline
intersection,
horizontal
lines,
etc. couldbe
implemented
aspart ofanyfuture
research project.The
feature
extraction algorithm maps the original pixel arrayfrom
feature
space todecision
space.From
thedecision
space, the output vectorswere mapped to the appropriate objects.
Classification
of the pattern was thenbased
on theoutputfeature
vector ratherthan the pixel map.The feature
extractionalgorithmusedhere
is
similarto convolutions,a signal processing technique.Convolutions
are common and powerful techniquesfor
filtering
images.
A
convolutionis
a speciallydesigned filter
(matrix)
thatis
combined together with a portion of animage
to compute a transformed pixel value.The
filter,
or convolutionkernel,
is
centered on each pixelin
theinitial
pixel map.The
sum ofthe product ofthefilter
and the underlyingimage
is
computed.The
resultis
a transformed value of thecenter pixel.
The
filter is
then moved to the next pixel and the processis
repeated.
Some
special processing maybe
needed to takeinto
accountthe
Feature 1 Feature 2
[image:16.552.104.446.73.333.2]Feature 3 Feature 4
Figure 5
The
convolution ofthefilter
andimage is
determined
by
computing thepoint to point product of the corresponding elements of the
filter
and theportion of the
image
whichis
being
overlaid, and then summing thoseproducts.
By
properly selectingkernels for
afilter,
the convolutions candetect
lines,
edges, createhigh
andlow
passfilters,
and variety of otherfunctions
[6].
The feature
extraction algorithm presentedhere
appliesfour
filters
tothe original pixel
image.
The
four
filters
represent thefour
features
whichare
being
extractedfrom
the originalimage.
Each
filter
is
designed
todetermine
if
thefeature
it
representsis
presentin
the underlying portion ofthe pixel map.
Each filter
is
representedby
a4
by
4 matrix, whose valuesare
designed
todetect
thedesired
features.
The
original pixel maps weredivided
into
sixteen4
by
4
pixel areas asshown
in Figure 6.
The
four
feature filters
are applied to each area.Each
filter is
overlaid overthedesignated
area.The
pairwise products ofthefilter
greater than
4
but
notdivisible
by
4,
thenthe
feature is
present, otherwisethe
feature is
notpresent.All
sixteen areas of original pixelmap
were overlaid with thefour
feature filters
to provide afeature
vector made up of64
elements.Each
element representsthe
presence ofa specificfeature (or
evidence ofa stroke) within a specific area.The
elements ofthe
outputfeature
vector arebinary
values, with a
1
indicating
the
presenceofthefeature
and a0
indicating
that thefeature
wasnot present.0
3
7
13
15
1
2
3
45
6
7
8
9
10
11 1213
1415
16
Figure
6
Each
primitivefeature
was confined to the4
by
4 window; thatis,
nofeatures
crossed windows or wrapped around at the edges.Unlike
theimage
processing convolutions, the
filters do
not center on a single pixelbut
examinethe entire area ofthefilter.
The
filters
are movedfrom
area to area(4
pixel rowincrements),
in
the order shownin Figure
6,
instead
ofmovingfrom
pixel to pixel.No
mirroringof pixels was performed attheedges.Using
thistechnique,
a16
by
16
pixel map(256
elements) was representedby
a64
bit
vector, thus providing a4
to 1 compression ratio.This
compression was convenientfor
use of thefeature
vector asinput
into
theneural network.
