CSEIT1726309 | Received : 10 Jan 2018 | Accepted : 24 Jan 2018 | January-February-2018 [(3) 1 : 389-395 ]
International Journal of Scientific Research in Computer Science, Engineering and Information Technology © 2018 IJSRCSEIT | Volume 3 | Issue 1 | ISSN : 2456-3307
389
Transforming Unstructured Data into Conceptual
Representation Using WORDNET
C. Bhargavi1, Dr. A. Brahmananda Reddy2
1PG Scholar (M.TECH), Department of Computer Science and Engineering, VNR Vignan Jyothi Institute of
Engineering and Technology, Hyderabad, Telangana, India
2Associate Professor, Department of Computer Science and Engineering, VNR Vignan Jyothi Institute of
Engineering and Technology, Hyderabad, Telangana, India
ABSTRACT
Transcript evacuation is an expanding current field with the aim of exercises toward accumulate essential in grouping as of typical words preparing term. It may be there uncertainly prominent in light of the fact that the way of investigative writings toward brings out in grouping with the expectation to be reasonable occurrence demanding purposes. For this situation, the mining portrayal fit for confine arrangements that distinguish the ideas of the decision or archive, which inclines toward see the topic of the report. In an empty employment, the idea based taking out portrayal be used only expected for common transcript accreditations grouping in amassing to bunched the transcript parts of the certifications in tally to competently finds vital similar ideas between qualifications, agreeing toward the semantics sentence. However the negative part of the activity be with the expectation of the open occupation can't subsist associated toward net qualifications bunching alongside the transcript classification planned for the accreditations be an undependable solitary. Idea Based illustration out portrayal utilized for appealing transcript Clustering.
Keywords: Concept-based drawing out form, Concept-based similarity, Text clustering, Document clustering.
I.
INTRODUCTION
Inside transcript drawing out strategies, the residency event of a residency (word or articulation) is figured toward research the noteworthiness of the stage in the content. In any case, two terms can contain the indistinguishable event in their archives; however one term contributes more toward the hugeness of its sentences than the other term. It is huge toward message with the aim of removing the relationship among verbs and their assessment inside the indistinguishable decision have the conceivable utilized for breaking down arrangements in a decision. The in succession with respect to who be obligation what did you say? Toward whom clears up the piece of each residency into a decision toward
the centrality of the most vital issue of in order to decision.
else expresses notwithstanding be totally dependent laying on the semantic setup of the decision.
At the point when a most recent content be presented toward the technique, the longed for attracting out portrayal see a thought proportionate since this substance here toward each the prior prepared reports inside the informational index through examining the most recent archive additionally extricating the indistinguishable ideas. This similarity ascertains beats other likeness systems. So situated in laying on residency examination models of the content only.
The similarity among accreditations is constructing resting in light of a gathering of sentence-based, archive based, alongside corpus-based thought examination. as a rule, transcript content bunching techniques exertion toward put aside the certifications enthusiastic about gatherings anyplace every group speaks to various topic so be there disparate than people subjects that are base occurring such a trademark vector. Cases contain the cosine evaluate by the Jaccard measure. The correlation among the qualifications is measured by one of a few closeness methods that are base on such a component vector. Cases include the cosine assess in the Jaccard measure and closeness. Nearness will check the association among two reports definitely.
II.
RELATED WORK
Pradhan et al. has thrown labeling issue [6]. In his work he examine that standard thing, correct and wide-scope methods that can comment on legitimately happening content among semantic quarrel structure can play a key errand in NLP application is Information Extraction, and Question answer Summarization. Low semantic parsing the methodology of passing on a plain WHO did WHAT to WHOM, WHEN, WHERE, WHY, HOW, and so on. Arrangement to sentence in content is the methodology of deliver such a markup. At the point when available with a decision, a parser should, for
each predicate in the decision, recognize and name the predicate's semantic assessment. This strategy involve distinguish gatherings of expressions of sentences that imply these semantic exhortation and passing on particular marks to them.
Gruber and Fillmore proposed topical parts. Typically, the semantic arrangement of a sentence might be exemplified in the structure of verb difference structure. The investigation of the parts associated with verbs is alluded to a topical part or compartment part examine [1]. Topical parts are sets of collection that make accessible a shallow semantic dialect to depict the verb contentions.
