CSEIT1831210 | Received : 15 Jan 2018 | Accepted : 05 Feb 2018 | January-February-2018 [(3) 1 : 740-749 ]
International Journal of Scientific Research in Computer Science, Engineering and Information Technology © 2018 IJSRCSEIT | Volume 3 | Issue 1 | ISSN : 2456-3307
740
Efficient Scheduling of Scientific Workflows using Multiple Site
Awareness Big Data Management in Cloud
Bade Ankamma Rao
*1, Lingamallu Vakula Vahini
2*1Assistant Professor, Department of MCA, St. Mary’s Group of Institutions, Guntur, Andhra Pradesh, India 2PG Student, Department of MCA, St. Mary’s Group of Institutions, Guntur, Andhra Pradesh, India
ABSTRACT
The worldwide organization of cloud server farms is empowering expansive scale logical work processes to reinforce execution and convey fast reactions. This extraordinary topographical appropriation of the calculation is increased by associate enlargement within the size of the knowledge taken care of by such applications, conveyance of title new difficulties known with the effective info administration crosswise over destinations. High amount, low potentials or price-related exchange offs area unit solely one or two worries designed for along cloud suppliers and purchasers with regards to taking care of data crosswise over server farms. Existing arrangements are affected to cloud-gave capability, that offers low execution in lightweight of fixed costs plans. Thusly, work method engines necessity to form up alternates, accomplishing execution at the price of adverse framework setups, keep expenses, reduced solid quality and reusability. We have a tendency to gift Overflow, associate unchanging info administration framework for logical work processes running crosswise over topographically disseminated destinations, desiring to receive financial rewards from these geo-differing qualities. Our answer is condition aware, because it screens and representations the worldwide cloud framework, contribution extraordinary and expected info taking care of execution for exchange value and amount, within and crosswise over sites. Overflow suggests a meeting of pluggable administrations, assembled in an info scientist cloud set. They provide the applications the chance to screen the essential framework, to endeavor swish info pressure, reduplication, and geo-replication, to assess info administration expenses, to line an exchange off amongst cost and period, and enhance the exchange procedure consequently. The outcomes demonstrate that our framework will show precisely the cloud execution and to use this for adept info scattering, having the capability to reduce the money connected expenses and exchange time by up to 3 times.
Keywords : Big Data Management, Cloud Server, Higgsboson Disclosure, Google Cloud, Bio-Informatics, VM
I.
INTRODUCTION
The all around appropriated server farms cloud foundations empower the quick advancement of vast measure applications. Cases of such requests running as cloud administrations crosswise over locales run from office synergistic devices worldwide securities exchange examination devices to entertainment services and logical work processes. The majority of
II.
Problem Statement
The volume bridges single site or single establishment ability to collection or process, needful a framework that ranges above various destinations. This remained the situation meant for the Higgsboson disclosure, designed for which the handling was reached out to the Google cloud
foundation. Quickening the way toward
thoughtful information by dividing the calculation crosswise over locales has demonstrated viable likewise in different ranges, for example, taking care of bio-informatics issues. Such
Workloads commonlyinclude an immense number of factual experiments for attesting possible significant district of interests (e.g. connects amongst mind areas and qualities). This handling takes demonstrated to benefit significantly beginning transference crosswise over destinations. Other than the requirement for extra register assets, applications need to conform to a few cloud suppliers „requirements, which require them to be sent on geologically appropriated site.
Objective of the study
To begin with the administration use reduplication applications call the check reduplication (Data, Destination Site) capacity to confirm in the Metadata Registry of the goal site if (comparable) information as of now exist. The verification is done in view of the one of a kind ID or the hash of the information. On the off chance that the information be present, the exchange is supplanted through the report of the information at goal.
This takes the greatest additions, together period and cash insightful, amongst entirely density strategies. On the other hand, if the information exist not officially display at the goal site, their
mass can even now conceivably be decreased by relating pressure calculations. Regardless of whether to invest energy and assets to put on such a calculation and the determination of the calculation herself are choices that we permission to clients, who identify the request semantics.
We will likely make exact estimations however in the meantime to stay nonexclusive with our model, paying little respect to the followed measurements or the earth changeability. The administration supports client educated pressure related choices, that is, compression– time or compression–cost pick up estimation.