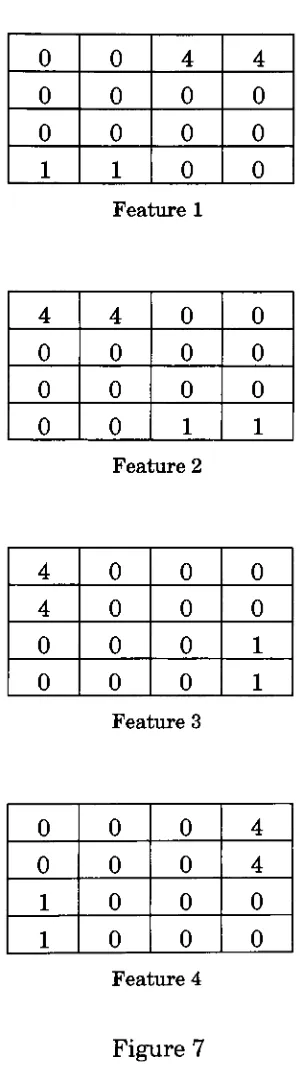
[image:17.552.162.384.222.342.2]0
0
4
4
0
0
0
0
0
0
0
0
1
1
0
0
Feature 1
4
4
0
0
0
0
0
0
0
0
0
0
0
0
1 1Feature 2
4
0
0
0
4
0
0
0
0
0
0
10
0
0
1
Feature 3
0
0
0
40
0
0
4
1
0
0
0
1
0
0
0
[image:18.552.201.355.94.632.2]Feature 4
Each
of theoverlay
filters
were appliedto
all of the quadrants.The
general notationfor
this
calculation shownsymbolicallyis:
3 3
Q
=Z Z
WijFij
i=o j=o J
J
where:
i,
j
= relative row and column coordinatesW
= window area of original pixelmap
F
= convolutionkernel
Q
= summationof pairwise productThe
valueQ
wasthentested todetermine
if
theparticularfeature
was present.lifQ>4ANDQ*8)
Vk
=0
otherwiseWhere
Vfc
is
thekth
component ofthefeature
vector.3.2
Neural Network Classification
Artificial
neural networkshave
been
widely usedin
patternrecognition applications.
Various
paradigmshave been
used.The
different
networkmodels are specified
by:
1.
Network
topology:the
number ofneuronsandhow
theneuronsare
interconnected.
2.
Node
characteristics:the
typeof non-lineartransferfunction
used
by
theneuronfor
calculating
theoutput value.3.
Training
rules: specifyhow
theweights areinitially
set andadjusted to
improve
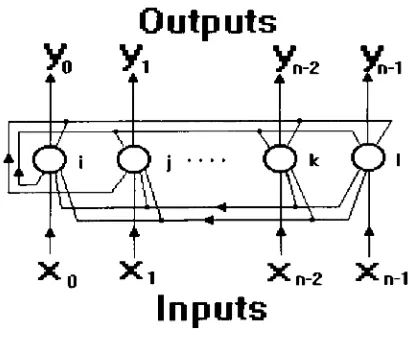
performance ofthenetwork.3.2.1
Hopfield
Network
One
such paradigmis
theHopfield
network[7]. The Hopfield
networkis
ahand
programmed associative memory.It
is
composed of a single,fully
recurrent
layer
ofneurons that act asboth input
and output.The diagram
of aHopfield
networkis
shownin
Figure
8.
Outputs
X)
Yl
Xn-2
Xi-1
X0
Xt
Xn-2
Xn-1
Inputs
Figure
8
The
output ofthe neuronsis
passedback
asinput
to the neurons, thus [image:20.552.191.397.423.592.2]connected,
i.e.,
for
alli
andj,
Wjj
=Wji?
andWy
=0
,whereWy
is
the synaptic weightconnecting
neuronsi
andj. The
neurons are updatedby
theruleXj
=fllWijXi)
(Eq.
1)
where
Xj
is
the
output of neuroni.
The
function f is
generally
non-linear;such as signum, tanhorthesigmoidy =
(1
+ e"x)_1The
non-linearfunction
compresses the output so thatit lies
in the
rangebetween
0
and1
orbetween
-1 and +1.This is
sometimes referred to asthesquashing
function.
The Hopfield
networkdoes
notlearn
through execution ofthe net.The
weights mustbe
setin
advance.The
weight matrixis
createdby
taking
the outer product of eachinput
pattern vector withitself,
and summingall ofthe outerproducts, andsetting
thediagonal
to0.
The Hopfield
network can complete or restore corrupted patternsby
matchingnew
inputs
with the closest previously stored patterns.The
input
pattern vectoris
applied to the network node.The
network then cycles throughiterations
untilit
has
converged.Convergence
is
when the outputs of the network nolonger
change on successiveiterations.
Hopfield
proved thatconvergenceis
alwaysguaranteed.The
Hopfield
networkhas
two majordisadvantages.