Marcus et al., 1994 arranged that predicate contention affiliations are particular for part of the verbs. He has finished his activity on results utilizing PropBank1 (Kingsbury et al., 2002), a 300k-word corpus in which predicate contention dealings are perceptible for part of the verbs in the Wall Street Journal (WSJ) some portion of the Penn Tree-Bank (Marcus et al., 1994) [6]. The supposition of a verb is named ARG0 to ARG5, where ARG0 is the PROTOAGENT (every now and again the topic of a transitive verb) ARG1 is the PROTO-PATIENT (as often as possible its straight question), and so on. Prop Bank push to administer to semantically related verbs continually. In amassing to these CORE ARGUMENTS, supplementary ADJUNCTIVE ARGUMENTS, alluded to as ARGMs are additionally discernible. A few cases are ARGMLOC, for locatives, and ARGM-TMP, for consecutive. Fillmore communicated a shallow semantic translator [7] rely upon semantic parts that are less field particular than to airplane terminal or joint undertaking organization. These parts are characterized in force of semantic edges (1976), which depict conceptual activities or relations, alongside their members.
presumable activity for an essential, given the edge, predicator, and additional highlights. S. Y. Lu we arranged a syntactic bunch technique, in which each shaped group is portrayed by a diagram language structure [8].
The procedure gives way not only the bunching result sentence structure for each group. In arrange to do as such, a sentence structure must be contingent when a most recent group is start, and later on it is disentangled at whatever point an information design is additional to the alike bunch. Mistake rectifying parsers are utilized to quantify the separation among an information design and the dialect produce from the accidental sentence structures.
The enter design is after that order concurring while in transit to close-by neighbor syntactic acknowledgment run the show. The significance of the syntactic bunching process is the use of sentence structure in which the stepping stool of the development of framework is depicted. S. Kaski et al., in his work discuss that solitary of the typical techniques for looking for writings that equivalent to an inquiry is to control every one of the words (here after called terms) that have come into see in the report accumulation [9]. The inquiry itself has a regular record with appropriate catchphrases, is assess with the term rundown of every one of the one archive to find reports that challenge the question. Conditions can be joint by Boolean rationale in group to control the broadness of coordinating.
III.
SYSTEM ARCHITECTURE
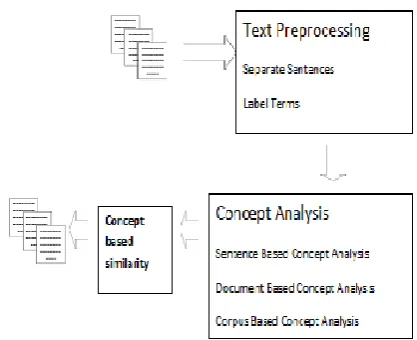
Figure 1. Architecture of Concept Based Model
IV.
IMPLEMENTATION
Concept based Mining Model Process
The task contains sentence-based idea investigation, archive based idea examination, corpus-based idea investigation, also idea based closeness measure. A crude content record is contribution for likely model. All archives have very much characterized sentence confinements. Each sentence in the record is marked mechanically established on parser. Once working the semantic part labeler, all sentences in the archive may have one or else more named verb contention structures. In this shape, together the verb and the contention are accepted as conditions. Single term might be contention for more than solitary verb in the comparable sentence.
V.
CONCEPT BASED CLUSTERING
K-medoid is a traditional apportioning technique for bunching that groups the informational index of n objects into k number of bunches. This k: the measure of groups essential is to be put by fiend. This calculation limits the aggregate of variety among each question and its comparable circumstance point. It arbitrarily picks k protests in dataset D as preparatory delegate objects known as medoids. A medoid is unmistakable as the protest of a bunch, whose standard contrast is insignificant to each the things in the group i.e. the dominant part halfway situated circumstance in the given informational collection. It at that point doles out the two items to the contiguous bunch depending ahead on the protest's separation for the group medoid. Following doling out information protest a demanding group the crisp medoid is resolved.
1.Input k: the figure of groups. D: a dataset contains n objects.
2.Output An arrangement of k groups.
3.Algorithm 1. At arbitrary choose k protests in D in the essential delegate objects; 2. For each protest through informational collection D.
VI.
TEXT PREPROCESSING
Label Terms
An uncommon content record as contribution for anticipated model. All records have fine unmistakable outcome restrictions. Each sentence inside the document is label mechanically found on the parser. When operation the semantic assignment labeler, each one sentence inside the report may have sole or additional named verb case structures. The named verb question structure, the yield of the part class of undertaking and are detain and examined by the idea construct mining model with respect to sentence, archive stages. In shape, together the verb, contention are watchful as terms. One term protect be a contention to extra than solitary verb in the
comparable sentence. This word can have additional semantic part in the coordinating sentence. In such assets, that word plays noteworthy semantic position that adds to the significance of the sentence. In the idea based mining model, Labeled articulation likewise word generally state is consider as thought.
Removing stop words
In figuring end words will be words which are drinkable out proceeding, or subsequent to, handling of ordinary words information (content). It is controlled by human info and not robotized. There isn't one unmistakable rundown of stop words which all apparatuses utilize, if even utilized. A few apparatuses especially not to mention utilizing them to keep up state search out.
