On the Prevention of Cache-Based
Side-Channel Attacks in a Cloud Environment
by
Michael Godfrey
A thesis submitted to the School of Computing
in conformity with the requirements for the degree of Master of Science
Queen’s University Kingston, Ontario, Canada
September 2013
Abstract
As Cloud services become more commonplace, recent works have uncovered vulnera-bilities unique to such systems. Specifically, the paradigm promotes a risk of informa-tion leakage across virtual machine isolainforma-tion via side-channels. Unlike conveninforma-tional computing, the infrastructure supporting a Cloud environment allows mutually dis-trusting clients simultaneous access to the underlying hardware, a seldom met re-quirement for a side-channel attack. This thesis investigates the current state of side-channel vulnerabilities involving the CPU cache, and identifies the shortcomings of traditional defences in a Cloud environment. It explores why solutions to non-Cloud cache-based side-channels cease to work in non-Cloud environments, and describes new mitigation techniques applicable for Cloud security. Specifically, it separates canonical cache-based side-channel attacks into two categories, Sequential and Paral-lel attacks, based on their implementation and devises a unique mitigation technique for each. Applying these solutions to a canonical Cloud environment, this thesis demonstrates the validity of these Cloud-specific, cache-based side-channel mitiga-tion techniques. Furthermore, it shows that they can be implemented, together, as a server-side approach to improve security without inconveniencing the client. Finally, it conducts a comparison of our solutions to the current state-of-the-art.
Acknowledgments
I would like to thank my supervisor, Professor Mohammad Zulkernine for supporting me and letting me stumble unrestrained through the course of this thesis. Not many supervisors would be comfortable letting their students work in foreign territory with the restriction of it should have something do to with security or reliability.
I would like to thank my family. Who supported me in my decision to do a MSc, and would still have done so had I not. They always showed interest, even if some of them still think Cloud Computing is something that happens vis a vis the sky.
More technically, I would also like to thank Yunjing Xu [35] for his discussion and help in the creation of a canonical cache-based side-channel attack for the purpose of our evaluation. Without his guidance I might still be figuring out how to get the attack working, rather than how to prevent it.
Table of Contents
Abstract i
Acknowledgments ii
Table of Contents iii
List of Tables vii
List of Figures viii
Chapter 1: Introduction . . . 1
1.1 Motivation . . . 1
1.2 Contributions . . . 3
1.3 Organization of Thesis . . . 4
Chapter 2: Background . . . 6
2.1 The Cloud Model . . . 6
2.1.1 Virtual Machines . . . 8
2.1.2 The Xen Hypervisor . . . 9
2.2 CPU Cache . . . 11
2.3 Side-Channel Attacks . . . 14
2.3.1 Cache Channel Attacks . . . 15
2.4 Summary . . . 16
Chapter 3: Related Work . . . 17
3.1 Side-Channels . . . 17
3.2 Side-Channels in the Cloud . . . 19
3.3 Cache Colouring . . . 19
3.4 Summary . . . 21
Chapter 4: Side-Channel Attacks . . . 22
4.1 Sequential Side-Channel . . . 22
4.2 Parallel Side-Channel . . . 26
4.3 Summary . . . 28
Chapter 5: Selective Cache Flushing . . . 29
5.1 Overview . . . 30
5.2 Expected Issues and Mitigations . . . 31
5.2.1 Reduced Cache Usability . . . 32
5.2.2 Cache Flushing Overhead . . . 33
5.3 Cache Flushing Technique . . . 35
5.3.1 Decision Algorithm . . . 35 5.3.2 Flushing Function . . . 36 5.4 Experimental Evaluation . . . 38 5.4.1 Objectives . . . 38 5.4.2 Environment . . . 39 5.4.3 Side-Channel Prevention . . . 40 iv
5.4.4 Performance Experiments . . . 41 5.4.5 Results . . . 47 5.5 Result Analysis . . . 48 5.5.1 Side-Channel Prevention . . . 54 5.5.2 Performance Analysis . . . 55 5.6 Summary . . . 63
Chapter 6: Cache Partitioning . . . 65
6.1 Parallel vs Sequential Side-Channels . . . 65
6.2 Overview . . . 67
6.3 Expected Issues and Mitigations . . . 69
6.4 Cache Partitioning Technique . . . 70
6.4.1 Cache Colouring . . . 72 6.5 Experimental Evaluation . . . 74 6.5.1 Objectives . . . 75 6.5.2 Environment . . . 75 6.5.3 Side-Channel Prevention . . . 76 6.5.4 Performance Experiments . . . 77 6.5.5 Results . . . 81 6.6 Result Analysis . . . 85 6.6.1 Side-Channel Prevention . . . 85 6.6.2 Performance Analysis . . . 86 6.7 Summary . . . 90
Chapter 7: Conclusions and Future Work . . . 92
Bibliography . . . 95
List of Tables
5.1 Sun Context Switch Timings (Assumes 200 Switches per Second) . . 56 5.2 IBM Context Switch Timings (Assumes 200 Switches per Second) . . 56
List of Figures
2.1 Architecture of the Xen Hypervisor . . . 10
2.2 The Cache Hierarchy . . . 12
4.1 The Prime+Trigger+Probe Technique . . . 23
4.2 The Prime+Trigger+Probe Technique (Parallel Adaptation) . . . 27
5.1 Our Solution’s Effect on the PTP Technique (Sequential) . . . 31
5.2 The Apache benchmark on the Sun machine with varying number of VMs . . . 49
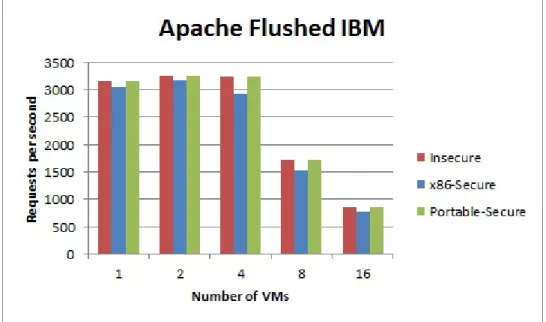
5.3 The Apache benchmark on the IBM machine with varying number of VMs . . . 49
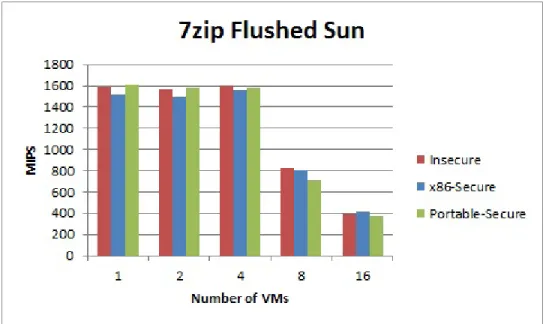
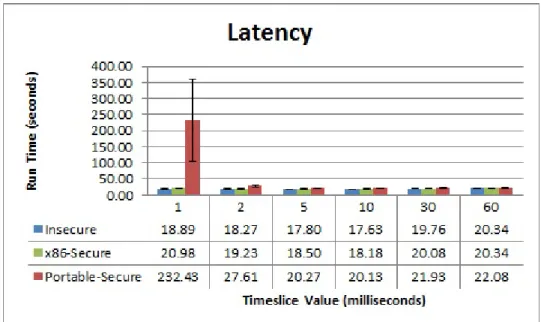
5.4 The 7zip benchmark on the IBM machine with varying number of VMs 50 5.5 The 7zip benchmark on the Sun machine with varying number of VMs 50 5.6 Latency workloads executed on Xen Hypervisor with varying Timeslice values . . . 51
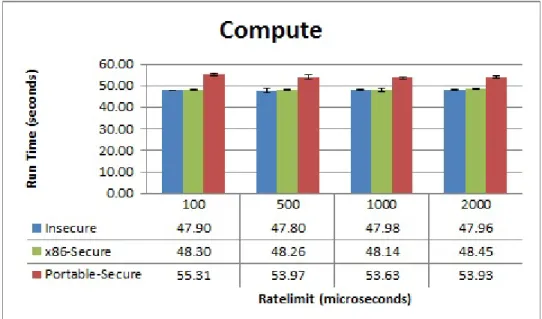
5.7 Computationally-heavy workloads executed on Xen Hypervisor with varying Timeslice values . . . 51
5.8 Latency workloads executed on Xen Hypervisor with varying Ratelimit values . . . 52
5.9 Computationally-heavy workloads executed on Xen Hypervisor with
Ratelimit values . . . 52
5.10 Latency workloads executed on Xen Hypervisor with varying number of VMs . . . 53
5.11 Computationally-heavy workloads executed on Xen Hypervisor with varying number of VMs . . . 53
6.1 The Effect of Partitioning the Cache on the PTP Technique (Parallel) 68 6.2 Mapping of a Memory Address in the Cache . . . 73
6.3 Apache Benchmark . . . 82
6.4 Cachebench Benchmark . . . 82
6.5 Cache Timing Benchmark (Cached) . . . 83
6.6 Cache Timing Benchmark (Flushed) . . . 83
6.7 Cache Timing Benchmark (Flushed - Cached) . . . 84
6.8 VM Boot Times based on Number of Partitions . . . 84
Chapter 1
Introduction
1.1
Motivation
As a new design paradigm, Cloud computing brings with it a unique set of features and vulnerabilities. Specifically, the Cloud introduces the concept of mutually distrusting co-resident clients as a valid execution state. This is a relatively new concept in computing. Few systems in the past have had to account for malicious action among their own users, on the same hardware, while still providing each user with seemingly full machine access.