The
first
is
the number of patterns thatcanbe
stored.It has
been
shownthat the maximum number of patterns recalledis
generallylimited
by
n/(21og n), where nis
the numberof nodes[8]
.3.2.2
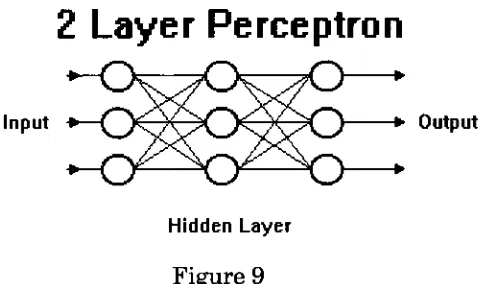
Back Propagation Network
The back
propagation model or multi-layer perceptronis
a neural networkthat
utilizes a supervisedlearning
technique.Typically
there are one or morelayers
ofhidden
nodesbetween
theinput
and output nodes.See
Figure
9.
The
multiplelayers
allowfor
thecreation of complex contoursdefining
decision
regions.A
singlelayer
perceptron can only create ahalf
planebounded
by
ahyperplane decision
region.A
twolayer (single hidden layer
between input
and output) perceptron easilyallowsfor
the creation of convexdecision
regions, while a threelayer
(multiple
hidden
layers)
perceptron allowsfor
the creation of arbitrarily complex regionslimited
by
the number ofhidden
nodes.More
difficult
to seeis
that anydecision
boundary
canbe
achieved with a2
layer
network,but
this canbe
very complex.2 Layer
Perceptron
Input >
f
/CX
JXXL
)0()
? Output [image:22.552.187.429.337.479.2]Hidden Layer
Figure 9
The
use oftheback
propagationtraining
algorithm requires the use of a non-linear,differentiable
transferfunction
within each node.The
sigmoidal
function described
abovefills
these requirements.The back
propagationtraining
algorithmis
a supervisedlearning
technique.
Input
vectors are matched withthedesired
output vectors.These
pairs are referred to as thetraining
pairs.The
networkis
trained using aTo
train a multi-layer perceptron usingback
propagation, the general algorithmis
asfollows:
1.
Set
the
initial
starting
synapticweights tosmall randomvalues.
2.
Apply
the
input
vectorfrom
the
training
pairto the network.3.
Propagated
the
vectorthrough thenetworkusing
thenonlinear
transferfunction
tocalculate theoutput ofthe
network.
The
calculations are performedon alayer
by
layer
basis.
4.
Calculate
theerrorvalue, whichis
thesquareddifference
between
the
actual output andthedesired
output vectorfrom
the
training
pair.5.
Propagate
theerror signalback
through the output,hidden
andto the
input layers
adjusting
theweightsto minimizetheerror.
6.
Iterate
steps2
through5
for
all ofthetraining
pairs withinthe
training
set until theerrorlevel for
theentiresetis
acceptably
low.
In
more specificterms,
the neurons areinitialized
to theinput
values.The
states of all other neurons(xj)
in
the network aredetermined by:
Xj
=flZWijXi)
(Eq. 2)
The
nonlinearfunction
f
needs tobe
differentiable,
so we use tanh or thesigmoid:
y
=(l+e-X)-l
(Eq.3)
This
calculationis done
layer
by
layer
with the output of eachlayer
serving as
input
into
the nextlayer.
This
continues until the nodes on theoutput
(rightmost)
layer have been
computed.The
errorE
ofthenetworkis:
E
=Z(Xk
- tk)2Where
the
sumis
overthe
output nodes,Xfc,
whose "target" outputis
t^
(from
the
training
data).
Training
consistsofdetermining:
AWij
=-a
(6E/6Wij)
(Eq.
5)
where a >
0 is
the
training
ratefor
one pass(epoch)
overthe
training
data.
First
we adjustthe
weights ofthe
outputlayer. The back
propagationalgorithm uses a
technique
similar tothe
"Delta
Rule"developed for
perceptrons.
The
"Delta
Rule"is
shown as:where:
Wy(n+1)
=Wij(n)
+AWy
(Eq.6)
tfc
=target outputX^
=Actual
output8
=error signalAWjj
= correctioncorresponding
to theith
input %i
a =
learning
ratecoefficientWjj(n+1)
=value oftheweight afterthe adjustmentWjj(n)
= value oftheweightbefore
theadjustmentThe back
propagation algorithm uses thederivative
ofthenon-linearsquashing
function f().
If
y =(1
+e~x)"l, theny'
=
y(l-y)
(Eq.