Scope of the study
The multi-site cloud is comprised of a few topographically circulated server farms. An application that has numerous running occasions in a few organizations over different cloud server farms is alluded to as a multi-site cloud application. Our concentrate is on such applications. In spite of the fact that applications could be conveyed crosswise over sites having a place with various cloud sellers they existavailable of the extent of this work.
III.
METHODS AND MATERIAL
Transforming geo-differences into geo-repetition requires the information or the condition of uses to be dispersed crosswise over locales. Information developments are period and asset expending and it is in efficient for applications to interrupt their principle calculation with a specific end goal to perform such operations.
Applications show the information to be motivated and the goal by means of an API work appeal, i.e., Duplicate (Information, End). At that point, the
administration plays out the geological
outcomes for various enhancement systems. By utilizing the beforehand presented benefit for evaluating the cost, the georeplication service can improve the process for price or implementation period. To this reason, applications are furnished with a discretionary restriction when do the capacity. By differing the estimation on this subject parameter in the section of zero and one, applications resolve demonstrate a greater heaviness for rate (i.e. an estimation of 0) or for period (i.e. an estimation of 1), which thus will decide the measure of assets to usage for repeating the information. This remains finished by questioning the cost estimation benefit for the base in addition extreme circumstances, the particular price forecasts, and after that utilizing the arrangement guideline as a slider to take in the middle of them.
IV.
LITERATURE SURVEY
In this paper an alternative utilizing information region in the course of direct record exchanges flanked by the register hubs. The framework for document administration was harmonized inside the Microsoft Non explicit Specialist work process motor and was approved utilizing engineered benchmarks and indisputable appliance on the Purplish blue cloud [1].This system actually deals with the e-Science project ventures for inventory purpose. It provides cloud service types for logical information administration, investigation and cooperation. It is a versatile
Framework and can be conveyed on both private and open mists. This paper portrays the plan of e-SC, its API and its utilization in three distinctive
contextual analyses spirit information
representation, medicinal information catch and examination, and invention holdings anticipation [2].In this proposed system we are portraying the WAS trade in worldwide and show the information in sequence order, as we bring in the underlying plan and model discharge of Stork
Cloud, and reveal its viability in huge information contacts cater-cornered over topographically removed capacity destinations, server farms, and teaming up foundations[3].Writing study is fundamental visit to investigate the issue area and handle top to bottom learning on related field, which can be necessary discovery to get worry of the current problem. In the region of massive framework improvement, we need to direct different prerequisite assembling to know the issue legally. Be that as it may, genuine test starts when we need to settle on tools and developments which could suit best to take care of the proposed issue [4].Writing study helps us to discover the likely most proficient way to address the issue, which would just not tackle the issue, but rather in a productive and least demanding conceivable way [5].
V.
Existing System
The handiest alternative for dealing with information disseminated over a few data centers is to depend on the current distributed storage
administrations. This approach permits to
exchange information between subjective
endpoints by means of the distributed storage and a few frameworks with a specific end goal to oversee information developments over wide-zone systems receive it.
The issue of booking information concentrated work processes in mists accepting that records are recreated in different execution sites.
Then again, end-framework parallelism can be misused to enhance usage of a private way by methods for parallel streams or simultaneous exchange. Be that as it may, one ought to likewise consider framework design since particular nearby imperatives may present bottlenecks. One problem with every one of these methods is that they cannot be ported to the clouds; meanwhile they definitely depend on the fundamental system topology, obscure at the client level.
Disadvantage:
These existing works cannot decrease the economic cost and exchange time.
VI.
Proposed System
In this framework, we propose Overflow, a completely mechanized single and multi-site programming framework for logical work processes information administration.
We propose an approach that improves the work process information exchanges on mists by methods for versatile exchanging between a few intra-site record exchange conventions utilizing setting data.
We construct a multi-route exchange approach crosswise over middle hubs of different data centers, which total transmission capacity for proficient between destinations exchanges.
Our proposed work can be utilized to boost huge scale work processes through a wide procedure of pluggable administrations that scale and enhance prices, provide bits of information on the earth execution and allowsmoothinformation pressure, reduplication and geo-replication. costs and exchange time by up to three times.We can also know distance between the Virtual Machine when sending the file one virtual machine to another.