As one might imagine, providing co-residence for clients has brought to light a new set of vulnerabilities in the paradigm. Specifically, an attacker’s use of hard-ware side-channels to gain information about data and functionality that they should not, by design, have access to. Such attacks exploit co-resident systems by inferring software functionality from observed hardware phenomena. This allows an attack to be performed in any context where the attacker and victim have access to the same hardware, so long as proper safeguards are not in place .
CHAPTER 1. INTRODUCTION 2
While side-channel attacks have existed in the past [21], the novel co-residency feature of Cloud computing makes them particularly effective in this context. As the attacker is no longer required to gain unlawful, or otherwise restricted access to the victim’s hardware, this essentially bypasses the first, and most effective, defence against such attacks.
Since a side-channel requires the exploitation of a specific piece of hardware, each solution must also be adapted specifically for that hardware channel. This allows us to classify side-channel attacks and defences based on the hardware medium they exploit. The CPU cache is one of the most frequently used pieces of shared hardware, and often deals with sensitive data. This makes it one of the most common targets for use in a side-channel attack as it can more easily be used to extract useful data at a high rate. An attack made over this channel is referred to as a cache-based side-channel attack.
Cloud computing is becoming more popular, but the number one concern of tech-nologists heading to the Cloud is security [11]. CPU cache-based side-channel attacks are currently believed to be the most dangerous, among side-channel attacks. In recent years, there have been multiple publications about Cloud-specific vulnerabil-ities and exploits, specifically the use of side-channels to bypass the virtualization technology used in Cloud systems [26, 36, 33, 6]. Among other exploits, they have recently been used to extract private keys in a Cloud environment [37] and yield high-bandwidth information leakage [35]. Because they are so specific to the medium, the solutions to a side-channel are specific to the hardware medium being exploited. As such, the most significant and robust threat comes from CPU-cache based attacks. Because of this, the scope of this thesis is limited to side-channel attacks which exploit
CHAPTER 1. INTRODUCTION 3
the CPU cache.
In response to these attacks, there have been publications attempting to mitigate such situations. While beneficial, these solutions require the client using them to modify their own software to work with their technology [13] [27], or the underlying hardware [22]. From studying the Cloud, we believe that this restriction is both hindering to the user, and unnecessary. We argue that the Cloud’s relationship with its users and hardware, referred to in this thesis as the “Cloud model”, prevents such solutions from being implemented. Therefore, a new, server-side defence against such attacks in the Cloud is necessary.
1.2
Contributions
Our goal in this thesis is to provide a defence capable of preventing cache-based side-channels in the Cloud while not interfering with the Cloud model. Using the code base of an open source hypervisor, Xen [15], we demonstrate how to inhibit cache-based side-channels from occurring within a Cloud server. In addition, we validate the system against canonical attacks while demonstrating that they can be prevented without client-side or hardware modifications. We then compare our system to an established Cloud provider, demonstrating that such methods can be practically implemented in a modern Cloud system. Special attention is paid to the issues and configurations expected to be heavily impacted by the defences’ implementations.
The major contributions of this thesis are listed as follows:
• 1: A study of cache-based side-channels in a Cloud environment. This includes a categorization of existing attacks into theSequential and Parallel types.
CHAPTER 1. INTRODUCTION 4
• 2: Two server-side defences against cache-based side-channels. One focuses on sequential channels [9], which includes a technique to prevent the side-channel’s occurrence as well as an algorithm designed to implement the tech-nique. The algorithm applies the solution in a minimalistic fashion to help minimize resulting overhead. The second focuses on parallel side-channels, and uses a cache colouring technique to prevent their occurrence and to improve cache efficiency in certain situations.
• 3: An implementation and validation of the above defences. We implement the above defences and demonstrate their ability to prevent cache-based side-channel attacks in an experimental Cloud environment. The defences are evaluated by running them against attacks designed to be representative of previously pub-lished attacks of the cache-based side-channel genre.
1.3
Organization of Thesis
The side-channels studied typically comes in two varieties that each require a unique solution. As a result, this thesis details and approaches the problems of Sequential Cache-Based Side-Channels and Parallel Cache-Based Side-Channels in two separate chapters. The chapters that share information about both varieties of channels tend to first describe details that concern one variety, then the other. The chapters explaining our solutions to each variety of channel tend to be dedicated to only that variety.
The remainder of this thesis is organized as follows: Chapter 2 describes aspects of the Cloud, Cloud technologies, side-channels, and related software techniques; how they relate to side-channel attacks and the prevention thereof. Chapter 3 summarizes
CHAPTER 1. INTRODUCTION 5
related work regarding side-channels, their use in the Cloud, and their prevention. It also describes programming techniques, such as cache colouring that we make use of in our solutions. Chapter 4 details the attacks attempting to be prevented, following how they are traditionally implemented and what system attributes they exploit. Chapter 5 focuses on our solution to sequential side-channels. It details how our solution solves the problem, how it is implemented, and our experimental results as to its validity and performance. Chapter 6 describes our solution to parallel side-channels. It also describes how our solution solves the problem, its implementation, and its experimental validity and performance. Finally, Chapter 7 concludes the thesis.
Chapter 2
Background
This chapter details the form and function of the modern Cloud system and its susceptibility to side-channel attacks. It describes the Cloud, its architecture, and a common open-sourced implementation that will be used to implement our solution. It also explains side-channel attacks, specifically those involving the CPU cache, and their specific threat to Cloud environments.
2.1
The Cloud Model
The idea of Cloud Computing revolves around the pooling of multiple, large-scale, computing resources into a single, abstract entity, commonly referred to as the Cloud. This construction allows multiple clients concurrent access to these resources. Con-ceptually similar to the Mainframe paradigm of decades past [10], Cloud computing differs in its extensive use of networking technologies. It typically focuses on using many machines, composed of lower-grade canonical hardware, rather than fewer, more
CHAPTER 2. BACKGROUND 7
powerful, machines. Due to its underlying discreteness, complex software technolo-gies need to be used in the Cloud to abstract these individual machines into a single dynamically manageable resource.
The main objective of Cloud computing is to allow the clients to outsource their hardware needs. Cloud providers take advantage of the versatile nature of the Cloud to provide clients with computational resources when needed, and allow them to be used by other clients when free. The paradigm has often been compared to that of a utility grid, and has sometimes been referred to as Utility Computing.