7)
Which
makes the calculation particularly easy.No
newfunction
needs tobe
evaluated.
The
use ofthe partialfirst derivative
ofthe errorfunction
allowsfor
asimple gradient
decent
search techniquein
finding
the global minimafor
theerror value.
Training
the outputlayer
of the networkis
fairly
straightforwardThe
following
equations show thetraining
processfor
determining
a singleweight
between
neuron(p)
in hidden layer
(j)
to output neuron(q)
in
the outputlayer
ofthe
network:5q
=yqd
-yq)(t
-yq)
(Eq.
8)
AWpq
=r|
oq
yp
(Eq<
9)
Wpq
(n+1)
=Wpq
(n)
+AWpq
(Eq.
10)
where:
t =
target
outputfor
neuronq
yq
=Actual
output of neuronq
8q
= error signalfor
neuronq
A[
= correctioncorresponding
to theith
input
Xi
r\
=learning
rate coefficientWi(n+1)
=value ofthe weight afterthe adjustmentWj(n)
=value ofthe weightbefore
the adjustmentThe
adjusting of the weights of thehidden
layer
is
moredifficult
because
thedesired
output ofthese neuronsis
notknown.
Back
propagation trains thehidden
layer
by
propagating the output errorback
through thenetwork, adjusting theweights at each
layer.
The
error value(5)
mustbe
calculated withoutknowing
what thedesired
output of thehidden layer
neurons shouldbe.
The
error value8 is
first
calculatedfor
each ofthe outputlayer
neurons.These
error values are then propagated through the associatedinput
weights(of
the outputlayer
neuron)
back
to thefirst
hidden layer
neuron.These
propagated error values arethen usedto adjust theinput
synaptic weightsfor
thehidden layer. The
same procedureis
used again to propagate the error valueback
to the nexthidden layer
ortotheinput
layer.
The
error values calculatedfor
theoutputlayer
(Eq.
8)
is
multipliedby
the weightthat connects the output neuron with thehidden
neuron.This is
done for
all the connectionsbetween
the outputlayer
and thehidden layer
summing
all of the products and then multiplying that valueby
thederivative
ofthe
non-linear sigmoidfunction (Eq.
7).
Calculating
the newweight values
is
samefor
thehidden layers
asit is for
the outputlayers
asshown
in
equations(Eq. 9
andEq.
10).
The
equationfor
determining
thehidden layer
error valueis
asfollows:
6P
j
=^p
jd-yp
j)
(5q,kWpq>k)
(Eq.
11)
While
theback
propagation networkis
muchimproved
over theHopfield Network for
pattern recognition, there are still caveats with thealgorithm thatmust
be
overcome.The
most severelimitation is
thelength
oftime required to train a network.
For
complex problems, thetraining
timecould
be
excessive, or even moreserious, the networkmayfail
and mayneverbe
trained.The
networktraining
failures
areusuallyattributedto one oftwosources: networkparalysis or
local
minima.Network
paralysis occurs whenthe synaptic weightsbecome
verylarge
values.
This
forces
the output ofthe neuron tobe large.
This is
in
a regionwhere the
derivative
ofthe non-linear sigmoidfunction
wouldbe
very small.The
smaller this value, the slower thetraining
becomes,
until thetraining
appears to
be
at avirtual standstill.The
Back Propagation
uses gradientdecent
todetermine
theminimumerror value
for
a neuron.The
error surface of a complex network maybe
filled
with manyhills
and valleys.Local
minima occur when the networksettles
in
a shallow valley when thereis
a muchdeeper
valley(global
minima) nearby.
There
is
generally no way ofknowing,
without timeconsuming experimentation, what
is
the right network architecturefor
agiven problem.
3.2.3
Cascade
Correlation
In
an attempt to overcome thelimitations
mentioned abovefor
theback
propagationlearning
algorithm, theCascade
Correlation
networktimes
was examined.The
Cascade Correlation
network paradigm was usedfor
this
Thesis.
Two
major problems werediscovered
which contribute to slowness ofthe
back
propagationlearning
algorithm.The first
problemis
the"step
size"problem and
the
secondis
the
"moving
target"problem.
Several
cleverstrategies were
incorporated
in the
Cascade Correlation
algorithm whichhelped
speedup
thetraining
times.
