ABSTRACT
CASSELL, KARA BRADLEY. Dynamic Generation of Narrative Discourse that Communicates Character Decision Making. (Under the direction of R. Michael Young and David Roberts).
This work describes a system, Ember, that is designed to generate visual discourses that contain cut-away visual sequences that explain character decision making. Cut-away shots are used in film and other visual discourses to direct the attention of the viewer to something else in relation the current context of the discourse. Examples of this discourse phenomenon are presented make use of cut-away shots that explain character decision making in films and graphic novels.
Ember builds off of prior research into discourse generation such as Darshak and IPOCL. It takes a narrative generation approach to discourse construction as opposed to focusing on low level camera/scene construction. Ember’s base algorithm is an artificial intelligence (A.I.) partial order causal link (POCL) planner. It makes modifications to this base algorithm to addreasoning about character decision making. It determines where in the discourse these cut-away shots should appear, as well as what content should be presented during the cut-cut-away. In addition, Ember makes used of a novel method to encode types of character decision making which can be used during A.I. POCL discourse planning.
© Copyright 2019 by Kara Bradley Cassell
Dynamic Generation of Narrative Discourse that Communicates Character Decision Making
by
Kara Bradley Cassell
A dissertation submitted to the Graduate Faculty of North Carolina State University
in partial fulfillment of the requirements for the Degree of
Doctor of Philosophy
Computer Science
Raleigh, North Carolina 2019
APPROVED BY:
Arnav Jhala Chris Martens
R. Michael Young
Co-chair of Advisory Committee
David Roberts
DEDICATION
BIOGRAPHY
ACKNOWLEDGEMENTS
I first would like to thank my advisor for the many years of guidance and mentoring. I’ve learned so much from being his student which reaches far beyond any academic successes I may have achieved. I would also like to thank Arnav Jhala whose help in the final years of my graduate studies were invaluable. Thanks to David Roberts for being an excellent teacher and co-advisor, and teaching me the importance of statistical rigor. James Lester, who was on my original committee, has been an amazing mentor and teacher. His artificial intelligence class is what originally inspired me to pursue this area of research. Robert St. Amant also originally served on my committee and was a great teacher who introduced me to LISP. Chris Martins stepped in at the last moment to save me and serve on my committee, and offer advice on how to handle my results.
I would like to thank the 2009 to 2019 Liquid Narrative Group graduate students, especially Julio Bahamon for being an excellent software development partner on the IC-Crime project. He was also there with me on many mock crime scene scanning excursions. Charles Bevan has been an amazing friend, fellow grad student, and co-worker/manager. He was always there, first in grad school, then at work, to help talk things out when I got stuck. Jim Thomas was also very helpful as a fellow graduate student, a manager, editor, and friend. Rogelio Cardona-River has been wonderful to work with, and I loved working on Indexter together. I would like to thank Stephen Ware, Brent Harrison, Matt Fendt, Justus Robertson, Adam Amos-Binks, and Colin Potts for being there to bounce ideas off of, co-write papers, be awesome guild mates, and great friends in general. I would like to Jeff Ligon who helped with the initial software engineering aspects of my system.
much for being my family.
TABLE OF CONTENTS
List of Figures . . . ix
List of Algorithms . . . .xiv
Chapter 1 Introduction . . . 1
1.1 Problem . . . 2
1.2 Narrative Discourse . . . 3
1.3 Using Shot Sequences to Manipulate Salient Facts . . . 5
1.4 Comics and Graphic Novels . . . 7
1.5 Computational Methods for Visual Discourse and DDRSs . . . 9
1.6 Ember . . . 10
1.6.1 Input . . . 12
1.6.2 Cinematic Construction . . . 12
1.6.3 Decision Points . . . 13
1.6.4 Decision Structures . . . 13
1.6.5 Action Labels . . . 14
1.6.6 Use of Decision Structures . . . 15
1.6.7 Structures in Discourse . . . 15
1.6.8 Informing the Visual Discourse . . . 15
1.6.9 Ember’s Output . . . 16
1.6.10 Comic Layout Generation . . . 16
1.7 Ember and DDRS Generation . . . 17
1.8 Empirical Evaluation . . . 18
1.9 Advancing the Work on Ember . . . 20
1.10 Overview of this Dissertation . . . 21
Chapter 2 Background and Related Work . . . 23
2.1 Narrative Generation . . . 23
2.1.1 Planning-Based Narrative Generation . . . 25
2.1.2 IPOCL . . . 29
2.2 Cinematic Discourse Generation . . . 31
2.2.1 Darshak . . . 34
2.3 Conveying Character Decision Making . . . 38
2.4 The Use of DDRSs in Film and Comics . . . 40
Chapter 3 Conveying Characters’ Decisions About Their Plans . . . 45
3.1 Ember System Architecture . . . 48
3.1.1 Discourse Step Decompositions . . . 49
3.2 Narrative Representations . . . 50
3.2.1 Action Labels . . . 50
3.2.2 Decision Types . . . 53
Chapter 4 Discourse Generation Example . . . 60
4.1 Input . . . 60
4.2 Discourse Generation . . . 63
4.3 Comic Panel Sequence Realization . . . 64
4.4 Example Decision Structures . . . 65
Chapter 5 Characterization of Ember’s Expressivity and Exploration of Em-ber’s Potential Impact on Comprehension . . . 73
5.1 Empirical Exploration of Ember’s Discourse Effects on Viewer Comprehension . 74 5.2 Experiment 1 . . . 74
5.2.1 Design . . . 74
5.2.2 QUEST . . . 76
5.2.3 Method . . . 81
5.2.4 Materials . . . 83
5.2.5 Participants . . . 89
5.2.6 Results . . . 91
5.2.7 Discussion . . . 94
5.3 Experiment 2 . . . 97
5.3.1 Design . . . 97
5.3.2 Method . . . 98
5.3.3 Materials . . . 99
5.3.4 Participants . . . 99
5.3.5 Results . . . 104
5.3.6 Discussion . . . 106
5.4 Experiment 3 . . . 110
5.4.1 Design . . . 111
5.4.2 Method . . . 111
5.4.3 Materials . . . 112
5.4.4 Participants . . . 113
5.4.5 Procedures . . . 114
5.4.6 Results . . . 116
5.5 Experimental Discussion . . . 119
Chapter 6 Conclusion and Future Work . . . .120
6.1 Conclusion . . . 120
6.2 Limitations of Ember . . . 122
6.3 Making Ember Brighter . . . 123
6.3.1 Story Generation . . . 123
6.3.2 Character Knowledge . . . 124
6.3.3 Simultaneous Story/Discourse Generation . . . 124
APPENDICES . . . .126
Appendix A Complete Film and Comics Examples . . . 127
A.2 Comic Corpus . . . 136
A.2.1 Scott Pilgrim . . . 138
A.2.2 Injustice . . . 141
A.2.3 Cowboy Bebop . . . 145
A.2.4 O Human Star . . . 148
Appendix B Experimental Domains . . . 155
B.1 Hero’s Problem . . . 155
B.2 Hero’s Domain . . . 156