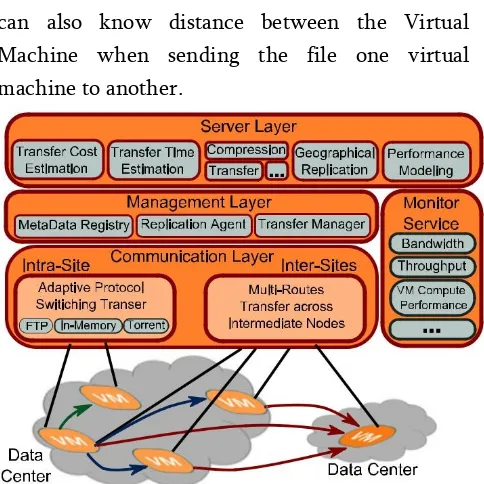
Fig. 1. The extendible, server-based architecture of the Overflow System.
Architecture
The conceptual scheme of the layered architecture of Overflow is presented in Fig. 1. The system is built to support at any level a seamless integration of new, user-defined modules, transfer methods and services. To achieve this extensibility, we opted for the Management Extensibility Framework, 1 that allows the creation of lightweight extensible applications, by discovering and loading at runtime new specialized services with no prior configuration.
service. The top (server) layer exposes a set of functionalities as services (see Section 4). The services leverage information such as data placement, performance estimation for specific operations or cost of data management, which are made available by the middle layer. This information is delivered to users/applications, in order to plan and to optimize costs and performance while gaining awareness on the cloud environment.
The interaction of Overflow system with the workflow management systems is done based on its public API. For example, we have integrated our solution with the Micro-soft Generic Worker [12] by replacing its default Azure Blobs data management backed with Overflow. We did this by simply mapping the I/O calls of the workflow to our API, with Overflow leveraging the data access pattern awareness as fuehrer detailed in Sections 5.6.1, 5.6.2. The next step is to leverage Overflow for multiple (and ideally generic) workflow engines (e.g., Chiron [13]), across multiple sites. We are currently working jointly with Microsoft in the context of the Z-Cloud Flow
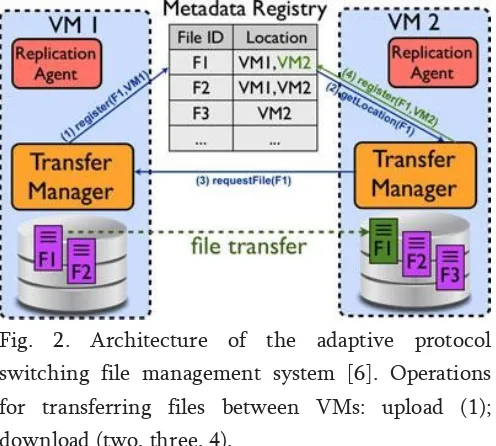
Fig. 2. Architecture of the adaptive protocol switching file management system [6]. Operations for transferring files between VMs: upload (1); download (two, three, 4).
Management services to process highly distributed workflows orchestrated by multiple engines.
Intra-Site Transfers via Protocol Switching
In a first step, we focus on intra-site communication, leveraging the observation that workflow tasks usually pro-duce temporary files that exist only to be passed from the job that produced them to the one further processing them. The simplified schema of our approach to manage such files is depicted in Fig. 2. File sharing between tasks is achieved by advertising file locations and transferring the file towards the destination, without intermediately storing them in a shared repository. We introduce 3 components that enable file sharing across compute instances:
The Metadata Registry holds the locations of files in VMs. It uses an in-memory distributed hash-table to hold key-value pairs: file ids (e.g., name, user, sharing group etc.) and locations (the information required by the transfer module to retrieve the file). Several implementation alter-natives are available: in-memory databases, Azure Tables, Azure Caching. We chose the latter as our preliminary evaluations showed that the Azure Caching delivers bet-ter performance than the Azure Tables (10 times faster for small items) and have a low CPU consumption footprint (unlike a database).
transfer modules and their service counter parts, deployed on each compute instance. Building on the extensibility properties, users can deploy custom transfer modules. The only requirement is to provide an evaluation function for scoring the context. The score is computed by weighting a set of parameters, e.g., number or
Size of files, replica count, resource load, data format, etc. These weights reflect the relevance of the transfer solution for each specific parameter. Currently, we provide three protocols among which the system adaptively switches:
In-Memory: targets small files transfers or deployments, which have large spare memory. Transferring data directly in memory boosts the performance especially for scatter and gather/reduce access patterns. We used Azure Caching to implement this module, by building a shared memory across the VMs.