A
networklearns
whenthe
error valuefor
each neuronis
reduced toan acceptable
level.
The Back Propagation
algorithm uses a partialfirst
derivative (Eq.
7)
ofthe error values with respectto the weights to perform agradient
decent
in
weight space.The
rate that thisdecent is
madeis
related to thestep
size.If
infinitesimally
small steps aretaken,
then calculating theerror values after each step will eventually result
in
obtaining alocal
minimum of the errorfunction.
While
this may work, the time to performeach ofthe
training
steps couldbe
infinitely
long.
If
the steps taken are toolarge,
thelocal
minimum may neverbe
reachedbecause
thelarge
step mightnot provide the resolution needed to
find
thelocal
minimum.If
alocal
minimumis
reached,it
has been
empiricallydetermined
that thelocal
minimum will
be
theglobalminimum, or atleast
a "goodenough solution"for
most problems
[10].
In
orderto choose an appropriatestep size, additionalinformation
(not
part of the original
Back
Propagation
algorithm)is
needed.In
addition to the slope ofthe errorfunction,
information
aboutits higher
orderderivatives
or curvature
in
the vicinityofthecurrent point,canbe
used.The
quickprop algorithm[11]
estimates the second orderderivative
ofthe error
function
to update the synaptic weights anddetermine
thelocal
minimum.
For
use ofthe quickprop algorithm, two simplifying assumptionswere made:
1.
Small
changesin
one weighthave
little
or no effect onthe errorgradient seen at other weights.
2. The
error as afunction
ofone synaptic weight canbe
approximated
by
a parabola openingupward.As
part of the algorithm, thefirst derivative
calculatedfor
the previouslast
made to each weight.Using
the
previous slope value, the current slopevalue and the
last
weight change, a parabola canbe fit
to those points andthe
minimum pointoftheparabolacanbe determined
analytically.The
procedurefor
the quickprop
algorithmis
essentially the same asthe steps
for
the
Back Propagation
algorithm.The
majordifference is
thecalculation used to
determine
theweight update value.The
equation usedin
thequickprop
algorithmis
shownsymbolically
as:AW(t)
=(S(t)
/
S(t-l)
-S(t))
AW(t-l)
(Eq.
12)
where:
S(t)
= current errorderivative
S(t-i)
= previous errorderivative
AW(t-i)
= previous weight changeThe
second problemidentified
as a source of slowlearning
withBack
Propagation
is
referred to as the"moving
target"problem.
Each
neuron within thehidden layers
ofthe network arefeature detectors.
The
learning
process
for
theselayers
is
complicatedby
thefact
that all the other neuronsare also changing at the same time.
Each
neuron within thehidden
layers
only see
its
owninputs
and the error signal propagatedback
toit from
the nextlayers.
The
error signal that thehidden
neuronis
attempting tofocus
in
onis
constantly changing, therefore causing thehidden
neurons to take along
time tosettlein
anddetermine
thedesired
local
minima.One
ofthedifficulties
with multi-layer perceptronsis
determining
thenumber of
hidden
neuronswithin thenetwork.The
number of neurons mustbe large
enough tobe
able toform
adecision
region thatis
suitablefor
thegiven problem.
Caution
mustbe
taken not tohave
too many neurons so thatthe number of weights required cannot
be
estimatedfrom
the availabletraining
data.
Prior
toCascade
Correlation,
theexperimenterhad
tofully
specify thenetwork architecture
before
thetraining
began.
It
was notknown
if
theCascade Correlation
combines twokey
elements tohelp
solve the"moving
target"problem.
The first
elementis
the cascade architecture.Using
thecascadearchitecture,
hidden
neurons are added tothe network oneat a time as
the
networkis
training.Once
a neuronhas been
added,its
input
synaptic weights arefrozen,
andonly
the weights associated withits
outputto theneuronconnectedto
the
nextlayer
are adjusted.The
second element addedwas an attemptto maximizethe magnitudeofthecorrelation
between
thenew neuron's output and theerror signalbeing
eliminated.
As
newhidden
neurons are added, each new neuron receives aconnection
from
all ofthe network's originalinputs
and alsofrom
all ofthepreviously added
hidden
neurons.This
is
a changefrom
previousarchitectures
in
which the neurons of onelayer
were only connected to theneurons ofthe next
layer.