B.3 Hero’s Decision Structures . . . 158
B.4 Philanthropist Problem . . . 159
B.5 Philanthropist Domain . . . 160
B.6 Philanthropist Decision Structures . . . 162
Appendix C Experiment 1 and 2 Hero Comic Artwork . . . 163
Appendix D Experiment 1 and 2 Philanthropist Comic Artwork . . . 174
Appendix E Experiment 3 Representative Images . . . 188
LIST OF FIGURES
Figure 1.1 A shot of Luke Skywalker looking at his hand [28]. . . 6
Figure 1.2 A close up shot of Luke looking at his hand [28]. . . 6
Figure 1.3 A shot of Vader’s arm [28]. . . 6
Figure 1.4 A close up shot of Luke’s face [28]. . . 6
Figure 1.5 A shot of Luke throwing his lightsaber away [28]. . . 6
Figure 1.6 A diagram showing the progressing of story events (blue), cinematic shots (purple), and foregrounding shots (green) in the Star Wars example. Or-dering links left out for simplicity. . . 7
Figure 1.7 Injustice [46] . . . 8
Figure 1.8 Ember System Architecture . . . 11
Figure 2.1 A shot of the council of Elrond arguing about what to do with the One Ring [18]. . . 41
Figure 2.2 Internal shot of Frodo gazing at the One Ring [18]. . . 41
Figure 2.3 A cut-away shot to the One Ring [18]. . . 41
Figure 2.4 A second internal shot of Frodo looking at the One Ring [18]. . . 41
Figure 2.5 A cut-away shot to the council of Elrond arguing about the One Ring [18]. 42 Figure 2.6 A second cut-away shot to the One Ring [18]. . . 42
Figure 2.7 A final internal shot of Frodo [18]. . . 42
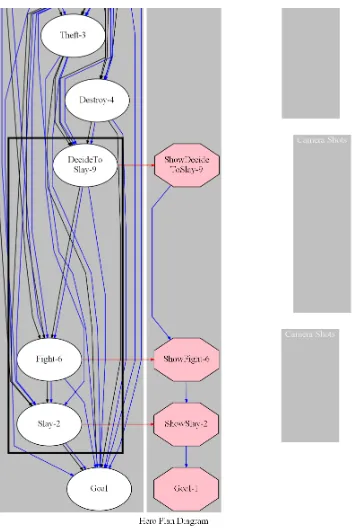
Figure 2.8 A shot of Frodo standing up saying he will take the One Ring to Mordor [18]. 42 Figure 2.9 A panel sequence showing Superman deciding to end conflict on Earth [46]. 43 Figure 4.1 Plan diagram input to Ember. . . 61
Figure 4.2 First open precondition repair. . . 64
Figure 4.3 Discourse step showSlay is linked to story step Slay2 . . . 65
Figure 4.4 Discourse step showDecidetoSlay is linked to motivating story step de-cideToSlay9 . . . 66
Figure 4.5 Discourse step showDecideToSlay is expanded based on a decision structure. 67 Figure 4.6 Final discourse plan with camera steps. . . 68
Figure 4.7 [7]. . . 69
Figure 4.8 [7]. . . 69
Figure 4.9 [7]. . . 69
Figure 4.10 [7]. . . 69
Figure 4.11 [7]. . . 69
Figure 4.12 Plan structure of how Ms Lovett decides to cook Sweeny Todd’s victims into her meat pies. A dashed line indicates there are other events between the connected events. A solid line represents a causal link. . . 70
Figure 4.13 [43]. . . 70
Figure 4.14 [43]. . . 70
Figure 4.15 [43]. . . 71
Figure 4.16 [43]. . . 71
Figure 4.18 [43]. . . 71 Figure 4.19 Plan structure of how Mark Watney comes up with a plan to reconnect
with NASA. A dashed line indicates there are other events between the connected events. A solid line represents a causal link. . . 71 Figure 5.1 The Czar and his Daughters story [17]. . . 77 Figure 5.2 QKS Structure for The Czar and his Daughters [17]. . . 78 Figure 5.3 Hero’s story graph. Nodes are plan steps, blue arcs are ordering links,
black are causal links. . . 85 Figure 5.4 Hero story QKS. Nodes are QKS event and goal nodes, arcs are QKS
consequence (C), Reason (R), Initiate (I), and Outcome(O) arcs. . . 86 Figure 5.5 Philanthropist story graph. Nodes are plan steps, blue arcs are ordering
links, black are causal links. . . 87 Figure 5.6 Philanthropist story QKS. Nodes are QKS event and goal nodes, arcs are
QKS consequence (C), Reason (R), Initiate (I), and Outcome(O) arcs. . . 88 Figure 5.7 Response distribution for the participants who read the Hero’s comic. . . 93 Figure 5.8 Response distribution for the participants who read the Hero’s comic. . . 93 Figure 5.9 Response distribution for the participants who read the Philanthropist
comic. . . 94 Figure 5.10 Response distribution for the participants who read the Philanthropist
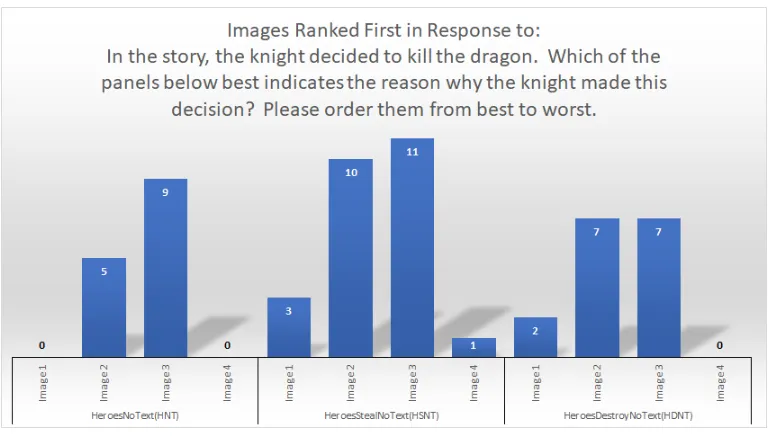
comic. . . 94 Figure 5.11 Image 1: Dragon Moving Ranked 1st Image 2: Dragon Destroying the
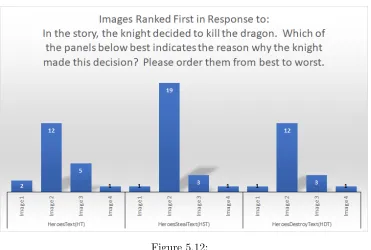
Town Ranked 1st Image 3: Dragon Stealing the Treasure Ranked 1st Image 4: Knight Slaying the Dragon Ranked 1st . . . 106 Figure 5.12 Image 1: The dragon moving to the village ranked 1st Image 2: The dragon
destroying the town ranked 1st Image 3: The dragon stealing the treasure ranked 1st Image 4: The knight slaying the dragon Ranked 1st . . . 107 Figure 5.13 Image 1: The philanthropist moving from the hospital to the orphanage
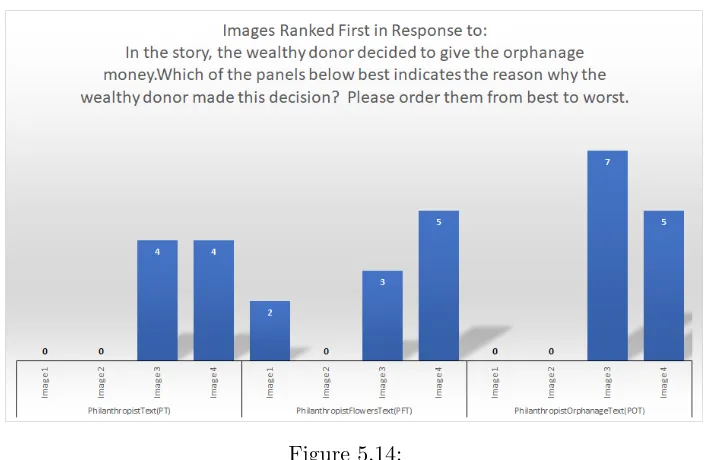
ranked 1st Image 2: The philanthropist awarding the grant to the orphan-age director ranked 1st Imorphan-age 3: The philanthropist seeing the orphanorphan-age in need of repair ranked 1st Image 4: The hospital director destroying the flowers ranked 1st . . . 108 Figure 5.14 Image 1: The philanthropist moving from the hospital to the orphanage
ranked 1st Image 2: The philanthropist awarding the grant to the orphan-age director ranked 1st Imorphan-age 3: The philanthropist seeing the orphanorphan-age in need of repair ranked 1st Image 4: The hospital director destroying the flowers ranked 1st . . . 109 Figure 5.15 Image 1: The monster moving to the castle ranked 1st. Image 2: The
monster destroying the castle ranked 1st. Image 3: The monster stealing the goblet ranked 1st. Image 4: The knight slaying the monster ranked 1st.117 Figure A.1 A shot of the council of Elrond arguing about what to do with the One
Figure A.3 A cut-away shot to the One Ring [18]. . . 128
Figure A.4 A second internal shot of Frodo looking at the One Ring [18]. . . 128
Figure A.5 A cut-away shot to the council of Elrond arguing about the One Ring [18].129 Figure A.6 A second cut-away shot to the One Ring [18]. . . 129
Figure A.7 A final internal shot of Frodo [18]. . . 129
Figure A.8 A shot of Frodo standing up saying he will take the One Ring to Mordor [18].129 Figure A.9 A shot of Treebeard, Merry, and Pippin [19]. . . 130
Figure A.10 A cut-away to the destruction of the forest [19]. . . 130
Figure A.11 Another shot of Treebeard, Merry, and Pippin, with Treebeard saying ”They had voices of their own” [19]. . . 130
Figure A.12 A cut-away to an industrialized Isengard [19]. . . 130
Figure A.13 A third shot of Treebeard, Merry, and Pippin with Treebeard saying ”A wizard should know better” [19]. . . 130
Figure A.14 A shot showing all of Treebeard letting out a warcry [19]. . . 130
Figure A.15 A fourth shot of Treebeard, Merry, and Pippin with Treebeard saying ”My business is with Isengard tonight” [19]. . . 131
Figure A.16 A final shot of Treebeard, Merry, and Pippin with Treebeard saying ”The Ents are going to war” [19]. . . 131
Figure A.17 A shot of Twilight working while Tomoe eats with his daughters [53]. . . 131