As a paradigm, Cloud computing has developed a specific relationship with its users and underlying hardware that we will refer to in this thesis as the Cloud Model. The model highlights two key points that have become commonplace in Cloud sys-tems. First: users will often run canonical software on the Cloud and, as such, may not have the permission, or the knowledge to modify the software they intend to run. Second: A Cloud system is typically built from canonical hardware so that it can be easily expanded and maintained. It is our belief that any modifications made to the Cloud must preserve these two qualities so as to maintain the practicality of the Cloud. We therefore define a solution as adhering to the Cloud model if:
• 1: It does not require any software modifications by the client or on the client-end of the interface
• 2: It does not require any modifications to the underlying hardware
If a solution matches both points then we can say it complies with the Cloud model and can be applied to a current Cloud system without interfering with the established functionality.
CHAPTER 2. BACKGROUND 8
2.1.1
Virtual Machines
Virtual Machine (VM) technology is the backbone of the modern Cloud implementa-tion. A virtual machine system functions by emulating a physical machine within a software program. Essentially, virtual machine software acts as middleware between the programs being executed and the underlying hardware. It acts as one or more execution environments within which the programs may run.
The real benefit of virtual machine software is that the middleware is (ideally) completely transparent. Each executing program has the illusion of running on a single isolated system. Even if there are actually twenty such systems being emulated in tandem, each one acts within the constraints of a single conceptual machine. It is through such technology that Cloud systems are viable, as they can virtually dis-tribute the resources of a single machine between an arbitrary number of clients. Each client has the impression of being given sole access to a smaller, isolated machine.
A virtual machine system is typically composed of two parts, the domains and the hypervisor. The domains are the machine emulating instances. Each domain will typically run its own version of an operating system and emulate a distinct physical machine. Any process executing within a domain has no access to, or knowledge of, anything outside of that domain. From its perspective, the domain and its emulated OS compose the entire system.
The hypervisor of a virtual machine system (also known as the virtual machine monitor) is where the real complexity of the system lies. It acts as a super-operating system, typically installed between the domains and the underlying hardware (referred to as a bare-metal install). It serves as an intermediary to manage each domain’s access to the hardware. Most of the operations of a typical operating system can be
CHAPTER 2. BACKGROUND 9
found in a hypervisor, including CPU scheduling and memory management. However, these operations function on a larger scale than a regular operating system as the processes being managed are themselves full blown operating systems rather than smaller-scale processes.
2.1.2
The Xen Hypervisor
Xen is a specific, open-source implementation of a bare-metal hypervisor. At the time of writing, Xen is known to be quite developed and is being used as the backbone for many established Cloud enterprises, including Amazon’s EC2 [2]. The combined nature of its canonical use and its open source access make it a prime candidate for experimentation relating to hypervisors in the Cloud. Xen functions as a combination of a bare-metal hypervisor (the Xen hypervisor), a single host domain (Dom0), and any number of guest domains (DomUs, or guests).
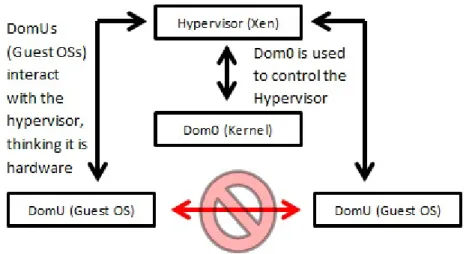
Dom0 is a customized Linux OS capable of interacting with the hypervisor. It acts as the administration tool for the system. The DomUs represent the guest machines that clients will be using. The hypervisor controls basic operations, such as the CPU scheduling and memory management of the system. Complex functionality such as networking and IO are handled by the Dom0 after being redirected from the guests [15]. The guest operating systems are, of course, unaware of the context in which they are running. This type of software isolation has a bonus of acting as a security mechanism to separate one VM from another, working under much the same lines as sandboxing. Unfortunately, side-channels have been demonstrated to bypass this sort of isolation. A graphical interpretation of the Xen hypervisor and its chief components can be seen in Figure 2.1.
CHAPTER 2. BACKGROUND 10
Figure 2.1: Architecture of the Xen Hypervisor
In this figure, we see a Xen system which includes the hypervisor, a Dom0, and two DomUs. This configuration represents a single physical server set-up with two guest VMs running. The arrows represent communication between the subsystems via system/hypercalls (a hypercall is the hypervisor’s equivalent to an operating sys-tem’s system call). When the two guests require resources, such as memory, or other machine access, they communicate with the hypervisor. When the administrator needs to communicate with the hypervisor, it is done via Dom0. If a guest needs to communicate with Dom0, it should be done through the hypervisor. Some systems allow exceptions to this organization and are referred to as para-virtualized systems. These systems allow certain direct communication on the guest’s behalf for optimiza-tion purposes. By design, there should be no other channels of direct communicaoptimiza-tion save for the standard networking capabilities of the guest machines. Ideally, there
CHAPTER 2. BACKGROUND 11
should be no way for the guest machines to communicate with one another directly without using networking protocols.
2.2
CPU Cache
A CPU cache is a small section of memory built into the CPU. This memory acts as a medium through which any request for data must go. It serves to increase the speed of memory access for more commonly accessed data. Essentially the cache is a section of memory that can be accessed much more quickly, but is much smaller than main memory. Dedicating a small amount of memory to a cache can lead to massive speed increases, as CPUs often require frequent access to the same memory addresses. Keeping these frequently accessed data in the cache reduces the time needed to access these data, and therefore increases the speed of the program.
A modern-day CPU contains multiple levels of cache dedicated to different pur-poses. The most common organization is depicted in Figure 2.2. In this figure, the data storage areas are organized from the top-down by decreasing speed of access and by increasing size. This puts the smallest, and fastest storage mechanisms on the top, and the slowest/biggest on the bottom.
When data is required by the CPU (for the registers), it is first requested from the L1 cache. The L1 cache is unique in that it is often divided into separate instruction and data caches. The speed requirements for this cache, as it will be accessed most often, mean that it is usually virtually indexed. This means that the mapping of a memory address to the cache position is determined by its virtual address (as viewed by a process) as opposed to its physical address (as viewed by the operating system). This means that the cache is high speed, but mappings are not preserved between
CHAPTER 2. BACKGROUND 12
CHAPTER 2. BACKGROUND 13
contexts (different processes will have different mappings). Because these mappings are not preserved across contexts, there is little possibility for information leakage across the L1 cache.
If the requested data are located in the L1 cache, this is called a cache hit, and the data are returned to the CPU at a very high speed (typically within a handful of cycles). If they are not located in the L1 cache, this is referred to as a cache miss. If a cache miss is experienced, the data are next looked for in the next level of memory - for an L1 cache miss, this would be the L2 cache. Once found (at any level) the data are propagated back through each level of cache that experienced a miss to populate a portion of that cache. In this way, a successive attempt to access those data should find them located in a lower, and therefore faster, level of the cache hierarchy. Because there is limited space in each cache, the incorporation of new data may remove some existing data from the cache. This removal is referred to as acache eviction.
The L2 cache is typically much larger than an L1 cache and contains both in-structions and data. Because the L2 cache is larger, and slower, that an L1 cache it is most often physically indexed. This means that the mapping of memory addresses to cache locations are done via physical memory and are preserved across contexts. Since the mapping is preserved, processes which have shared access to data may find those data located in the cache without first causing a cache miss. As a trade-off, this can cause information leakage between processes, as a process that finds data pre-located in the cache can infer that another process put it there.
Often included in modern CPUs is a shared L3 cache. While the L2 and L1 caches have each been dedicated to a single CPU core, a shared L3 cache stores
CHAPTER 2. BACKGROUND 14
data from multiple cores simultaneously. The argued benefit to this scheme is that memory intensive processes can make use of a much larger cache when the resources are available, allowing a maximal usage of cache resources. This scheme is unique in that it allows multiple CPU cores access to a shared resource, and information leakage can happen much like in the L2 example. If a cache miss at the L3 ( last level) cache occurs, the requested data are sought in main memory.
