International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 9, Issue 10, October 2019)
94
Anomaly Detection in Computer Networks By using Machine
Learning Algorithms
Md Riyaz Ansari
1, Dr. Bhupesh Gour
21M.tech Scholar, 2Professor & Head, Department of CSE , LNCTS, Bhopal, India
Abstract— The network security is becoming an essential need of modern society to protect the confidential information flowing over the networks. Detection of Intrusion over the network is one the most extremely important task to prevent their unlawful use by the attackers [1]. Efficient intrusion detection is needed as a defense of the network system to detect the attacks over the network. A feature selection and classification based Intrusion Detection model is presented, by implementing feature selection, the dimensions of NSL-KDD data set is reduced then by applying machine learning approach, we are able to build Intrusion detection model to find attacks on system and improve the intrusion detection using the captured data. In this paper we perform experimental result by using NSL-KDD cup 99 Dataset to train our model based on various machine kearning Algorithm and then calculate the accuracy of the classifier model.
Keywords: Intrusion Detection, Anomaly detection, network security, Random forest, SVM, KNN, Data mining algorithms.
I. INTRODUCTION
Intrusion Detection Systems are commonly categorised into misuse detection and anomaly detection. The misuse detection system refers to well-known attacks that exploit the system. they will match the pattern on single events or multiple mixtures of events. Anomaly detection refers to model the applied math information concerning traditional activity. Intrusions correspond to deviations from the traditional activity of system. the most challenge in anomaly detection IDS is that the problem in process the traditional activity due to the high variability in nominal usage. The false positive/ negative alarm rate in anomaly detection is high, compared to misuse detection systems. However, the anomaly detection is simpler in detective work new attacks or deviation from the nominal usage. The IDS is additionally classified supported the info source: Network IDS (NIDS) and Host-based IDS (HIDS) systems. The NIDS watch network traffic sometimes from one location or network interface. Therefore, NIDS will observe probes ,scans, malicious and abnormal activity across the full sub network. It's conjointly effective in characteristic general traffic patterns for network and troubleshooting network issues.
Its status to come up with false alarms, still as its inability to observe false negatives is its inherent weakness. HlDS technology doesn't have the advantages of looking at the network to spot patterns like NlDS will. Instead, it watches the traces to access servers through the log knowledge. a mix of host and network intrusion detection systems, within which a NlDS is placed at the network in an HlDS at essential servers, is that the best thanks to considerably scale back risk. Current intrusion detection systems are unsuccessful to deal with new, elegant and structured attacks, thanks to sever sensible and theoretical limitations. These limitations have lead several researchers to use totally different machine learning approaches for detective work anomalies.
II. LITERATURE REVIEW
According to (Yaping Chang et al., 2017) [1], The network intrusion detection techniques are important to prevent our system and network from malicious behaviors. In order to improve accuracy of network intrusion detection, machine learning, feature selection and optimization methods have been used, and the result tell us that the combination of machine learning and feature selection can improve accuracy. In this study, we developed a new machine learning approach for predicting network intrusion based on random forest and support vector machine. Since there were many potential features for network intrusion classification, random forest were used for feature selection based on variable importance score. We found that the host-based statistical features of network flow play an important role in predicting network intrusion. The performance of the support vector machine which used the 14 selected features on KDD 99 dataset has been evaluated by comparing it with the total(41) features and popular classifiers. The result showed that the selected features can achieve higher attack detection rate and it can be one of the competitive classifier for network intrusion detection.
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 9, Issue 10, October 2019)
95
Cubic centimetre is taking part in a significant role in several fields like Finance, life science and in Security. associate degree IDS is primarily used for defense of network and knowledge system. It monitors the operation of host or a network. IDS monitors network of computers for attacks that ar geared toward stealing info. Applying cubic centimetre may result in low warning Rate and high detection rate. during this paper, we tend to study varied cubic centimetre algorithms that ar wont to develop IDS. From the comparison the gap for developing economical IDS are going to be reached.
According to (Chidananda Murthy Pet al, 2016) [3], Intrusion is one in all the foremost serious issues with network Security, as new forms of intrusions are becoming far more difficult to notice. great deal of network traffic has been generated thanks to the utilization of internet; most of the generated traffic is within the format that can not be used on to reach meaty info. The cleansing and labeling of knowledge when wants a substantial quantity of human effort, and is time overwhelming. during this paper Semi supervised machine learning technique are often employed in intrusion detection, for each tagged and unlabelled knowledge. within the projected technique we tend to take alittle quantity of tagged knowledge to make model and victimisation this model we tend to show the way to predict the unlabelled traffic. Machine Learning tool is employed for this purpose that uses semi-supervised classifier to create the model.
III. PROBLEM DEFINITION
The audit source most used today is network packets. Almost all the vendors studied have some kind of network-based sensor. When data is picked up before it has reached its destination, as is done when picking up network packets, there is a problem if the data has been encrypted in any way. If so, the actual payload cannot be seen and the NIDS becomes nearly useless since the content of the packet cannot be examined. Any malicious behaviour hidden within the packet can pass undetected. The only thing the NIDS can do is to look at the header of the packets and see if the traffic pattern looks normal. This means that the technologies that can be used in this case is protocol decode and statistical knowledge about how traffic should look (e.g. volume of network traffic). Another problem is that the increasing network complexity requires more and more of IDSs. More networks are switched in order to maximize performance as well as logically structure the corporate networks. To successfully monitor a switched network an IDS is either needed on each individual segment or on each of the switches span ports.