Figure A.18 A close up shot of Twilight looking at Tomoe and his daughters [53]. . . . 131
Figure A.19 A cut-away to Tomoe with the children [53]. . . 132
Figure A.20 A second cut-away to a close up of Tomoe looking at Twilight [53]. . . 132
Figure A.21 A second close up shot of Twilight [53]. . . 132
Figure A.22 A cut-away to Tomoe where she isn’t looking at Twilight [53]. . . 132
Figure A.23 A third close up shot of Twilight where he is slightly smiling [53]. . . 132
Figure A.24 A closer internal shot of Twilight Samurai slightly smiling [53]. . . 132
Figure A.25 A shot of Juno while she dances with Mark [40]. . . 133
Figure A.26 A shot for Juno starting to hug Mark [40]. . . 133
Figure A.27 A close up of Mark [40]. . . 133
Figure A.28 A cut-away shot of Juno hugging Mark [40]. . . 133
Figure A.29 A second close up of Mark [40]. . . 134
Figure A.30 A third close up of Mark as he tells Juno he is leaving Vanessa [40]. . . . 134
Figure A.31 A close up shot of Clipper [31]. . . 135
Figure A.32 A cut-away shot of a raindrop falling off of a leaf [31]. . . 135
Figure A.33 A second close up of Clipper [31]. . . 135
Figure A.34 A second cut-away to the raindrop falling again [31]. . . 135
Figure A.35 A shot of the raindrop turning into a fish [31]. . . 135
Figure A.36 A shot of nothing as the fish falls [31]. . . 135
Figure A.37 A shot of the fish with a bigger fish behind it [31]. . . 136
Figure A.38 Another shot of nothing [31]. . . 136
Figure A.39 A shot of the bigger fish eating the little fish [31]. . . 136
Figure A.40 A cut back to a shot of Clipper [31]. . . 136
Figure A.41 A final shot of Clipper [31]. . . 136
Figure A.43 A close up shot of Luke looking at his hand. [28] . . . 137
Figure A.44 A shot of Vader’s arm. [28] . . . 137
Figure A.45 A close up shot of Luke’s face. [28] . . . 137
Figure A.46 A shot of Luke throwing his lightsaber away. [28] . . . 137
Figure A.47 A panel sequence showing Scott thinking about Knives [35]. . . 139
Figure A.48 A panel sequence showing Scott thinking about Ramona Flowers [35]. . . 139
Figure A.49 A panel sequence where Ramona asks Scott to get her phone charger and Scott finds a letter to Gideon when getting the charger [36]. . . 140
Figure A.50 A panel sequence showing Superman deciding to end conflict on Earth [46].142 Figure A.51 A panel sequence showing the Flash beginning to doubt helping Super-man [46]. . . 144
Figure A.52 A panel sequence showing Faye Valentine realizing that a song may hold clues to finding her current bounty [52]. . . 146
Figure A.53 A panel sequence showing Faye Valentine realizing that her friends really are going to turn her over to the cops [52]. . . 148
Figure A.54 A panel sequence showing Alastair realizing the robots he is riding with look like ones he designed in his youth [5]. . . 150
Figure A.55 A panel sequence where the robots in the car discuss with Alastair how they are robots [5]. . . 151
Figure A.56 A shot sequence showing Alastair realizing he is a Robot [5]. . . 152
Figure A.57 A shot sequence showing how Alastair relaxes when working on the dancer [5].153 Figure C.1 Hero’s Comic Panel 1 . . . 163
Figure C.2 Hero’s Comic Panel 2 . . . 164
Figure C.3 Hero’s Comic Panel 3 . . . 165
Figure C.4 Hero’s Comic Panel 4 . . . 166
Figure C.5 Hero’s Comic Panel 5 . . . 167
Figure C.6 Hero’s Comic Panel 6 . . . 168
Figure C.7 Hero’s Comic Panel 7. This is included if this is the comic focusing on the dragon destroying the town. Not included otherwise. . . 169
Figure C.8 Hero’s Comic Panel 7. This is included if this is the comic focusing on the dragon stealing the treasure. Not included otherwise. . . 170
Figure C.9 Hero’s Comic Panel 7.5. This is included if this is a comic with a cut-away. Not included otherwise. . . 171
Figure C.10 Hero’s Comic Panel 8 . . . 172
Figure C.11 Hero’s Comic Panel 9 . . . 173
Figure D.1 Philanthropist Comic Panel 1 . . . 174
Figure D.2 Philanthropist Comic Panel 2 . . . 175
Figure D.3 Philanthropist Comic Panel 3 . . . 176
Figure D.4 Philanthropist Comic Panel 4 . . . 177
Figure D.5 Philanthropist Comic Panel 5 . . . 178
Figure D.6 Philanthropist Comic Panel 6 . . . 179
Figure D.8 Philanthropist Comic Panel 8 . . . 181
Figure D.9 Philanthropist Comic Panel 9 . . . 182
Figure D.10 Philanthropist Comic Panel 10 . . . 183
Figure D.11 Philanthropist Comic Panel 11. This is included if this is the comic fo-cusing on needs of the orphanage. Not included otherwise. . . 184
Figure D.12 Philanthropist Comic Panel 11. This is included if this is the comic fo-cusing on hospital director destroying the flowers. Not included otherwise. 185 Figure D.13 Philanthropist Comic Panel 11.5. This is included if this is a comic with a cut-away. Not included otherwise. . . 186
Figure D.14 Philanthropist Comic Panel 12 . . . 187
Figure E.1 Image of the monster looking at the castle. . . 188
Figure E.2 Image of the monster moving to the castle. . . 189
Figure E.3 Image of the monster destroying the castle. . . 189
Figure E.4 Image of the monster seeing the knight’s goblet. . . 190
Figure E.5 Image of the monster stealing the knights goblet. . . 190
Figure E.6 Image of the the knight attacking the monster. . . 191
LIST OF ALGORITHMS
Chapter 1
Introduction
The work described in this dissertation seeks to introduce reasoning about character decision making and cinematic expressivity into a visual narrative discourse generation system, with the goal of allowing the system to then produce discourses that support human narrative com-prehension and understanding of character decisions. An important aspect of story telling for human narrative comprehension ischaracter development. Specifically,character decision mak-ing is important in explaining the depth and characteristics of characters. Current narrative discourse generation systems do not directly take into consideration this character decision mak-ing. The visual discourse generatorEmber, developed as part of this dissertation, is a narrative discourse generation system that builds off of previous artificial intelligence planning methods. Ember has added functionality to previous approaches to discourse generation that can rea-son about character decision making to construct a discourse that can communicate character decision-making to the viewer.
viewer understand that the character is thinking. Cinematographers use specific shots, usually cut-away shots (shots that quickly cut to some other content and back), to explain what the character is thinking about. Cut-away shots help to break up otherwise long static shots, make the sequence more interesting, and display relevant information to the viewer or audience [2].