The input
synaptic weights arefrozen
when thenew unit
is
added.An
example oftheCascade
architecture with twohidden
nodes
is
shownin Figure 10
2nd Hidden
Unit
Q_
1st Hidden/~N
Unit
C)
Input
+-Output
[image:29.552.193.394.367.518.2]66
Figure 10
The
networkbegins
with nohidden
neurons.The
networkis
trainedusing the quickprop algorithm until the error value reaches a minimum.
If
this value
is
acceptable, thetraining
is
complete.If
the error valueis
notacceptable, a new unit
is
added,its
input
weights arefrozen
and the outputconnection weights are then trained using the quickprop algorithm.
The
process continues again until the
training
is
acceptable, or another unitis
To
add anewneuron, the systembegins
with apool of candidate units.Each
ofthe
candidate neurons areinitialized
with adifferent
set of randominput
weights.All
ofthese
neurons receiveinput from
all ofthe
network'sinitial inputs
as well asfrom
all oftheexisting
hidden
neurons.The
outputsof
these
neurons are notyet connected to theremaining
network.A
numberofpassesover
the
training
data is
used toadjust theinput
weights.The
goalis
to maximizethe
magnitude of the correlationbetween
the new neuronsoutput and the residual error signal.
This
correlation(actually
co-variance)is:
where:
S
=2
I
X
(Vp
-V)
(EP)0
-E')
I
(Eq.
13)
o= networkoutput at which error signal
is
measuredp=
training
patternV
=candidateneuron output valueE0
= residual output error observed at neuron oV
=value ofV
averagedfor
allinput
patterns E'=value of
E0
averagedfor
allinput
patternsThe
correlation valueS
is
maximized using the quickproptraining
algorithm.
When
thetraining
is
completefor
the pool of candidate neurons(patience is
exhausted), theneuron with thelargest
correlationto the erroris
inserted
into
thenetwork.The
use of the candidate pool greatly reduces the risk ofinstalling
aneuron that was "untrainable".
It
allows the system totry
manydifferent
areas
in
weightspacetofind
agood solution.The
network architecture usedfor
thisThesis
wasCascade
Correlation.
The
systemhad
64
input
neurons with10
output neurons.The
64
input
neurons correspond to thefeature
vector extractedfrom
the originalpixel maps.
A
major purpose ofthefeature
extraction algorithm wasdata
compression.
If
thefeature
extractionhad
notbeen
run, theinput layer
ofthe network would
have had
256
neurons.The
10
output neurons correspond to the tendigits
0
through9.
have
one of the output neurons equal to +0.5 and the remaining9
outputneurons equal
to
-0.5.The database
of1200
handwritten digits
wasdivided into
two separatesets.
The first
set of600
was usedfor
training
ofthe network; the second setof
600
digits
was usedfor
testing.
The
originaldatabase
contained tenattempts
by
twelve
individuals
to write the tendigits.
The database
wassplit such that each set
(training
andtesting)
contained5
attemptsby
alltwelve
individuals
atwriting the tendigits.
The
training
of the network required345
epochs.An
epochis
onecomplete passthrough the
training
data.
Upon
completion, when there werezero errors, the
Cascade Correlation
algorithm addedonly2
hidden
neurons.Once
thenetwork wastrained,
the testdata
was used asinput
into
the network.For
eachinput
vector, the output of the network was recorded.This
included
whatinput
pattern was presented to the network, theclassification ofthe vector
by
thenetwork and the output valuefor
all oftheoutput neurons.
This
information
waskept for
usein
the next stage ofthesystem, thecontext
interpreter,
utilizingHidden
Markov Modeling.
The
network was able to correctly classify529
of the600
testfile
patterns
for
a success rate of88.2
percent.Specific details
describing
the3.3
Context Interpreter (Hidden Markov
Modeling)
The
third
andfinal
stage of oursystemis
the
contextinterpreter.
This
stage uses a
knowledge
aboutthe
dependencies between
the characterswithin the words to
help
determine
the correct classification of the words.This
stageis
addedto the
output ofthe neural network classifierbecause
to
date,
neural networks are notwell suitedfor
dealing
with time varyinginput
patterns and segmentationof sequential
inputs [12].
The
technique
for
modeling
the context ofthe wordsis
Hidden Markov
Modeling
(HMM).