2.3
Side-Channel Attacks
A side-channel (or covert-channel) in a software program is a means of communi-cation via a medium not intended for information transfer [22]. It typically involves correlating the higher level functionality of the software with the underlying hardware phenomena. With an established correlation, these phenomena can be measured and analysed to infer what is occurring within the software program at a given time.
While the measured phenomena vary with the specific properties of the hardware in question, any phenomenon that can be reliably correlated to the software’s function can be used as a side-channel. Examples may include the timing of specific hardware functions, or the acoustic properties of a hardware device. Typically, the higher-rate hardware functions are more interesting to explore as side-channels because they can communicate information more quickly, and therefore can yield more details about the state of the program in execution. To this end, CPU cache-based side-channels typically receive the most attention, as they are one of the highest-rate measurable resources shared between processes [35] [33].
Traditionally, cache-based side-channels have been used to glean the functionality of closed source systems and functions. Examples include the breaching of cross-VM
CHAPTER 2. BACKGROUND 15
systems, and the breaking of the Advanced Encryption Standard (AES) and Data Encryption Standard (DES) encryption algorithms. An experiment in 2003 used a timing-based measurement system on the CPU cache-channel to determine cache hits and misses in a DES encryption algorithm. By correlating the timing measurements with the execution of the algorithm, the authors were able to break the DES cypher in more than 90% of their attempts [31].
2.3.1
Cache Channel Attacks
In order for the CPU cache to be used in a side-channel attack, the cache must in some way be shared by the attacker and their target. A Cloud environment makes this condition particularly easy to achieve as both the attacker and target can get access to the same physical machine. Typically, a CPU cache can be shared in two ways, either the cache is exclusive to one CPU core, in which case two processes must access the cache sequentially; or cache is shared between CPU cores, in which case two processes can access the cache concurrently. We refer to the first type of attack as a sequential, cache channel, and to the second as a concurrent, or parallel, cache channel.
Research has been done into attacks for both classes of channel [33] with the former typically seen as more portable, as only some systems will allow for parallel access to a cache. However, recent trends in hardware technology are seeing more and more CPUs outfitted with larger, shared, victim caches. These caches are designed to be shared among multiple cores and can be accessed in tandem.
While the techniques for attacking these two types of cache are quite similar, the hardware differences require dramatically different solutions. In order to address
CHAPTER 2. BACKGROUND 16
both types of channels we have devised two solutions. For the sequential channel we apply a technique called Selective Cache Flushing, which can be found in Chapter 5. For parallel channels we apply a technique called Cache Partitioning, based on cache colouring, which can be found in Chapter 6. These two solutions can be implemented in conjunction to insulate a hypervisor against both types of side-channel.
2.4
Summary
This chapter details the relevant background information dealing with side-channels and Cloud technologies. We describe how the Cloud paradigm has affected traditional side-channel security and which attacks have become prominent or dangerous in the Cloud. We also describe what aspects of Cloud technologies have encouraged these changes and what may be done to solve such a problem.
More specifically, we describe the current state of the Cloud and its relationship with its users. We emphasize the importance of maintaining this relationship when attempting to mitigate side-channel attacks in the Cloud. From this we impose constraints on our own solutions to make sure that this relationship is maintained.
Chapter 3
Related Work
This chapter details the related work on side-channels and techniques to mitigate them. It includes a brief summary of cache-based side channels and their typical mit-igation techniques. It then compares these techniques to the Cloud-based variations of the attacks and solutions. In addition, it summarizes work on other techniques that we incorporate into our design, including cache colouring.
3.1
Side-Channels
Previous work have demonstrated that cache-based side-channels can be exploited in the Cloud to glean information that service providers do not want users to have access to. Such cases include determining whether two machines are co-resident [26], and more dangerously, the extraction of cryptographic private keys from unwary hosts [37]. The latter particularly demonstrates the severity of a side-channel attack in the Cloud and the potential for similar side-channel attacks when migrated to a Cloud environment [31] [21] [28].
CHAPTER 3. RELATED WORK 18
Since the attention given to side-channels in non-Cloud environments in the 70’s [14], there have been many solutions proposed [21], [22]. Some of these include: altering the functionality of the hardware channel, disabling the hardware channel, or modifying the victim code to break the correlation between the program’s execution and the hardware phenomena. While these solutions often succeed, all three are counter-productive to the Cloud model, which uses canonical hardware and whose clientele are users from a various strata of technical skill levels. Implementing any of these defences would require the customization of either all hardware intended for use in the Cloud, or else all software intended to be run in a Cloud environment. Both of these solutions conflict with the Cloud model, as they would either restrict the hardware requirements or the client skill level needed to use the Cloud.
Cache flushing has been considered, but disregarded as a solution to traditional cache-based side-channels because it is expected to generate large amounts of overhead [21].
Recent work at the Massachusetts Institute of Technology has focused on modi-fying Cloud hardware to prevent side-channels [7]. Their work attempts to obfuscate side-channel attempts by adding additional work to certain processes. Unfortunately, their hardware often decreases efficiency by factors up to an order of magnitude. That these levels of overhead can be considered an acceptable trade-off for security empha-sizes the need for high-efficiency solutions. Of course, the fact that they modify the hardware violates the Cloud model as it would require every machine in the Cloud to be replaced with a modified system.
CHAPTER 3. RELATED WORK 19
3.2
Side-Channels in the Cloud
Kim et al. have developed a solution for cache-based side-channels in Cloud systems [13]. In their solution, they prevent cache-based side-channels by giving each VM exclusive access to a sectioned portion of the cache they call a stealth page. Using a stealth page, the sharing of cache information is prevented by having each VM restore its context in that page before its time slice execution.
In order to have software applications access these hidden pages, their solution requires the user to make client-side modifications to the software being executed in the guest VM. Due to its canonical nature, however, we believe that most clients will either not have the access, or not have the technical skill, to modify the software they intend to run in the Cloud. This restriction demonstrates the need for a solution transparent to the Client.
For our solution, we implemented a purely server-side defence for cache-based side-channels in the Cloud. To make it fully compatible with the Cloud model, we impress the constraints that it both prevent cache-based side-channels between co-resident VMs, and that it requires no modifications of the underlying hardware nor of the software being run on a VM. From this perspective, the solution should be both secure and invisible to the Client, as well as to the Cloud provider. Only the Cloud developer would be aware that such a solution is in place.
3.3
Cache Colouring
For our parallel cache channel solution, we use a technique known as Cache Colouring. Cache colouring has been used in the past primarily as an optimization scheme to
CHAPTER 3. RELATED WORK 20
maximize the cache hit rate. Previous work by Tam et al. explored the use of cache colouring in environments where multiple processes shared a common cache [30]. In these experiments, they used a cache colouring technique to increase the cache hit rate by minimizing the number of cache data evictions occurring across processes. In our experiments, we use a similar technique to partition the cache on a virtual machine level granularity. While some similar results are observed in the reduction of cache misses in certain cases, our priority was the security of the system. As a result, the technique was implemented with some variations to guarantee the security features, as opposed to the performance features, of the system.
Two recent papers by Kim et al.[13] and Shi et al.[27] attempt to use a form of cache partitioning to prevent cache-based side-channels. Both focus on reserving a small portion of the cache on a per-VM or per-core basis using cache-colouring that can dynamically be accessed by VMs when they need to execute a “side-channel proof” process.
The upside to these attempts is that they attempt to incur very minor overhead by maximizing each VM’s access to the cache and by securing portions of the VM dynamically. The downside is that both of these solutions require the client programs to understand that they are running in a modified environment to take advantage of the security features. While minor, these alterations violate the Cloud Model.