1.1
Problem
In the practice of making films, there are specific ways to communicate dialogue. One method is to use a master shot of characters speaking, a cut-away to show something they they are talking about, and then another master shot of the talking to continue the scene [2]. A cut-away shot breaks up longer shots, makes them more interesting, and provides relevant information to the audience [2]. This approach to shot sequence design has been observed during character decision making as well. One way to convey when a character is making an internal decision is to show them thinking. One ineffective way to show this decision-making process might be to use a long shot that provides little focus and detail on the character; this type of shot is not very interesting and does not provide the necessary information to the audience. When a character is making a decision, there is typically no visible way to show the subject of his or her deliberation directly by conveying the deliberating character’s physical activity. Using a cut-away implies that the content of the cut-away is relevant to the decision process. Therefore, a cut-away internal shot followed by another shot of the character is often used to imply the subject of the cut-away as the focus of the character’s deliberative process. For reference in this dissertation, I call this pattern of an internal shot, some number of cut-away shots, followed by another internal shot a reflective sequence. When the internal shots occur during a deliberation by the character being
filmed, and the content of each cut-away shows some aspects of the story world relevant to the deliberation, I call these shot sequences deliberation-driven reflective sequences, or
DDRSs. Thus we have the situation where a story-teller decides to use an initial shot of the
for which my work provides a cognitive/computational definition and for which the Ember system adds to the capabilities of visual discourse generation algorithms. However, one of the main problems Ember is faced with is deciding when to use this technique. Ember needs to be able to determine which decision to use this for, the reasons that the character made the decision, and how to film that reason.
1.2
Narrative Discourse
Visual and written narrative discourse have many similarities, both in how people comprehend and create them. Research in narrative comprehension for film tells us that the way people understand and store information presented to them by visual discourse is almost identical to the way that they store and understand written discourse [27]. In addition, the approaches people use to create visual discourse are very similar to those people use to create written discourse [6]. Authors and directors either intuitively or explicitly create discourse structure to accurately communicate story information. While film and written narrative are similar in their structure, there are still differences. One such difference is how to communicate internal character decision making. To communicate the character’s decision making, the author can write out an internal monologue of the character or explicitly explain their thought process. In film, however, these methods do not always work as well. In film, communicating character decision making or thought can be done using voice-over narration, as if the character were narrating their thoughts to the audience, but this can feel clunky or awkward. What directors and cinematographers often do instead is use special camera shots to make more clear what the character is thinking about. This can follow the master shot, cut-away shot, master shot sequence that was discussed earlier.
redundant content [48], or information that has already been presented to the viewer. In this case, these special shots are used to foreground or make salient prior information about the story to help explain a character’s thought process.
There are many examples of this technique in comedies, fantasy epics, dramas, and other genres. as well as across cultures. In the fantasy epic Lord of the Rings: The Two Towers[19], a shot is used to show the destruction of the forest wrought by Saruman which explains why Treebeard decides to go to war. When the hobbits Merry and Pippin first meet the ent Treebeard he is very much against going to war with the evil wizard Saruman. Treebeard feels that it is not his war and that the other peoples of Middle Earth should deal with it. Treebeard then takes the hobbits to the edge of the forest where they will be safe and can begin their journey home. However, once Treebeard gets to the edge, he is met with landscape showing the utter devastation of the forest that has been wrought by Saruman. A shot first shows Treebeard’s reaction, then an extreme wide shot shows the forest’s destruction with Saruman’s tower (where Saruman lives) in the background, and a final shot shows Treebeard’s face change to that of determination. Treebeard then states that the ents will go to war, having completely changed his mind.
In the Brazilian drama City of God [31], the character Clipper has a vision early in the movie. Clipper is a member of a small gang called the Tender Trio who would frequently rob various people in the city. After they pull off a particular heist, they are running from the police and take refuge in a tall tree. There, we see a shot of Clipper’s face as he looks off into the distance. We then see a shot of a rain drop falling off of a leaf. Then another shot of Clipper’s face, and then another shot of the rain drop. This last shot of the rain drop turns into a shot of fish and then a gun shot. In the morning, Clipper announces that he has had a vision, that he has quit the gang and is returning to the church. This is an example of how viewers can be shown not just something in the world that the character is reflecting on, but a specific event that occurred in the character’s mind while making a decision.
These are just a few examples of how these shots are used in film, and they show that this technique is both cross-genre and cross-cultural.
1.3
Using Shot Sequences to Manipulate Salient Facts
In film, communicating character thought is often accomplished with carefully constructed shot sequences that include special shots to emphasize or foreground specific facts. When characters deliberate they can be thinking of past events or objects that have meaning which pertain to the decision they are currently faced with. Often, these previous actions or objects may not be salient in the viewer’s mind, thus if they are not made salient, a character’s decision on how to proceed may not be clear. One example is fromStar Wars: Return of the Jedi[28], when Luke Skywalker is confronting Darth Vader on the Death Star. This sequence is show in figures 1.1 through 1.5. Up to this point in the movie, Luke has decided not to kill Darth Vader; however, Darth Vader has just threatened to turn Leia, Luke’s sister, to the dark side. This threat has enraged Luke which has driven him to fight Vader with the clear intention of killing him.
Figure 1.1: A shot of Luke Skywalker looking at his hand [28].
Figure 1.2: A close up shot of Luke look-ing at his hand [28].
Figure 1.3: A shot of Vader’s arm [28].
Figure 1.4: A close up shot of Luke’s face [28].
Figure 1.5: A shot of Luke throwing his lightsaber away [28].
Figure 1.6: A diagram showing the progressing of story events (blue), cinematic shots (purple), and foregrounding shots (green) in the Star Wars example. Ordering links left out for simplicity.
1.4
Comics and Graphic Novels
novels, while still using dialog heavily, often will use panels only containing cut-aways to indi-cate what a character is thinking. Just like in film, these shots can be of objects, characters, or events that are relevant to the decision process of the character. These shots, like in film, serve to focus the reader’s attention on a specific story element that is important to the character’s decision. The following example is from the graphic novel Injustice [46].
At this point in the story, Superman’s girlfriend Lois Lane has been killed, and Metropolis, the city where they both live, has been destroyed by the Joker. Figure 1.7 shows Superman’s transition from being distraught about the death of Lois Lane and the destruction of Metropolis to being determined to control all of the evil in the world. The first panel shows a close up of Superman. The next panel is a cut away to news reports of various wars around the world. This indicates that Superman is thinking about all of the evil in the world. The third panel shows Superman making a decision about ending all of the evil in the world. And finally there is a panel of Superman’s actions based on that decision.
1.5
Computational Methods for Visual Discourse and DDRSs
Currently, researchers have developed methods of automatically generating both story lines and the visual discourses to convey these story lines. Various methods have been used to construct narrative worlds. Some use artificial intelligence planning such as DPOCL [54], IPOCL [42], and a system developed by Cavazza et. al. [10]. Other methods use various forms of narrative modeling and construction such as MEXICA [38], and Fa¸cade [29]. One method developed by Riedl and Young [42] is able to take into consideration intentions of characters when deciding which actions occur in a narrative. A cinematic generation system called Darshak [20] is able to construct a visual discourse based on a standard set of cinematic principles. None of these systems, however, were specifically developed to create cinematics with reflective sequences. Ember, however, is designed using a model of character knowledge to help inform decisions on what shots to use to specifically communicate what a character is thinking about when they make decisions in the narrative.
and events that happen in between. Planning methods are often effectively used to create when the initial state of a planning problem corresponds to the beginning state of a narrative world, the end state to be the desired ending state of a scene or story, and the actions of the planner’s library to the events that can happen within the story world. A planner looks at the end state and constructs a sequence of actions from its input library whose execution transforms the world into the desired goal conditions. The result is a structure that specifies the sequence of actions taken by characters in the story.