This is
a statistical approachfor
modeling an observedsequence ofpatterns.
This is
in
contrast to other models that utilize syntaxand semanticstomodelthe context ofthe
desired
patterns.Hidden
Markov
Modeling
techniqueshave been
usedfor
speechrecognition problems
for
numerous years.There
are strong similaritiesbetween
speech recognition and character recognition, which makes the useof
Hidden
Markov Models
alogical
choicefor
optical character recognition.A
Hidden
Markov
Model
is
adoubly
stochastic process with anunderlyingstochastic processthat
is
notdirectly
observable(hidden),
but
canonly
be
observedthrough another set ofstochastic processes thatproduce thesequence of observed symbols
[13].
The HMM
is
a collection of states withinterconnecting
transition arcs.Associated
with each stateis
an observation probability.This
is
theprobabilityof
being
in
anygiven state at anygiventime.Associated
with thetransition arcs are transition probabilities.
These
define
the probabilities ofmoving
from
one statetoanother.In
terms of optical character recognition, the observation probabilitiesare
defined
as the probabilities that a specific objectis
representedby
thegiven
input
pattern.The higher
the probability, the more certain therecognition process
for
thatparticularpattern.The
transition probabilities aredefined
as the probabilities ofhaving
one character
follow
another character within the word.For
example,in
English,
thereis
ahigher
probability that the character "U" willfollow
thecharacter "Q" than the probability that the character
"Z"
will
follow
thecharacter"Q".
This
type ofmodelingcaneasilybe
expanded to provide global context,Depending
on the systembeing
modeled, the"a
priori"knowledge
thatis
required
is
sometimesdifficult
to
obtain.For
this
Thesis,
a singleHMM
was created and utilized.This
modelrepresented the entire
language.
The
transition probabilities werebased
onall of
the
wordsin
the
language.
An
alternative approach wouldhave been
to create a model
for
each word, then test the vocabulary against everymodel.
The
model that produces thebest
resultsis
interpreted
as the modelof the word
being
recognized.This
approach commonly usedin
speechrecognition.
Describing
and usingHMMs
requires thedefinition
of theformal
symbolic terms.
These
are shownin
Figure
11.
Also
shown,in
parenthesis,are the
descriptions
ofhow
these elements weredefined for
character wordrecognition.
The
variablesA,
B
andII are themost critical, sofor
compactness, theHMM
(X)
is
represented as afunction
ofthose threevariables:X
=(A, B,
n)
When
usingHMMs
to evaluate and model a specificdomain,
threeproblems must
be
solvedfor
the model tobe
useful.These
problems areevaluation,
decoding
and training.The first
problem, evaluation, statesthat,
given a model and asequence of observations, calculate the probability that the observed
sequence was produced
by
themodel.The
most straightforward approach to solving this problemis
the"brute force" method.
This
method calculates the probabilityfor
everypossible state sequence of
length
T.
This
procedure quicklybecomes
unfeasible as the number of states
(N)
increases
and thelength
of theobservation sequence
(T)
increases.The
number of calculations required todetermine
theprobabilityis
(2T
-1 )NTmultiplicationsandNT-1 additions.In
response to this problem, theforward-backward
algorithm wasdeveloped
[14].
With
this procedure, the probability of partial observationsup to a given state are calculated
from
thebeginning
of the model.Also
calculated
is
the probability of a partial observationback
to a given statestarting at the output of the model and working
back.
These
twoprobabilities are summed.
The
number of calculations requiredfor
thisT
=length
ofobservation sequence(
numberofdigits in
each word)
N
=numberofstates(
numberofdifferent
digits
available)
M
=number of observation sequences(
number ofoutputdigits
)
Q
={Qi>
Q2> >
Qd
individual
states(
individual digits
)
V
={v^,
. . ., vm}
discrete
set of possiblesymboloccurrences;
(
set ofdigits
0
through9
)
A
={a^ay,
statetransition probability(
probabilityonedigit
following
anotherdigit
)
B
=|bj(k)},
bj(k),
observationprobability
distribution
in
statej;
(
probabilityof aninput
vectorrepresentingeach specificdigit)
n
={t^},
7ti5initial
statedistribution
(
probabilityof eachdigit
being
thefirst
digit
of a word)
Figure
11
The
second problem,decoding,
states that given a sequence ofobservations, what was the optimal path through the model
(state
sequence)that produced the observation.