In addition, both solutions are focused on specific types of cache-channel attacks, such as attacks that focus on the S-Box of a cryptographic algorithm and so assume only a small portion of memory needs to be protected at once. While understandable as these have, to date, been the most dangerous cache-based attacks mounted on conventional systems, such an assumption means that these defences cannot prevent
CHAPTER 3. RELATED WORK 21
attacks that use a larger portion of the cache. For instance, work by Ristenpart et al. implemented a side-channel to detect co-residence in Cloud environments [26]. As their particular implementation attempts to maximize usage of the cache, reserving small portions of the cache would not prevent such a technique.
Other work has been done attempting to partition the cache physically [23]. Of course, this also violates the Cloud Model and an ideal solution would provide the same security using purely software means.
3.4
Summary
This chapter describes work related to side-channels, cache-based side-channel attacks in the Cloud, defences against them, and cache colouring. Included among them are details of the side-channel attacks that have successfully been launched in the Cloud and works that have attempted to prevent such attacks. All of the work that has attempted to solve side-channels in the Cloud has done so by either altering the software being run by the client, or the underlying hardware. We argue that while successful, these solutions are not practical for general Cloud users and therefore, a new solution that conforms to the Cloud model is necessary.
In addition, we describe work that has attempted to use Cache colouring for security or efficiency purposes. We compare our own work with theirs and show that while they use a similar technique to manipulate the cache, they design their solution quite differently by isolating only small portions of the cache.
Chapter 4
Side-Channel Attacks
In order to discuss possible mitigations for a cache-based side-channel attack, it is necessary to define the specifics of the attack in question. While previous work have detailed attacks in local environments [21] [28], more recent work has specified a form of attack applicable to a Cloud system. This chapter describes the cache-channel attack that we are attempting to mitigate, including both the sequential and parallel variants.
4.1
Sequential Side-Channel
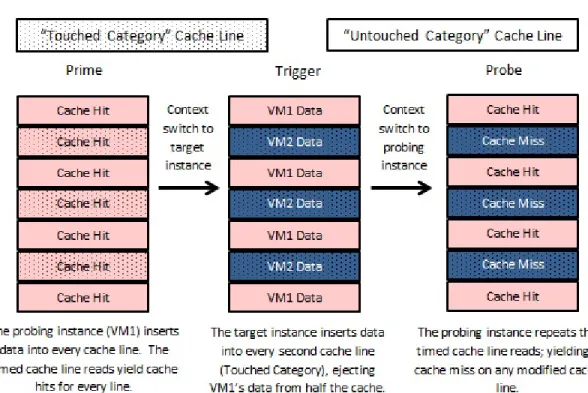
The first documented form of a cache-based side-channel attack explored in the Cloud was by Ristenpart et al. [26] who demonstrated the use of side-channels to verify virtual machine co-residence in Amazon’s EC2. As part of their work, they explored the use of a previously identified cache-based side-channel technique, which they refer to as the Prime+Probe technique, in a Cloud environment. The result of such work is the Prime+Trigger+Probe (PTP) technique, illustrated in Figure 4.1, a variation
CHAPTER 4. SIDE-CHANNEL ATTACKS 23
CHAPTER 4. SIDE-CHANNEL ATTACKS 24
designed to work in Cloud environments. The purpose of their experiment, using the PTP technique, was to see if a cache-based side-channel could be established between two guest domains in the Cloud. The channel was established such that the first VM (referred to as the probing instance) could receive a message that the second VM (the target instance) encodes in its usage of the cache. The basic version of the PTP technique shown in Figure 4.1 is an example of a sequential side-channel.
In the PTP technique, the probing instance first separates the cache lines into two categories: theTouched category and theUntouched category. Once the channel has been established, cache lines in the touched category will be modified by the target instance. Lines in the untouched category will remain intact.
Using the timestamp counter in the CPU, the probing instance can measure the number of CPU cycles required to access each cache line. The resulting differences in access times for hits and misses in the cache is observable by the probing instance and will serve as the communication means within the channel.
Once the categories have been established, the probing instance primes the cache by filling as many cache lines as it can (ideally, all of them). It then establishes an access time baseline by reading from each line in both categories. Having just been primed, each cache line should yield a cache hit, regardless of category, thus keeping the baseline access times low. This process is highlighted in thePrime step of Figure 4.1. Having done this, the probing instance now has a series of values which represent how long it took to access each cache line with a primed cache.
Once the cache has been primed, and the baseline established, the probing instance must Trigger (context switch to) the target instance by busy looping, or otherwise giving up its time slice. When the target instance begins its time slice, it heavily
CHAPTER 4. SIDE-CHANNEL ATTACKS 25
accesses the cache lines in one of the pre-defined categories of the cache (the Touched category), but not the other (the Untouched category). The effect of this switch on the data can be seen in the Trigger step of Figure 4.1. In this figure, the target instance is accessing every second cache line in an access pattern we have pre-defined. The resulting set of accessed lines we define as the Touched category of the cache. By contrast, cache lines in the untouched category were not accessed by the target instance. When the CPU core context switches back to the probing instance, the instance probes the cache by re-measuring the access times for each line. This is illustrated in the Probe step of Figure 4.1. If there is a significant increase in the access times for cache lines in the touched category compared to the untouched cat-egory, then the probing instance can assume that the target instance was trying to communicate.
The PTP technique was refined in later work by Wu et al. [33], where they estab-lish a high-speed bit-stream by communicating a “1” or a “0” based on whether the difference between category timings is positive or negative (assuming the difference is above a certain threshold). Using this technique, they were able to establish reliable side-channel bit-streams of over 190kbs. This attack technique has so far been the most robust and reliable cache-based side-channel attack demonstrated in a Cloud environment. At time of writing, all other sequential cache-based side-channel attacks have been based on this technique, making it a good example of a canonical attack. Since all cache-based side-channel attacks in the Cloud rely on this basic technique, a successful inhibition of its principles would mitigate all currently viable attacks, in-cluding some of the more dangerous variations [37]. For these reasons, this particular side-channel attack has been implemented and is used as an example attack in our
CHAPTER 4. SIDE-CHANNEL ATTACKS 26
system’s evaluation.
4.2
Parallel Side-Channel
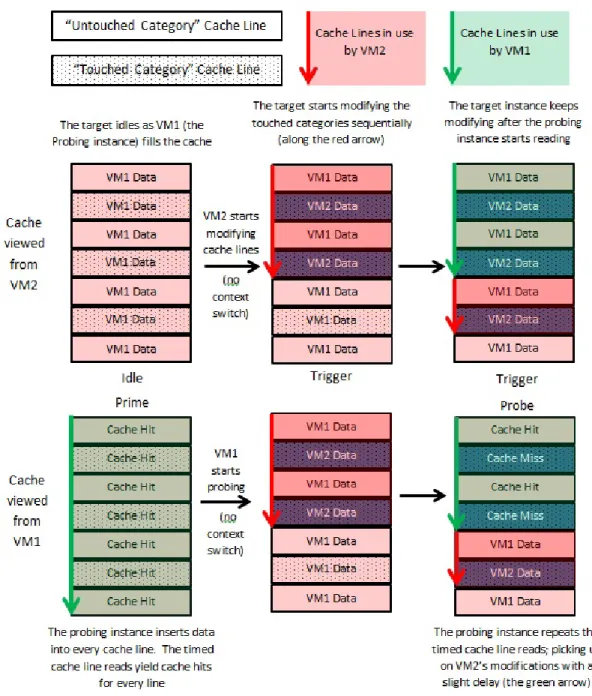
While the previous section describes a sequential side-channel, the technique can easily be adapted on a shared-cache system to become a parallel side-channel. In this case, the probing and target instances are each running on a separate core but have parallel access to some shared cache. While the cache access is essentially the same, the parallel technique omits the need to trigger between VMs because both the Trigger and the Probe steps are happening concurrently.
Much like the sequential technique, the process begins with the probing instance priming the cache. Once the cache is primed, rather than context switching to the target instance the probing instance starts the “Probe” step. Likewise, once the priming is done, the target instance can start the “Trigger” stage. In this way, the technique functions the same way as the sequential version, except that the “Trigger” and “Probe” steps are occurring at the same time. As both VMs cannot access the same cache lines at the same time, they instead each work on a section of the cache. Therefore, while one set of cache lines is being read, another can be modified by the other VM. This process is depicted in Figure 4.2. with the set of cache lines being read by VM1 highlighted in green and the set being modified by VM2 in red.