FTP: is used for large files that need to be transferred directly between machines. These solutions are mostly suited for pipeline and gather/reduce data access pat-terns. To implement it we started from an open-source implementation [15], adjusted to fit the cloud specificities. For example, the authentication is removed, and data is transferred in configurable sized chunks (1 MB by default) for higher throughput.
Bit Torrent: is adapted for broadcast/multicast access patterns, to leverage the extra replicas in
collaborative transfers. Hence, for scenarios
involving a replication degree above a user-configurable threshold, the system uses Bit Torrent. We rely on the Monitor-rent [16] library, again customised for our needs: we increased the 16 KB default packet size to 1 MB, which translates into a throughput increase of up to five times.
The replication agent is an auxiliary component to the sharing functionality, ensuring fault tolerance across the nodes. The service runs as a background process within each VM, providing in-site replication
functionality along side with the geographical replication service, described in Section 4.2. In order to decrease its intrusiveness, trans-fers are performed during idle bandwidth periods. The agents communicate and coordinate via a message-pass-ing mechanism that we built on top of the Azure Queuing system. As a future extension, we plan to schedule the replica placement in agreement with the workflow engine (i.e. the workflow semantics).
Inter-Site Data Transfers via Multi-Routes
In a second step, we move to the more complicated case of inter-site data transfers. Sending large amounts of data between two data enters can rapidly saturate the small interconnecting bandwidth. Moreo connections between the data enters are not always the fast-est ones. This is due to the different ISP grids that convert, due to the high latency between sites, switching the transfer protocol as for intra-site communication is not enough. To make things worse, our empirical observations showed that the direct nect the data enters (the interconnecting network is not the property of the cloud provider). Considering that many Big Data applications are executed on multiple nodes across several sites, an interesting option is to use these nodes and sites as intermediate hops between source and destination.
Meta Data Registry
It contains the positions of records in virtual machine.
It makes use of memory and the table contain document identification name (e.g., title, client distribution group etc.) and areas.
Replication Agent
The benefit keeps running as a foundation procedure inside each VM.
In-Memory
It targets little documents exchanges or arrangements, which have vast extra memory.
Module Description
In my project, there are Four Modules
1. Cloud Formation
2. Upload File & File Request 3. Multipath Selection
4. Smart data Compression & Replication
Cloud Formation
Now this section, we frame the cloud. At this point, we produce single cloud specialist co-op. The situation screens site subtle elements, pragmatic machine points of interest, information register and transmission period.
We create locales. All site takes interesting identification then associate through cloud service provider. The situation sees neighbour site indirect elements.
At that point, we create pragmatic machine. At this
time all pragmatic machine takes special
identification at that moment associate by alluring site. This one sees neighbour pragmatic machine points of interest.
Upload File & File Request
In this module, each VM can transfer a record into its own particular stockpiling. These subtle elements are put away in information register.
If another VM need to get to this record, he sent the document demand to Source VM.
Multipath Selection
In this module, the source pragmatic machine needs toward lead record addicted to goal pragmatic machine.
Toward diminish price and exchange period, this one need pick most brief way among basis pragmatic machine toward goal pragmatic machine.
Therefore, it finds the Multipath utilizing Multipath Selection calculation then locates the briefest way.
Smart data Compression & Replication
Big information size is too huge. In the event that any source VM send this huge information to goal, its cost and exchange time is expanded. To handle this issue, we should pack this huge
information to little information. Therefore, we apply perceptive information pressure strategy. Finally, the source VM reproduces its keen
packed information to goal VM.