This
uncovers thehidden
portions of themodel.
The Viterbi
algorithm wasdeveloped
to solve thedecoding
problem [image:34.552.99.464.58.526.2]Viterbi
Algorithm
1.
Initialization
-Set initial
state values5i(i)
=nibi(01),
1
<;i
^N
^(i)
=0
2.
Recursion
Maximize
state sequenceFor2^t^T,
l<ij^N
8t(j)
=max[8t.1(l)Aij]Bi(Ot)for 1<i
<N
Yt(j)
= argmaxtS^DAy]forl^i^N
3.
Termination
-All
states
have been
traversed
P*
= max[8T(i)]
for
1 <li
<:N
i*T
= argmax[8T(i)]for
1^i
<N
4.
Backtrack
-Determine
optimal state sequence
For
t =T
-1,
T-2,
. . . , 1Figure
12The
algorithmfinds
the optimal state sequencefor
the observationsequence.
To determine
the optimal state sequence, the mostlikely
stateis
determined
at eachinstance in
time(t).
The
probabilityis
based
on theprobability of
being
in
the previous state(W(tl)(i)),
the transitionprobability
from
theprevious state to thecurrent state and the observationprobability
ofthe symbol
in
thecurrent state.This
value,(Vt(i)),
is
then maximizedfor
all [image:35.552.95.463.52.529.2]the
Viterbi
algorithm well suitedfor
dealing
with recognition andsegmentation.
The Viterbi
algorithm was usedfor
this
paper to selectthe
best
sequenceofstates
for
theobserved sequences.The
net result ofthisfunction
was
the
optimal state sequence.The
sequencewasinterpreted
asthe contextdirected
recognized word.The
state sequence corrected mis-classifieddigits
based
onthecontextknowledge
ofthe artificiallanguage.
The
third problem,training,
examineshow
to optimize the parametersofthe
HMM
so to maximize theprobability
of a given observation sequence.This
allowsfor
the
adjustment oftheHMM
tobest
suit thedomain.
This is
the mostdifficult
problem relating to theHMMs.
There is
noway to solve this problem analytically.
The Baum-Welch
algorithm wasdeveloped
as aniterative
technique[16]. The
threevariables(it,
A
andB)
arere-estimated, then evaluated.
If
the probability ofthe observation sequenceincreases,
then the new values are saved.The
algorithm guarantees thateither the probability
improves
or a critical pointhad
alreadybeen
reachedwherethe probability
had
alreadybeen
maximized.In
creating theHMM
for
this application, theinitial
probabilities(n)
used were the same probabilities used to generate the vocabulary.
These
probabilities are shown
in
Figure
3.
The
transition probabilities(A),
weredetermined
by
examining the vocabulary.The
transition probabilities areshown
in
Figure
13.
These
are slightlydifferent
than the transitionprobabilities used to generate the
language (see
Figure
4)
because
of0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0.122
0.00
0.00
0.122
0.073
0.073
0.073
0.073
0.122
0.341
0.047
0.116
0.116
0.047
0.116
0.023
0.047
0.047
0.419
0.023
0.000
0.059
0.353
0.00
0.00
0.00
0.00
0.500
0.029
0.059
0.082
0.082
0.000
0.061
0.143
0.061
0.449
0.061
0.00
0.061
0.154
0.115
0.038
0.038
0.077
0.423
0.115
0.000
0.038
0.000
0.094
0.062
0.031
0.062
0.312
0.156
0.062
0.094
0.062
0.062
0.000
0.034
0.034
0.661
0.017
0.000
0.000
0.119
0.119
0.017
0.094
0.000
0.469
0.000
0.094
0.062
0.125
0.031
0.062
0.062
0.032
0.355
0.032
0.032
0.194
0.0320.032
0.097
0.129
0.065
0.434
0.038
0.038
0.019
0.000
0.113
0.1510.000
0.00
0.208
Figure
13
The
observation probabilities(B)
usedfor
the model were generatedfrom
the neural network.The
output valuesfrom
each output neuron wererecorded
for
everyinput
vector.The
output values were thennormalized andused asthe observationprobabilities.
A different
set of observation probabilities were usedfor
each person'sattempt
in
writing the