As might be expected, the parallel technique is less reliable as an attack medium, as there tends to be more noise in the system. To date, only a sequential side-channel attack has been demonstrated to be able to do serious damage in the Cloud [37]. However, while more difficult to use, parallel channels still hold the potential to be used in such an attack, and they can still be used to gain otherwise inaccessible
CHAPTER 4. SIDE-CHANNEL ATTACKS 27
CHAPTER 4. SIDE-CHANNEL ATTACKS 28
information about a VM.
4.3
Summary
This chapter describes the current state of cache-based side-channels in the Cloud. It separates the channels into two categories, Sequential and Parallel, based on the type of cache access each requires. For both types of channels it describes a basic communication scenario in which two VMs attempt to use the channel as a means of illicit communication.
The attacks described in this section are intentionally rudimentary and rely on only the most basic properties of a proper attack. This serves for both clarity and generality’s sake as the attacks are both simple to comprehend and act as a very general attack that would work in a wide variety of scenarios. The simplicity and basic structure of the attacks shown argue that if these attacks can be prevented from occurring within a system then that system should be proof against the more complex varieties. This argument stems from the idea that the rudimentary attacks are less sensitive to noise and error, easier to implement, and rely on the same hardware vulnerabilities as the more complicated attacks.
Chapter 5
Selective Cache Flushing
This chapter details our approach to solving sequential cache-based side-channels in the Cloud. It describes what attributes of a sequential cache-based side-channel can be inhibited to prevent its use. It goes on to illustrate how these exploits can be used in a Cloud environment without violating the requirements set out in the Cloud model in Section 2.1 and provides the foundation of our solution. From here we discuss known or expected issues that would arrive from taking the suggested approach. Included in this discussion are countermeasures that can be taken, and circumstances that can mitigate these issues. The chapter concludes by describing how our solution is realized and evaluated. This includes what concrete requirements the solution demands, as well as how it was incorporated into an established Cloud system. This system is then compared with the existing state-of-the art in terms of security against side-channels and general performance.
CHAPTER 5. SELECTIVE CACHE FLUSHING 30
5.1
Overview
The key to the PTP technique, and, in essence, to all sequential cache-based side-channels, is to grant both the probing and the target instances some level of overlap-ping access to a shared cache resource. Since access to said resource cannot be denied to either party without compromising the fairness of the system, our solution focuses on disabling the overlapping aspect of the cache.
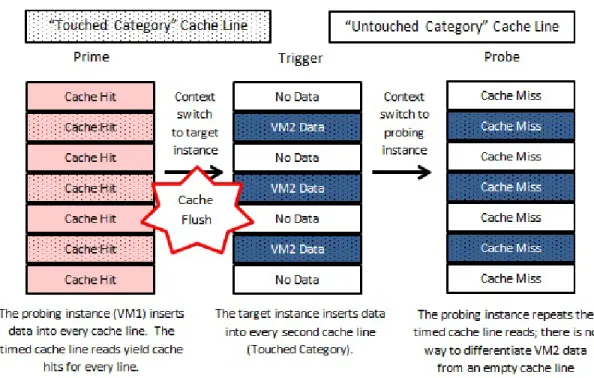
Much like the principle of VM isolation, our solution attempts to isolate the data in the cache based on the VM that is using it. This can be done by designing the system such that both parties view the cache as flushed (having no cache line that yields a cache hit without first incurring a miss for the current context), upon gaining access to the cache. Establishing this flushed state would prevent the possibility of a cache-based side-channel by disallowing the probing instance to ever establish a base-line (by priming). More specifically, whenever the probing instance attempts to prime the cache, its base would be destroyed, as the cache would flush every time the probing instance regains context. Our solution’s effect on the PTP technique is depicted in Figure 5.1.
Our solution inhibits the PTP technique by flushing the cache between the Prime and Trigger steps, thereby preventing the probing instance from ever seeing a pat-tern in the cache hit data. Additionally, if the system supports cache warming (the saving of the cache’s state on a context switch) the flush can be applied within this subsystem. This would allow the cache to retain useful data for the VM, while still preventing each VM from seeing if another has used the cache. A cache warming technique was not applied in our system as it would not make the system any more secure, it is instead left for future work.
CHAPTER 5. SELECTIVE CACHE FLUSHING 31
Figure 5.1: Our Solution’s Effect on the PTP Technique (Sequential)
Our solution can be implemented directly into the hypervisor, thereby conforming to the Cloud model defined in Section 2.1.
5.2
Expected Issues and Mitigations
Our proposed solution involves a selective cache flushing technique that is imple-mented directly into the hypervisor. Such an approach would prevent side-channel attacks by flushing the cache during a context switch between VMs for which a side-channel could occur.
The chief drawback of a cache flushing approach lies in the levels of overhead that such a technique may generate. The overhead from our solution manifests, principally, in two forms: One is that, unless special precautions are taken, such as
CHAPTER 5. SELECTIVE CACHE FLUSHING 32
cache warming, the cache will return to a guest in a blank state, slowing down the system by minimizing cache hits. Second, reverting the cache to this blank slate for every VM would add overhead to the system. These sources of overhead are summarized in the following subsections as the Reduced Cache Usability and the Cache Flushing Overhead.
5.2.1
Reduced Cache Usability
The reduced usability, or effectiveness, of the cache can be mitigated by observing that, in a canonical cache-based side-channel attack, the attacker would be priming the cache with every time slice allotted to it. Doing this would place the cache in a functionally flushed state for any VM allocated time immediately after the probing instance. By priming the cache, the attacker essentially puts every other VM into a state similar to that of the proposed solution (flushed). In this way, the secure system incurs no more overhead than a vulnerable system currently under attack.
Additionally, the overhead generated within a VM by starting with a flushed cache should be negligible in most cases. Unlike with process level context switching, under most circumstances, each guest’s time slice would likely use a great deal of the cache (depending on memory requirements for the workload). This would leave each successive guest with few warm cache lines when it runs next. The exception would be if a guest ran such small memory requirements that its cache lines were not overwritten by the time it regained access to the CPU. Under these circumstances, having a warm cache would not likely grant any of the guests much use, since they would only be using a few lines. Either option implies that starting each VM with a blank cache should not incur a large amount of overhead compared to process-level
CHAPTER 5. SELECTIVE CACHE FLUSHING 33
flushing.
To summarize, our system’s cache efficiency should be no less efficient than a system under attack via side-channel. In addition, the reduced effectiveness of the cache due to attack should be minimal because we are dealing with virtual machine level granularity. Compared to a single process, a VM should use a longer time slice and a larger portion of the cache, making it less likely for a VM to return to a warm cache state after having gaining a new time slice.
5.2.2
Cache Flushing Overhead
The second issue is a more difficult one to overcome, as it relies on implementing a solution with a minimal amount of overhead. The overhead generated from flushing the cache is dependent on two main factors: The ratio of flushes to context switches and the frequency of context switching in the system. These factors compound one another to generate the main source of overhead for the system. The more context switches the more flushes required, the more flushes required the more overhead generated.
When cache-based side-channels were being investigated in a non-virtualized en-vironment, flushing the cache was deemed too expensive for general use [21]. This was because of the high rate at which cache flushes would need to occur and the over-head that would come with each flush. However, a Cloud system does not require side-channel security on the process-level, but on VM-level granularity, as this is how they are allocated resources.
By comparison, a hypervisor will be running fewer VMs simultaneously than a regular OS would be running processes, and the rate of switching between them would
CHAPTER 5. SELECTIVE CACHE FLUSHING 34
be much lower. This means that the context switch rate between VMs in a Cloud system should be much lower than that between processes in a regular OS. Since the cache-flushing code can be inserted into the existing context-switching functionality the overhead generated by flushing the cache should be directly proportional to the context switch rate. With this in mind the reduced granularity of Cloud systems makes this technique more viable in a Cloud environment.