This method can also be used to create a sequence of shots or discourse actions that line up with the events in the story plan. In this planning-based view of cinematic discourse generation, the initial state contains the initial beliefs of the viewer about the story, the actions in the middle are discourse events such as camera shots or dialog fragments, and the end state specifies the beliefs of the viewer intended to be held at the end of the cinematic experience. Ember extends this approach to cinematic discourse generation by adding logic to reason in specific ways about how events may contribute to the adoption of new courses of action by a given character.
To reason about character decisions, Ember first needs to understand what the character knows when he/she is making decisions. In addition, it is important for Ember to know what information is important for describing why the character is making the decision. Then, to explain a character’s decision, Ember can foreground information that the character knows and is currently thinking about before it shows the actual decision that the character makes. In this manner, Ember creates sequences that have shots of a character, then cut-away shots of places or items that the character is thinking about that help explain the decision, then a shot of the character actually making the decision.
1.6
Ember
considered the goal state of the discourse planning problem. Before the discourse is watched, viewers are assumed to have an initial set of beliefs about the story. This is considered the starting state of the discourse planning problem. Construction of the discourse involves the arrangement of shots between the starting state and the goal state such that communication of the goal is achieved.
Ember itself is composed of sub-systems that handle different parts of the discourse con-struction as can be seen in Figure 1.8.
Ember takes in a story plan input and a planning domain. It then produces a discourse plan structure as output. This, along with comic panel layout information is used to produce a page layout for a comic that conveys the discourse. Finally, a content generation system uses the plan output and the page layout output to produce content for each panel. This produces the final comic strip output.
1.6.1 Input
As input, Ember receives a library of different types of camera shots. This library includes specifications of basic shot actions that film a particular type of thing, and of abstract shot actions that don’t specifically film anything but are said to communicate a more complex part of the discourse. These abstract shot actions will contain various combinations of basic and abstract shot actions that, when put together, will communicate a more complex part of the discourse. Ember will also receive a discourse planning problem specification which consists of the starting state and the goal of the viewer’s beliefs as well as the complete story plan that represents the actions in the story. The input story is used to inform the camera shots as to what they are supposed to film. The planning process of solving the input discourse planning problem is what drives Ember’s shot selection process.
1.6.2 Cinematic Construction
specification of what they should film.
1.6.3 Decision Points
When generating shot sequences to film the underlying story action, Ember specifically handles the filming of character decisions in the input story. If a shot added to the growing discourse uses a decision point in the story to determine what it should film, then Ember will specifically add additional shots so that the discourse will properly explain why a character is making this decision.
Decisions are modeled as themotivating stepsof frames of commitment (or intention frames) – explicit annotations in the input story plan that indicate the source of a character’s intention and all the actions in the story that the character intends in order to achieve a particular goal. Ember makes use of intention frames and the annotations indicating where and why in an IPOCL plan they arise in order to identify opportunities for DDRSs and what shot content should appear in any given DDRS. In IPOCL, intention frames indicate when a sequences of events is intended to happen by a character in the narrative. Motivating steps are steps that cause a character to commit to a goal and thus commit to the steps in an intention frame. This can be used as a parallel to a decision being made by the character if the character is the one initiating the intention.
1.6.4 Decision Structures
To characterize the range of decisions that can be conveyed in Ember using DDRSs, Ember uses a data structure called adecision structure. A decision structure is apattern of event types that a decision needs to have present in a story for it to make sense. For example, a decision
a decision structure, the structure would specify that any sequence that matched the structure must contain an event that causes something bad to happen to a character. It must also contain a later event where another character makes a decision to help them or not. These structures are much like sub-plans, except they are designed using only partial specification of matching requirements, so that the planner can match against a wide variety of events that can support the requirements of the structure.
1.6.5 Action Labels
For these structures to work, actions in a narrative must be categorized in some manner that indicates what role they can play in a decision structure. Many labeling schemes can be imagined that could be useful in this system. Specifically, it would be useful for the labeling scheme to represent attributes of events that represent information that humans use when making decisions based on these events. Creating a scheme that accurately models this decision making process could be quite complex. Humans use many different processes to inform their decision making. This includes information like how events affect physical things, including people, the emotions the events produce in person making the decision, the emotions they produce in other people, how the events have or could affect them and other people, as well as other processes. For this work, the scope has been restricted to broad information about an event. The simplifying restrictions are twofold:
1. The label of an event is relative to the elements involved in the event.
2. The label of an event is always true during the event.
1.6.6 Use of Decision Structures
Once these labeling schemes and decision structures have been written, they can both be used for narrative construction and discourse construction. An IPOCL planner can use the structures to ensure that specific types of actions are present in a narrative to support any given decision structure. Once an intention frame is created, the planner can choose what types of decisions exist by selecting decision structures that should be represented in the story. The planner can then add flaws to the plan that represent the need for the required event types from these decision structure. Then the planner would be free to add any events that fit the type needed for the decision structure.
1.6.7 Structures in Discourse
Discourse construction can search a story plan to determine what type of decisions are present in the narrative. If a discourse planner encounters an intention frame when looking at the events in the story it then knows that a decision exists. The discourse planner can then look at the other actions in the story plan to determine which decision types this intention frame fits. Give this, the discourse planner knows what other information in the story is relevant to the decision. Once this information is gathered, the discourse planner can add statements(in case of a text discourse), panels(in case of a comic discourse), or shots (in case of a film discourse) that support and explain the decision.
1.6.8 Informing the Visual Discourse
will become a separate sequence of actions that indicate more specific discourse actions. Any given decompositional discourse action may have multiple ways that it can be expanded. For example, an action that communicates a character deciding to help a wounded character could show how the character got hurt, or it could show the character asking for help, or it could show an event that made the deciding character a more empathetic person. All of this information could be contained in the decision structure, however not all of it may be necessary to be communicated. Decompositional discourse actions give a planner a straight forward way of structuring how to compose shot sequences based on the information present in the decision structure. In addition, this methodology allows for more decompositions to be added later.
1.6.9 Ember’s Output
Once Ember has finished discourse construction it will output instructions on how to sequence shots in a virtual environment to film the discourse. This output can then be used within a game world or other virtual environment to create a visual discourse explaining the input story. Ember specifically will use this information to construct comic panel sequences.
1.6.10 Comic Layout Generation
1.7
Ember and DDRS Generation
Ember uses motivating step reasoning with an IPOCL input plan to identify the types of decisions that are in this same input story. The goal of adding this reasoning to POCL discourse planning is to generate shot or panel sequences that identify the information relevant to the decisions in the input story. This information is identified by searching the input plan for various decision structures that are indicated by the decision library input. This requires that input plan steps be labeled with action labels to indicate how they can fit into a decision structure.
Decision structures are semantically-labeled templates characterizing aspects and types of decisions made by characters within a story. Decision structures are defined in terms of the action, intention and world-state structural elements of IPOCL plans.
The Ember discourse planning system is able to generate shot or panel sequences that include information about a character’s decision with these modification.
Ember’s use of a knowledge representation containing explicit encodings of action types and decision structures allows it to generate comic panel sequences that contain DDRSs. The intended capability of the system is to generate these DDRSs in a manner that increases the effective comprehension of the underlying story by a reader or viewer. My specific thesis in this work is:
Thesis. A system that leverages decision structures to drive DDRS insertion and content selec-tion can produce discourses that contain more expressive shot sequences that convey character
decisions than without DDRSs.
1.8
Empirical Evaluation
The primary contribution of Ember is the added expressivity that DDRSs bring to discourse generation. The goal of this expressivity is the added functionality to directly produce discourses that contain DDRSs. It is possible that a pure POCL planner could produce these discourses by happenstance. However, Ember’s additional reasoning, makes directly producing discourses with DDRSs for character decisions possible.