Either way, it demands more in terms of scalability and aggregation of the IDS in order to function well. Even if most of the IDSs today scale well, aggregation and correlation properties are not satisfactory.
IV. PROPOSED WORK
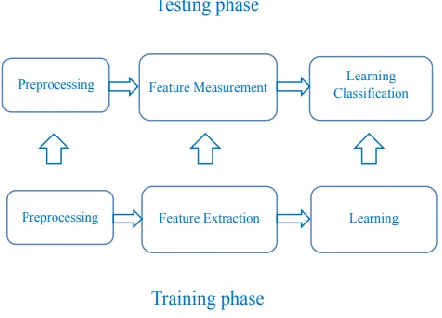
[image:2.612.340.561.307.466.2]In this paper, we proposed an network IDS based on K-Nearest Neighbor (KNN) classifier. KNN enhances the attack detection accuracy and it very efficient in distinguishing network traffic is attack or normal. We performed our experiments on the NSL KDD Data set. NSL KDD Data set is mostly used for testing intrusion detection system (IDS).
Figure 2. Proposed model
Algorithm: Network intrusion detection system using Random Forest classifier.
Input: NSL-KDD Data set
Output: Classification of different types of attacks. Step I: Load NSL-KDD data set.
Step 2: Apply preprocessing technique - discretization. Step3: Clustered the datasets into four types.
Step 4: Partition each cluster into training sets and test sets. Step 5: Data set is given to KNN algorithm for training. Step 6: Test dataset is then fed to KNN for classification of attacks.
Step 7: Record the accuracy of the classifier.
V. EXPERIMENTAL & RESULT ANALYSIS
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 9, Issue 10, October 2019)
96
For experiment we can take NSL-KDD dataset which contains millions of records and for creating machine learning model we can use jupyter notebook which is an IDE for python. So first we can start the jupyter notebook through terminal and figure 2 shows the connection creation between jupyter notebook with python.
Figure-3 Start the jupyter notebook
And then providing name of each attributes present in
[image:3.612.49.292.210.397.2]the dataset. And these attribute names are shown in figure 3.
Figure-3 Attributes names.
After loading the dataset and assigns each attributes a name and then we pre-processed the data by using standard scalar function and after preprocessing we split the dataset into train and test data, In these we can split the data into two part in which 80% is for train data and remaining 20% is for testing data. After splitting a data we can provide the train data to the model for learning purpose and from these train data we can first perform a feature selection process by which we can get different dimensions which is shown in figure 4.
Figure-4. Feature selection
After feature selection we can train the KNN model on train dataset and then the model is trained we can test the KNN classification model on test datasets from which we can get the model accuracy and other performance measures, figure 5 shows the classification result of random forest.
[image:3.612.325.579.505.653.2]International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 9, Issue 10, October 2019)
97
After performing KNN classification we can build the random forest classification on the same dataset and the result outcomes are shown in figure 6.
Figure 6. Accuracy of the Random Forest Classifier
Performance Measure
We used accuracy, which are derived using confusion matrix.
Table-1 Confusion Matrix
Where
TN -Instances correctly predicted as non-attacks. FN - Instances wrongly predicted as non-attacks. FP -Instances wrongly predicted as attacks. TP -Instances correctly predicted as attacks.
Accuracy = Number of samples correctly classified in test data
[image:4.612.320.570.123.412.2]Total number of samples in test data
Table-2. Accuracy of Models
Algorithm Accuracy
SVM 93%
KNN 97.52%
Random Forest 97.90%
90 91 92 93 94 95 96 97 98
SVM KNN Random
Forest
Accuracy
Figure-7. Accuracy of Models
VI. CONCLUSION
Classification of Intrusion Detection System (IDS) with NSL-KDD99 dataset applies classification technique of Random forest method proved to give better result than using other classification technique of SVM and KNN. After testing the results of different classification results we can say that Random forest model takes time for training because it perform various iteration to handle attributes and affects the final classification results.
REFERENCES
[1] Dr. Uma Kumari, Uma Soni, “A Review of Intrusion Detection using Anomaly based Detection” in Proceedings of the 2nd International Conference on Communication and Electronics Systems (ICCES 2017) .
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 9, Issue 10, October 2019)
98
[3] Nawfal Turki Obeis and Wesam Bhaya, “Review of Data Mining Techniques for Malicious Detetion”, Research journal of Applied Sciences 11(10):942-947, 2016.
[4] Jau-Hwang WANG, Peter S. DENG, “Virus Detection Using Data Mining Techniques”, TAO-Yuar, Taiwan, ROC333.
[5] Chi Zhang And Jinyuan Sun, “Privacy and Security for Online Social Networks: Challenges and Opportunity”, Yuguang Fang, University of Florida and Xidian University.
[6] Uma Salunkhe and Suresh N. Mali, “ Enrichment in Intrusion Detection System Using Ensemble”, Journal of Electrical and computer Engineering.
[7] Q.S. Qassim, A. M. Zin and M. J. Ab Aziz, “Anomalies classification approach for network- based intrusion detection system”, International Journal of Network Security, pp.1159-1171, 2016.
[8] O.Y.Al-Jarrah, O. Alhussein, P.D.Yoo, S. Muhaidat, K.Taha and K. Kim, “ Data Randomization and Cluster-based Partitioning for botnet intrusion detection”, IEEE Transactions on Cybernetics, vol. 46, no. 8, pp. 1796-1806, 2016.