In addition to the reduced rate, some mitigating factors as to the frequency of flushing can be postulated. The frequency of flushing depends on the exact circum-stances during which the sharing of the cache could occur. For instance, flushing the cache would not be necessary if a guest VM switches to a VM that does not intend to access the cache (such as the idle domain). By tightening restrictions on when a context switch between virtual machines is considered vulnerable to a side-channel attack, we can reduce the frequency of context switches that require a cache flush.
In total, the issue of cache flushing overhead can be addressed in two ways si-multaneously. As mentioned earlier, the rate of context switching and the ratio of cache flushes to context switches compound to create the greater part of the solu-tions overhead. These two factors can be addressed individually. The frequency of cache flushing is naturally reduced by focusing on VM-level granularity, rather than process level granularity; and the ratio of cache flushes to context switches can be reduced by tightening restrictions on when a context switch is considered vulnerable to a side-channel. By addressing each factor, the net overhead decreases to a point where it is manageable in a standard Cloud system.
Addressing the aforementioned issues, the solution should prevent sequentially scheduled VMs from gaining any information about the previous VM’s cache usage,
CHAPTER 5. SELECTIVE CACHE FLUSHING 35
thereby blocking the prospective side-channel. Additionally, it should be implemented such that it conforms to the Cloud model. This implies that the solution cannot require any changes to the client-side code base nor have any non-canonical hardware requirements.
This adherence to the Cloud model suggests that the solution must be contained entirely within the hypervisor. Restricting the implementation to the hypervisor in this way distinguishes our solution as the only purely server-side defence for side-channel attacks in a Cloud environment.
5.3
Cache Flushing Technique
Our solution to sequential side-channels involves the incorporation of our cache flush-ing technique into a canonical Cloud system. The technique includes two new func-tions within the hypervisor: One is a server run process to flush the cache (revert the cache to a blank slate), and the other is a tainting algorithm in the scheduler for deciding when flushing the cache is necessary. The sequential side-channel solution was implemented using the code base for the open source Xen Hypervisor, Version 4.2.
5.3.1
Decision Algorithm
Flushing a high level cache on a modern machine can be a time consuming process. As mentioned in the above section, it is better to flush the cache only when necessary. Because the PTP technique requires that two VMs have consecutive access to a CPU core, flushing the cache is only required when this situation is able to occur. For
CHAPTER 5. SELECTIVE CACHE FLUSHING 36
instance, the Xen maps VMs to domains so that it can compare guest VMs, the host VM, and additional states (such as an idle CPU) using the same structures. If a CPU goes from executing Domain1 (VM1) to the Idle domain (Xen’s interpretation of an idle CPU), then back to Domain1 there is no need to flush the cache, as no side-channel could have been implemented over such a context. A tainting algorithm, Algorithm 1, was implemented to record which VMs own data currently in the cache and to determine when it is necessary to flush those data.
The Xen scheduler operates on scheduling units called VCPUs. Each VCPU represents a virtual CPU and is associated with a domain. A domain may have multiple VCPUs associated with it, but will always have at least one. According to our algorithm, each VCPU is given a new data field taint which indicates the origin of the data that currently reside in the CPU cache. Upon initialization, each VCPUs taint value is assigned the identifier for the domain it represents, with the exception of the Idle VCPU, which does not have an associated domain and is assigned an idle value.
The outcome of Algorithm 1 is that a cache flush occurs only when a context switch changes from one domain to another where the second domain has the ability to establish a side-channel with the first. Switching to the Idle domain, or to the same domain, will not invoke a cache flush. Avoiding a flush during these situations can be critical, as they will arise often in an elastic Cloud environment.
5.3.2
Flushing Function
The cache flushing functionality was implemented in two versions. The first version is a hardware dependent (referred to as the x86-secure for its use of the instruction set)
CHAPTER 5. SELECTIVE CACHE FLUSHING 37
Algorithm 1 Determines when flushes are necessary Function contextSwitch(DomX, DomY){
if DomX.taint == idle then
return;
end if
if DomX.taint == DomY.id then
return;
end if
if DomY.id == idle then
DomY.taint := DomX.taint; return; end if flushCache(); return; }EndFunction
implementation. The second version is an independent (referred to as the portable-secure) implementation.
If the hardware has built-in functionality for flushing the cache, such as with the x86 instruction set, this task can be accomplished more efficiently. Both versions are compared with the existing version of the Xen 4.2 hypervisor (referred to as the insecure hypervisor) in Section 5.4.5. In this case, we use the wbinvd function built into the x86 instruction set to flush the cache. This instruction invalidates every cache line by toggling the validity bit associated with that line after writing any relevant information back to memory.
The hardware independent, or portable-secure, cache flushing function is imple-mented by allocating a chunk of memory equal to, or larger than, the size of the hardware’s L2 cache (or the largest CPU cache available on the machine). Next, the chunk is divided into cache line sized blocks. When the flushing function is invoked, it iterates over these blocks, altering the data stored in each. The effect is that the
CHAPTER 5. SELECTIVE CACHE FLUSHING 38
cache line associated with each of the blocks is modified and will need to be written back to memory on the next access of that line. This will result in a cache miss as the cache has been overwritten.
The main difference between these two techniques is that the hardware-specific flush will typically invalidate the cache lines, toggling their validity flags and indi-cating to the CPU that they contain useless data while leaving the data themselves unchanged. By contrast the hardware independent solution will overwrite each cache line (fill them with useless data) but leave the validity flags untouched. Either tech-nique will cause following attempts to access the cache lines to miss, but the imple-mentation is very different.
5.4
Experimental Evaluation
This section describes the process of evaluating our solution. It describes the criteria by which we evaluate our solution’s effectiveness and the environment in which we conduct our experiments. We also describe the metrics by which we compare our solution to the existing state-of-the-art. These metrics are used to determine under what conditions our solution can be practically implemented into a commercial Cloud environment.
5.4.1
Objectives
The evaluation of our secure hypervisors focuses on obtaining the answers to two re-search questions: “Does this hypervisor prevent sequential cache-based side-channels”, and “What is the performance difference between this and the insecure hypervisor”.
CHAPTER 5. SELECTIVE CACHE FLUSHING 39
To answer these questions, we have simulated a single-server Cloud environment. In this environment, we subject each hypervisor to a conventional sequential cache-based side-channel attack, using the PTP technique, designed for use in Cloud environments. In addition, we subject each hypervisor to a series of workloads under different config-urations, designed to test different behaviours of the system. The resulting completion times are used to determine a likely increase in overhead.
5.4.2
Environment
The evaluation was conducted using the x86-secure, portable-secure, and insecure hypervisors with a Dom0 running Ubuntu 12.04 and each guest running a sparse installation of Ubuntu 11.04.
Each hypervisor was installed on a Sun Ultra 40 model machine, with 16GB of RAM and two Opteron 2218 2.6Ghz processors. Each processor contains two cores, each of which uses its own 1MB CPU L2 cache. Since this solution is specific to side-channels that do not have concurrent cache access, this machine was selected because it does not have a shared L3 cache. This machine is referred to in subsequent sections as the Sun Machine.
For the Apache and 7zip benchmarks, the hypervisors were also run on an IBM X3200 M3 model machine, with 32GB of RAM and a single Xeon X3430 processor. This processor contains four cores, each of which uses its own 256MB CPU L2 cache and a shared 8MB victim L3 cache. In subsequent sections this machine is referred to as the IBM machine.
From our experience with Cloud systems and examples in the related work [13], we believe these machines are comparable to servers that might be used in a Cloud
CHAPTER 5. SELECTIVE CACHE FLUSHING 40
environment.
Unless otherwise stated, all environmental parameters and configurations were left on their default values. It should be noted that in the following section, the term context switch refers to the hypervisor-level process of switching attention between virtual machines, as opposed to any pre-existing definitions.