While Ember has increased discourse generation expressivity, it is still interesting to un-derstand how Ember’s discourses change the viewer’s unun-derstanding of characters’ decisions. Several experiments were run to attempt to measure how Ember’s discourses’ affect a viewer’s or reader’s understanding of character decisions.
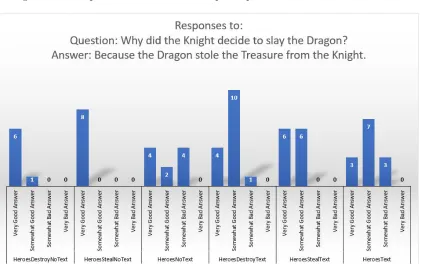
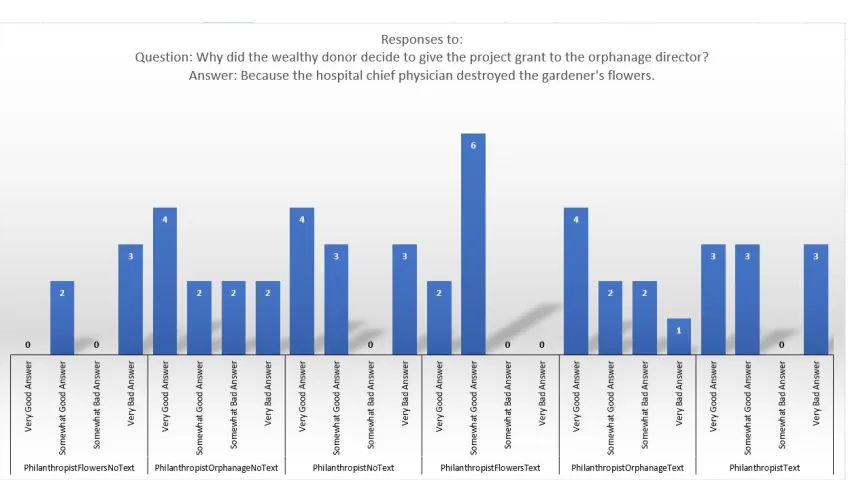
I ran two experiments to measure Ember’s effect on a reader’s comprehension of character decisions. The first experiment used a structure called a QUEST Knowledge Structure (QKS), a graph-based structure developed by cognitive psychologists [16] to characterize a reader’s model of story events used when answering questions about the story. The QUEST model defines a number of procedures for determining how appropriate one event is as an answer to a question about another event by characterizing the various paths between nodes associated with the two events inside the QKS.
subjects are presented with a pair of events, and asked to characterize how good the second event is as an answer to a specific question about the first event. For example, if two events from a story are the theft from a museum of an ancient dagger and a sale of the dagger to an illicit art collector, subjects might be given the question “Why did the thief steal the dagger” and the answer “In order to sell the dagger to the collector.” They would then rate the second clause as an answer to the first. Because the QUEST model provides a validated algorithm for providing these ratings given a QKS graph, I can use the QUEST ranking of a question-answer pair essentially as a gold standard for humans’ ratings. Differences, then, in how humans provide ratings can indicate variations in the arc search procedures they may be using to make GOA judgments.
In my experiments, subjects were asked to fill out a survey that contained question-answer pairs. Participants ranked how well each answer fit the question being asked on a four point scale from very bad to very good.
Informally, the hypotheses being evaluated by these two experiments were:
1. When asked goodness of answer questions about a character decision in a comic that has precisely two, equally distant supporting events in a QKS, participants who read an Ember-produced discourse of that comic that includes a DDRS explaining the character’s decision will assign higher values to answers that relate to the supporting event that was present in the decision sequence than to answers relating to the supporting event that was not present in the decision sequence.
2. When asked goodness of answer questions about a character decision in a comic that has precisely two, equally distant supporting events in a QKS, participants who read an Ember-produced discourse of that comic that includes a DDRS explaining the character’s decision will assign higher values to answers that relate to the supporting event present in the decision sequence than if they read a comic that did not include a DDRS.
panel rendering system). These experiments produced only limited support for Ember’s capa-bilities, with statistical significance, or near significance, in only a few cases.
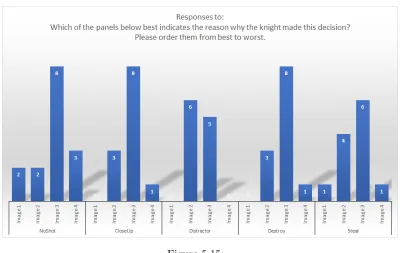
Several issues were identified in the first experiment’s design. One of these issues was that, while Ember produced comics that would highlight specific decision explanations, all of the story actions that explained the decision would be expected to receive rankings of very good based on the QKS. Therefore, it is not surprising that significance was not produced when each story action was tested alone. To deal with this, a second study was run, with the same comics, where the actions explaining the character’s decision were ranked with respect to each other and two other irrelevant distractor story actions. This produced results that did not show a significant difference between the treatment groups.
Other issues with the two experiments design include the story medium, structural issues with the stories themselves, and an inability of Ember to produce the desired narrative phe-nomenon. As described in more detail in Chapter 6, a planned experiment will seek to better control for these issues. This may first require preliminary studies to identify the specific re-sults of different presentation mediums, story structures, and decision structures. The methods already used to attempt to verify this work may not be sensitive enough to measure the dif-ferences in reader or viewer comprehension when character decision making is produced in this way. The goal of these proposed studies would be to verify that these methods do in fact measure this, that the methods Ember employs for character decision generation are not sophisticated enough, or that a new type of verification is required for narrative phenomenon of this type.
1.9
Advancing the Work on Ember
Ember can be extended in several ways. First, The labels used to categorize actions and the decision structures that use them can be broadened to encompass more types of decisions. The more labels that Ember understands, the more types of decision structures Ember can use in discourse generation.
extended to use more examples from comic theory (e.g., layout and design discussed by Mc-Cloud [30]). The current system used to render Ember output is quite limited geometrically. Expanding this to use more possible page layout would increase the types of comics Ember is capable of generating.
Another way to expand Ember would be to include other decision processes. For example, it’s common for emotion to play a role in the decision-making processes of characters Ember could be expanded to incorporate how actions with various labels affect different characters from an emotional perspective. This would require maintaining a model of each characters’ emotions [39, 1] and a model of how types of actions affect emotions which could change depending on personality type.
Ember currently generates comic book layouts and content. However, it would be straight-forward to extend this to produce full cinematics. Ember is currently agnostic to discourse medium, however the renderer would need to be modified to play out actions in a 3D world instead of rendering them to a static, 2D panel.
1.10
Overview of this Dissertation
Chapter 2
Background and Related Work
2.1
Narrative Generation
AI planning has been a popular method for narrative generation even with early systems. TALE-SPIN [23] is an early narrative generation system created by James Meehan that created short fables. The system approached narrative generation from a problem solving perspective. Individual characters had goals that the system would solve. These could be authored before hand, or created based on the selection of a target moral that the system should attempt to convey. The generated narrative was the result of solving all of the characters’ goals. To solve the goals, the system would have characters take actions which would change the world’s state. This could result in new goals that would then need to be solved.
AUTHOR [8] was another system that approached narrative generation from a problem solving perspective. Unlike TALE-SPIN, AUTHOR treated narrative generation from an au-thorial perspective instead of being character goal driven. Story actions were provided as input and AUTHOR attempts to create a narrative around them to justify them.
a high level authorial goal and decomposes it into goals. This process continues until sub-goals are decomposed into base events that can be told through character actions. These base events are driven by character goals. Thus, once a high level goal has been decomposed into base events, UNIVERSE then uses character goal reasoning to fill out the rest of the story. This way UNIVERSE attempts to balance the use of authorial goals and character goals in the generation of its narratives.