Figure 2: Screen Shots Shows Cloud Service Provider
ENTER SITE ID
DISPLAY SITE-1(DATA CENTER-1)
Figure 4: Screen Shots Shows Display site-1(Data center-1)
SITE-1 CONNECTED SUCCESSFULLY (DATA CENTER-1)
Figure 5: Screen Shots Shows Site-1 connected Successfully (Data center-1)
ENTER VIRTUAL MACHINE ID
Figure 6: Screen Shots Shows Enter Virtual Machine id
DISPLAY VIRTUAL MACHINE-1
Figure 7: Screen Shots Shows Display Virtual Machine-1
SITE-1 CONNECTED VIRTUAL MACHINE-1
Figure 8 : Screen Shots Shows Site-1 Connected Virtual Machine-1
ENTERED SITE ID OF VIRTUAL MACHINE-2
UPLOAD DATA INTO OWN DATABASE VM1
Figure 10: Screen Shots Shows Upload data into own database VM1
Figure 11: Screen Shots Shows File request has been sent from VM-2 to VM-1
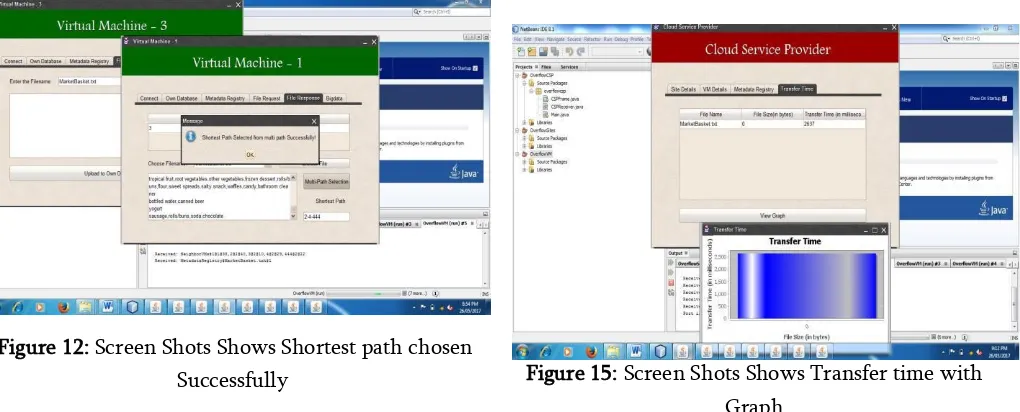
SHORTEST PATH CHOOSEN SUCCESSFULLY
Figure 12: Screen Shots Shows Shortest path chosen Successfully
CSP SHOWS DETAILS
Figure 13: Screen Shots CSP Shows details
FILE REQUEST HAS BEEN SENT FROM VM-2 TRANSFER TIME DETAILS TO VM-1
Figure 14: Screen Shots Shows Transfer time details
TRANSFER TIME WITH GRAPH
VII.
CONCLUSION
The project presents Over-Flow, an information administration system for logical work processes running in huge, physically spread and extremely
powerful conditions. Our framework can
successfully utilize the rapid systems associating the cloud server farms through advanced convention fine-tuning and blockage shirking, whereas outstanding non-meddlesome and simple to convey. Over-Flow exists utilized as a part of generation on the Azure Cloud, as an information administration backend for the Microsoft General Operative work process motor.
VIII.
REFERENCES
[1]. Prof. R. Tudoran, A. Costan, R. R. Rad, G. Brasche, and G. Antoniu,"Adaptive file management for scientific workflows on the azure cloud," in BigData Conference, 2013, pp. 273-281.
[2]. H.Hiden, S. Woodman, P.Watson, and J.Cała, "Developingcloud applications using the e-science central platform." In Proceedings of Royal Society A, 2012.
[3]. B. e. a. Calder, "Windows azure storage: a highly availablecloud storage service with strong consistency," in Proceedings of the Twenty-Third ACM Symposium on Operating Systems Principles,ser. SOSP '11, 2011, pp. 143-157.
[4]. T. Kosar, E. Arslan, B. Ross, and B. Zhang, "Storkcloud:Data transfer scheduling and optimization as a service," in Proceedings of the 4th ACM Science Cloud '13, 2013, pp. 29-36. [5]. N. Laoutaris, M. Sirivianos, X. Yang, and P.