5.4.3
Side-Channel Prevention
The hypervisors were evaluated using a side-channel attack based on the experiments done by [35] which uses the PTP technique. The side-channel Receiver and Sender programs, performing the functions of the probing instance and the target instance, respectively, were each installed onto separate guest instances. Both programs were executed simultaneously by co-resident guests on the test-bed machine. The attack was designed to send an identifiable string of 160 bits from the target instance to the probing instance. The attack was run ten times on each hypervisor to verify the consistency of the results.
In order to verify each hypervisor’s ability to block the side-channel under any conditions, the side-channel was given ideal conditions to work in. Specifically, the probing instance, the target instance, and Dom0 were the only virtual machines run-ning on the hypervisor and the first two were pinned to a single CPU core separate from the core on which Dom0 was pinned. This configuration represents the best possible conditions for a cache-based side-channel attack; any variations would make it more difficult for the attack to succeed. Our experiments assume that if an at-tack can be prevented under these conditions, then the same prevention would work for environments more hostile to the attack’s success. The viability of the defence
CHAPTER 5. SELECTIVE CACHE FLUSHING 41
mechanisms implemented should not be affected by these configurations.
5.4.4
Performance Experiments
The overhead generated by each of the secure hypervisors is expected to be directly proportional to the amount of “vulnerable” context switches. Because of the variable nature of Cloud workloads, it was necessary to evaluate the hypervisors under a variety of configurations. The hypervisor configurations selected for experimentation address three categories of variation: variations on the type of workload; variations on the Xen Credit scheduler [29] configurations; and variations of the workload’s magnitude.
A variation in the type of workload undertaken by the guests in the system can significantly affect the execution of the system. Because of this, the workloads used in the experiments are designed to emulate different types of applications one might find in the Cloud. To better accomplish this goal we evaluate our hypervisors with a combination of established benchmarks and customized benchmarks designed to generate high levels of overhead in the system.
System configurations consist of modifications to the internal variables which con-trol the scheduling of guests’ access to the CPUs. These values are used in Cloud environments to customize performance to the expected workloads the Cloud will process. Different amounts of work imposed concurrently on the system can also significantly affect performance. Cloud systems are designed to manage a dynamic number of clients and their workloads. Variation in the workload magnitude will simulate this attribute.
CHAPTER 5. SELECTIVE CACHE FLUSHING 42
benchmarks and two customized workloads with three different configurations. The results of these comparisons are listed at the end of the section.
List of Experiments
To evaluate the performance of our two systems, the following experiments were conducted:
A) Measurement of Cache Flushing Overhead
B) Apache Benchmark with Varying Number of VMs
C) 7zip Benchmark with Varying Number of VMs
D) Latency & Compute Workloads with Varying Timeslice Value
E) Latency & Compute Workloads with Varying Ratelimit Value
F) Latency & Compute Workloads with Varying Number of VMs
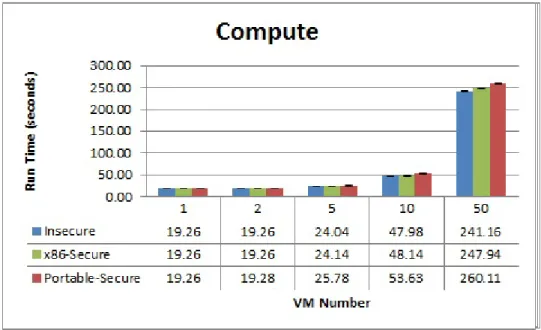
The two systems are evaluated in two types of environments. One uses standard benchmarks that represent workloads one might see in the Cloud; these include the Apache and 7zip benchmarks. The other uses customized workloads to attempt to generate a particularly difficult load for the systems, to determine what type of sce-narios they will fail in. In addition, the customized workloads are used to test the configuration parameters of the systems to determine the solution’s impact on differ-ent types of environmdiffer-ents. These workloads are referred to as the Latency workload and the Compute workload.
The two standard benchmarks used in the following experiments were conducted on two machines with different hardware. This was done so as to compare the effect
CHAPTER 5. SELECTIVE CACHE FLUSHING 43
of different cache sizes and types on our solutions. This solution is designed to be hardware independent and should therefore work on both systems, but we would expect the overhead to change based on the different cache designs.
The two machines used are specified in the above section (Section 5.4.2). As mentioned, these machines have significantly different cache sizes and layouts, but both are still machines we might expect to see in a Cloud environment.
It was decided that the two systems should be compared in two different custom environments: One with a higher expected rate of context switching, and one with a lower rate. Each configuration was tested for a computationally-heavy workload (the Compute workload) and a latency-sensitive workload (the Latency workload). The reasoning behind this decision being that a computationally-heavy workload would operate with less interrupts and cause less context switching. A latency-sensitive workload, by contrast, would do the opposite. Both would simulate workloads typi-cally found in Cloud environments, such as a major computational undertaking (solv-ing a large problem) or a primarily on-call service (a web/gam(solv-ing server).
The Compute workload consists of a program that calculates the first 1000 iter-ations of the Fibonacci sequence. Its implementation consists of purely arithmetic functions with no system calls in place. By contrast the Latency workload forks two processes that alternate their execution 500,000 times by use of semaphores. This implementation implies that both processes wake and block 500,000 times through-out one execution. The Latency workload was designed to simulate a high-latency scenario with many system calls, as processes wake and release their use of the CPU.
CHAPTER 5. SELECTIVE CACHE FLUSHING 44
A) Measurement of Cache Flushing Overhead
The first round of experimentation was to simply measure the amount of CPU cycles required for the context switch code to execute in the each of the three hypervisors. This was done because almost all of the overhead generated by our solution manifests in this functionality, and it serves to establish a good baseline for how much overhead we can expect due to context switching.
The Flush Timing experiments were performed by encompassing the context-switching functionality of the hypervisor in code that records the time-stamp counter in the CPU. We refer to the difference between the readings at the beginning of the function and at the end as the amount of time (in CPU cycles) that was required to perform the context switch, as this is the only section of code that should be affected by our modifications.
To run the experiment, we run two guest VMs on each hypervisor, pin them to the same CPU, and proceed to run CPU intensive code on them. The resulting times for the context switches are recorded in the hypervisor and averaged to generate the values shown in Tables 5.1 and 5.2.
It should be noted that these readings were taken using the selective cache flushing algorithm (Algorithm 1) and as a result the only timings considered are those that would be affected by our solution i.e., context switches between VMs that could potentially establish a channel. Depending on the workload, these timings could be frequent, or infrequent, but should always take more time than the default context switching code.
CHAPTER 5. SELECTIVE CACHE FLUSHING 45
B) Apache Benchmark with Varying Number of VMs
The Apache benchmark program (AB) is a standard http webserver benchmarking tool [8]. Apache was chosen because it is open source, frequently available, com-monly used as a benchmarking service, and represents the type of webservice one would expect to see running in a Cloud environment. In our experiments we run the benchmark simultaneously on 1, 2, 4, 8, and 16 co-resident VMs for each system. Each of the VMs have been distributed evenly amongst the CPUs. The benchmark yields an average number of requests per second that the system can handle.
C) 7Zip Benchmark with Varying Number of VMs
The 7Zip benchmark program is a benchmark designed to test the speed with which a system can compress data using the 7Zip program [24]. Like the Apache benchmark, this benchmark was chosen because it is open source, has a reputation for being robust, it represents a function that we would expect to be commonly found in the Cloud, and we expect its performance to be impacted by our solutions. At the same time, 7zip performs a fairly different function than the Apache benchmark and serves to add more variety to the test bed. The 7zip benchmark yields results in the form of MIPS (Millions of Instructions executed Per Second).
D) Latency & Compute Workloads with Varying Timeslice Value
The Timeslice parameter is a value, in milliseconds, which represents the default amount of consecutive time allocated to a VCPU for execution on a CPU core. A recent addition in the Xen hy