A system developed by Marc Cavazza et. al. [10] uses Hierarchical Task Network Plan-ning (HTN Planning) to model the set of actions characters can take in the narrative. HTN planning begins with an overall goal and then decomposes it into sub goals which are further decomposed into more sub goals. This process continues until sub goals are decomposed into primitive actions. Each goal/sub-goal may have multiple possible decompositions, or several different decompositions that are required. Cavazza et. al.’s system interleaves planning and plan execution so that it is able to produce an interactive narrative, or a narrative that arises from multiple characters attempting to solve their own goals. This is similar to the approach AUTHOR takes in that the overall narrative arise from the interaction of multiple characters solving their individual goals.
actions by how much they violate characters’ values, and by how that satisfying those results are based on the user model. In this way, IDTention is able to generate drama that results from characters needing or wanting to betray their moral beliefs.
Fa¸cade [29] is an interactive narrative generation system where the player is attending a dinner party with two non-player characters in the throes of a relationship break-up. The system generates the narrative by adding beats, or individual narrative components, to the story in response to the player’s actions. The beats are decomposed into specific character actions that are added to the story as play progresses.
MEXICA [38] generates narratives in a way that is modeled after the cycle of engagement and reflection in the creative writing process. This cycle iterates between an engagement phase, or story production, and a reflection phase, or evaluation and story refinement. MEXICA con-structs stories based off of prior story examples. It references these to select actions to add to the story during its engagement phase. During the reflection phase MEXICA measure unique-ness and interestingunique-ness by comparing the story to the prior stories it pulls actions from. These measure can then be used to guide further engagement phases. Once an action is selected, the system performs the action and updates the story-world context. This context is what is used to find stories to compare during the engagement phase. This process continues until the story is finished or an impasse is reached. If an impasse is reached the system enters the engagement phase and attempts to find alternative actions that can be used to resolve the impasse.
2.1.1 Planning-Based Narrative Generation
which must be true for the action to occur and a set of effects, which become true once the action has taken place. The planner then searches the space of actions that change the state from the beginning to the goal.
While this approach is not without flaws as a method for story creation (for instance, it ignores individual character knowledge and goal representations), its overall similarity to story construction is what makes it quite useful as a starting point for a narrative generation system.
2.1.1.1 Partial Order Causal Link Planning
Planning has been a sub-field of artificial intelligence for over 50 years [34, 15]. It is a method for creating a specification of a sequence of events that can change a given world state from a beginning state to an ending state. This beginning state and ending state specification is an example of a planning problem. A planning domain contains all of the possible actions that can be added to a plan that will solve the planning problem. An example of a planning problem would be to generate a plan that will move a person from their home to Paris, France. Here the beginning state has the person at their home and the ending state has them in Paris. Depending on the set of actions available the planner could accomplish this in many ways. A domain for this problem could include actions like fly that moves the person from one country to another, or drive that moves the person from their home to the airport. In addition to this, actions such as drive may require the person to have the keys to the car, so there would be an action to pick up the keys. To solve this particular problem the planner would create a plan that first has the person get their car keys, then drive to the airport, then fly to Paris. The granularity of the resulting plan that is generated is greatly dependent on the authored list of actions that are available to transition states of the world. Given these actions a planner can search through a space of world states by transitioning from one to the next by adding steps.
Planning then searches the space of possible states of the world. In POCL planning, planing begins with an empty plan that just has an initial state and ending state. New sub-plans can then be created by refining this plan by adding actions to support the ending state (or other actions previously added to a given sub-plan), or resolving conflicts. Here, nodes in the search space are partially constructed plans, and edges are refinements to these plans. Search can then be done through this space of plans to find a complete plan.
Planning has a very nice parallel to narrative construction in that it results in a sequence of events that transitions from a beginning to an end very much like the stories found in narratives. Because of this, planning is the foundation of the algorithms used to both construct a story and a discourse in this proposed work. The core approach to POCL planning used by Ember is discussed in more detail in the next section.
2.1.1.2 The POCL Algorithm
To make use of POCL planning stories must be represented in a planning structure. Narrative generation planning reasons about states of a story world and generates a plan, or sequences of actions, that transitions the story world from a beginning state to an ending state. As the planning process happens the planner searches through the space of possible plans that include different state transition combinations that can occur within a story world. Each node in this graph is a partially constructed sequence of events in the story world. The planning definitions used here are modified from those used for UCPOP [37].
Definition 1 (State). Astateis a single function-free ground predicate literal or a conjunction of literals describing what is true and false in a story world. Theinitial statecompletely describes the state of the story world at the beginning of the story. The goal state is a conjunction of literals which must be true at the end [37].
During the planning process a planner can choose a node at the fringe of the search space graph and add a step to it to generate the next node in the graph.
Definition 2(Operator). An operator is a template for an action that can happen in the story world. It is a tuple,< A, P, E, V >, whereA is the action type,P is the set of preconditions, or
literals that must be true for the operator to be used,E is the set of effects, or literals that become
true after the operator has been executed, andV is a set of variables used in the operator. [37].
An example of an operator is denoted below:
(action
:action-id move
:variables ?char ?start ?dest :preconditions (at ?char ?start)
:effects (at ?char ?dest) ¬(at ?char ?start) )
Definition 3 (Step). A step is an instance of an operator. It is a tuple, < P, E >, where P is the set of preconditions and E is the set of effects. If any variables exist in P or E they must
be bound to a constant [37].
When a step gets added, any variables from its operator need to get bound to predicates in the story world. Also, these steps need to be ordered correctly to maintain the integrity of the plan.Orderingconstraints are added to the plan to ensure the correct partial order of the plan.
Definition 4 (Ordering). An ordering of two steps, s and u, is denoted s < u, where s must be executed before u [37].
Definition 5 (Causal Link). A causal link is a data structure denoted by s −→p u, where s is a step with some effect p and u a step with some precondition p. A casual link explains how a
precondition of a step is satisfied, where p is true for u because smade it so. [37].
Causal links also allow checking for steps that negate a literal that supports a precondition of another step. When this happens the offending step must either be ordered after the two steps in causal link or ordered before the two steps in the causal link.
A POCL planning domain and problem are defined as follows:
Definition 6 (Planning Domain). The planning domain is the set of all operators. This de-scribes the type of actions that can be in the plan [37].
Definition 7(Planning Problem). The initial and goal states compose the planing problem for the planner [37].
A complete plan is a tuple containing all the steps, orderings, bindings, and causal links cre-ated during the planning process. The plan is complete if all steps have all of their preconditions satisfied and there are no steps that violate any causal links in the plan.
Definition 8 (Plan). A plan is a four-tuple hS, B, O, Li where S is a set of steps, B a set of variable bindings, O a set of orderings, and L a set of causal links. A complete plan is guaranteed to achieve the goal from the initial state. A plan is complete if and only if:
• For every preconditionp of every step u∈S, there exists a causal link s−→p u∈L. • For every causal link s −→p u ∈ L, there is no step t ∈ S which has effect ¬p such that
s < t < uis a valid ordering according to the constraints in O [37].
2.1.2 IPOCL
solely because they are needed to transition the state of the world to the goal state. To solve this problem, a POCL-style planner was modified to add intentionality to the planning process. This resulted in the Intentional Partial Order Causal Link (IPOCL) planner. With this method, every action is defined as one needing intention or not. If an action is added to a plan and it needs intention, then a new type of flaw is added along with it to insure that a step describing a character’s decision to make this action happen is included in the plan. In addition, this new action is included in a frame of commitment describing the character’s intention to make something happen. IPOCL plan structures are used as the input for the discourse generation algorithm described in this paper and is thus further discussed in the next section.
2.1.2.1 IPOCL Algorithm
IPOCL produces an AI plan that specifically models a story with events and orderings as well as the intentionality of characters that relate to each event in the story [42]. IPOCL builds off of the base POCL elements of planning including the states, operators, steps, orderings, causal links, problem and domains described in the previous section. IPOCL extends the methods that use these element by adding intentionality requirements to each operator. The definitions used below are taken or modified from the original IPOCL work [42].
Definition 9 (IPOCL Operator). An operator in IPOCL is the same as in POCL in that it is the base for an action that can occur in the world. Just like in PCOL, an IPOCL operator is
a tuple: hP, E, Ai. P is a set of preconditions andE is a set of effects. A is added for IPOCL and is a set of characters which must consent to the execution of the action [42]. An operator
for which A=∅ is called a happening. Happenings are not intended by any one character and represent accidents or the forces of nature.
Definition 10 (Motivating Step). A motivating step is a step that includes a modal predicate of the form indents(a, g). This indicates that the actor aintends to make hte literal g true.
Definition 11 (Final Step). Afinal step is the step in the plan that achieves the goal, g, from a particular motivating step.
Definition 12 (Frame of Commitment). A frame of commitment is a tuple, hS0, P, a, ga, sfi,
such thatS0 is a proper subset of plan steps in a planP =hS, B, O, Li,ais a symbolic reference to a character agent such that the character agent is the actor of all steps in S0, ga is a goal
that character agent a is pursing by executing the steps inS0, and sf ∈S0 – referred to as the
final step – has ga for one of its effects and all other steps in S0 temporally precede sf in the
step ordering O of plan P [42].
A plan in IPOCL includes all of the steps, bindings, orderings, and causal links of a POCL plan, but also includes a set of frames of commitment.
Definition 13(Plan). An IPOCLplanis a tuplehS, B, O, L, Ci whereS is a set of plan steps, B is a set of binding constraints on the free variables in the steps inS, O is the set of ordering
constraints on the steps in S, L is a set of causal links between steps in S, and C is a set of
frames of commitment [42].
Definition 14 (Complete IPOCL Plan). An IPOCL plan is complete if and only if (1) all preconditions of all plan steps are established, (2) all causal threats are resolved, and (3) all
plan steps that are not happenings belong to a frame of commitment [42].
2.2
Cinematic Discourse Generation
constraint solvers or intelligent agents [12, 4, 47, 14]. They usually use well-known cinematic constraints [32], such as the rule of thirds or not crossing the line, to guide camera shot selection. One such system is the one developed by Christianson et. al. [12] that encodes cinematic idioms, or standard sequences of shots, into a declarative camera control language (DCCL). Christianson et. al. made use of the standard ways of filming particular sequences of events in cinematography. The DCCL consists of fragments that encode camera positioning and orien-tation information. One or more fragments can then be used to construct shot sequences that resemble film idioms. Christianson et. al. then implemented a camera planning system (CPS) that produced a cinematic using the DCCL. It takes an animation trace as input that includes information about the location and activities of each character, and which characters need to be filmed at which times. The CPS produces a data structure called afilm treethat models the entire film as a tree structure. The CPS first breaks the film into sequences and then breaks those sequences into scenes based on the character activity information in the input animation trace. Next, the CPS matches the activities in each scene to idioms’ applicable activities. This process breaks each scene into candidate idioms. Candidate idioms are then broken down into candidate frames based on the DCCL encodings which indicate where to put the camera and where to point it. Finally, a heuristic evaluator is used to decide which candidate idioms best film the action they have been chosen for.
Christie and Normand [13] designed an interactive system which allows the viewer to see similar shots that are created based on cinematic principles. The system was intended to help 3D modelers better navigate a 3D virtual environment. 3D space is divided into semantic volumes that are tagged with information relevant to what cinematic principals they can portray. The system can search through these partitions to find the examples that best represent a particular scene given desired cinematic principals or constraints.
low level shot manipulation. Director Volumes are computed by constructing semantic volumes, or spaces in the world that represent specific cinematographic shot types, and then comparing them to a set of visibility constraints of objects for the particular area in the world. The system then reasons about the set of director volumes by running them through various filters to select an appropriate shot within a director volume for the given story content.
Louarn et. al. [26] designed a system that could determine both camera placement and blocking of actors and objects at the same time within a 3D space. It uses a language that defines relative positioning of elements for different shot types. The 3D space is simplified by using a 2D topographical abstraction. The space in this 2D version is then partition into geometric spaces based on the restrictions of the walls and objects in the scene. The system then uses pruning operators that are based on the constraints from the shot type language to remove locations within the space that do not satisfy the constraints. To find exact blocking solutions the system performs progressive sampling of location and rotation variables of the characters for the locations that are left after pruning.
Work by Wu et. al. [51] has created the Film Editing Patterns (FEP) language. This was designed to formalize standard cinematographic techniques and styles. The language specifies FEP constructs that constrain shot sequence features. The framing properties that can be included are actors’ size, the angle of the shot, the region where actors appear in the shot, and the number of actors within the shot. Shot relations are also described in FEP constructs. These include the size difference between shots, the angle change between shots, the region differences of the actors between shots, the specific actors that are in both shots, and how much continuity remains after shot transitions.
Cambot [14] is an off-line system that reads cinematic constraints from a script, and then generates cinematic sequences based on the information in the script. The script includes in-formation such as characters, actions, and temporal specifications. The script also includes location, blocking, view, and scene constraints. In addition to the script, Cambot makes use of hand-written cinematic domain knowledge. This bank of knowledge includes information on stages (or occlusion free areas), blockings (or geometric placements of characters), and types of shots that can be used for generating the cinematic. Cambot then searches through all valid blocking and stage combinations to find the best location on the sets. It then compiles the shots that are needed to cover each beat, or single action, in the script into reels. The reel with the highest score based on a ranking is then used.
Tomlinson et. al. [47] developed a system that uses an intelligent agent to film action within a virtual 3D space and is an example of a responsive system. Each virtual actor in the environment is able to tell the virtual agent how important it thinks it is and can request to be filmed. The virtual agent then responds to these reQUESTs and decides which character is the most important to film at any given time.
El Nasr [44] created a system which designs an entire visual experience as a whole. The system consists of three sub-systems that reason about characters, lighting, and camera move-ment. A director agent controls the actual characters, lighting, and camera based on what the sub-systems recommend. The sub-systems all propose various actions to fulfill a communicative goal to the director agent. The director agent then unifies these and resolves conflicts to main-tain visual consistency. It is also capable of adding actions to the list of proposed ones from the subsystems if needed.
2.2.1 Darshak
hierarchical structure uses abstract and base shots to encode cinematic principles. Darshak then uses a decompositional planner to create a shot sequence using these abstract shots and their decompositions into base shots.
Thus far we have discussed POCL planning as it is used to construct the story of a narrative. However, story is only one part of a narrative; narratives also need a discourse, or a method of telling the story to the audience. A discourse can be constructed in the same manner as a story: instead of story events, discourse events are used. These are actions that communicate specific information to a viewer about an event in a story. These can be thought of as speech acts, sentences, or camera shots. Darshak was created to make use of POCL planning to construct a discourse sequences that visually communicates a sequences of story actions given as input. The POCL planing algorithm had to be modified to take into consideration timing and discourse structure. Darshak is the basis for the algorithm described in this paper and is thus described in more detail in the next section. The definitions in the next section are taken from those used in the original Darshak work [20].
2.2.1.1 Darshak Algorithm
The Darshak system uses a hierarchical planning algorithm, DPOCL-T, to generate cinematics using primitive and abstract shots.
Definition 15 (Primitive Shot). A camera shot that defines a set of parameters for the cam-era [20].
Definition 16(Abstract Shot). A shot that is composed of primitive shots and defines abstrac-tions of primitive shots [20].

![Figure A.10:A cut-away to the destruc-tion of the forest [19].](https://thumb-us.123doks.com/thumbv2/123dok_us/1369663.1169708/146.612.92.292.354.438/figure-cut-away-destruc-tion-forest.webp)
![Figure A.26:A shot for Juno starting tohug Mark [40].](https://thumb-us.123doks.com/thumbv2/123dok_us/1369663.1169708/149.612.320.512.421.532/figure-shot-juno-starting-tohug-mark.webp)