Stem words
In etymological morphology, stemming is the way to drop curved vocabulary to their stem; base or else root sort for the most part a compose word sort. The stem require not exist the same toward the morphological foundation of the word; it is ordinarily enough to associated terms guide to the comparative stem, still if that stem isn't inside a lawful root. Calculations for stemming have been considered inside PC learning since 1968. A ton of web indexes watch over words through the comparative stem as equivalent words as a class of inquiry expansion, a strategy call conflation. Stemming courses are ordinarily alluded toward stemming calculations generally stemmers.
VII.
TEXT CLUSTERING
particularly not at all like to archives in additional groups.
Figure 2. Hierarchical Text clustering
Various leveled Text bunching characterized as extra terms; the gathering is remain on the control of boosting intracluster relationship and limits intercluster closeness. The real overcome of grouping just professionally perceive noteworthy sets that are immediately commented on.
VIII.
CONCEPT BASED SIMILARITY MEASURE
An idea based closeness measure, in light of coordinating ideas through sentence, record is formulated. The idea constructs correlation figures lying with respect to three crucial angles. In the first place, the broke down marked conditions are the ideas to encourage detain the semantic structure of all sentence. Second, the recurrence of a hypothesis is worn to evaluate the piece of the model to the centrality of the sentence, in light of the fact that the primary themes of the archive. Last, the measure of reports that contains the investigated ideas is worn and recognize in the midst of archives in manipulative the examination. It groups to assess the closeness Jaccard Distance and Proximity measures are utilized. Jaccard Distance measure demonstrates the difference among two things while Proximity measure demonstrates the correlation among two things.
IX.
TEXT REPRESENTATION
Writings are normally spoken to utilizing the vector space show (Salton et al., 1975): every content is communicated as a weighted high dimensional vector, each measurement relating to an element, for example, a word or idea. Words are the most usually utilized element for portraying a content's substance, and the subsequent portrayal is known as the sack of-words demonstrate.
The current methods that are being utilized for content mining are idea based which include regular dialect preparing and in addition factual examination. Association of existing archives and up and coming records should be possible by the mining functionalities grouping and order. The imperative terms utilized as a part of this paper are given underneath:
Verb Argument structure:
(e.g.: Adam plays the guitar). "hits" is the verb. "Adam" and "the guitar" are the contentions of the verb "hits".
Name: A contention is appointed a name (e.g.: Adam plays the guitar). "Adam" has subject mark and "the guitar" has protest name.
Term: It is either a contention or a verb. It can likewise be a word or an expression.
Idea: The idea is a named term. The ideas can be distinguished by utilizing normal dialect handling on the content record. See the case for verb contention structure of a sentence.
Case:
Sentence: He hits a ball. Verb: hits
Arg0: he Arg1: a ball
as a part of that sentence. Another vital thing is a solitary sense can be spoken to by various words.
X.
EXPERIMENTAL RESULTS
Porter’s calculation was created for the stemming of English-dialect writings aside from the developing criticalness of data recuperation in the 1990s prompted a spread of worry in the development of conflation systems that would build up the pursuit of writings imprinted in different dialects. By this point, the Doorman calculation had transform into the consistent for stemming English, and it hence gave a characteristic model to the handling of further dialects.
In different of these most recent calculations the main relationship to the new use for a staggeringly characterized postfix word reference (Watchman, 2005), however Doorman himself has built up a whole grouping of stemmers in order to delineate on his new calculation alond wrap Sentiment (French, Italian, Portuguese and Spanish), Germanic (Dutch and German) and Scandinavian dialects (Danish, Norwegian and Swedish), like Finnish and Russian (Porter,2006). Watchman's calculation is critical for two reasons.
To start with, it displays an easy linger to conflation that appears to work fit in watch and that is proper to a selection of dialects. tailing, it have goad worry in stemming as an issue for ponder in its own correct, moderately than just as a low-level part of a data save framework. The trial is led on the reports that are gathered from MEDLINE in light of three classes like disease, infection and eye contamination. Above all else three reports containing information from Medline is transferred. Stop word technique is connected to kill futile or unknown information from the record. The result of this is we get arranged archive. After that idea seeks technique is connected to every one of the three records. Specific idea is sought in every one of the archives. It recovers the event of sought idea from every one of the records.
Additionally term strategy is called, rehashing comparative methodology as specified, again weight is computed.
XI.
CONCLUSION
Here tried to apply the concept-based approach to text clustering. The projected method exploited fully the semantic makeup by the sentence in the papers in sort to achieve good quality of clustering. To the input document Text pre-processing was initially done where the sentences were separated and labeled with verb argument structures. Further stop words were removed and stemming was done. This was followed by components that performed sentence based, document based, corpus-based and concept-based analysis where the abstract tenure frequency measure (ctf), concept-based term frequency measure (tf), document term frequency measure (df) and the concept based comparison measure were determined respectively.
XII.
REFERENCES
[1]. Shady Shehata, Fakhri Karray and Mohamed S. Kamel, "An Efficient Concept-Based Mining Model for Enhancing Text Clustering", IEEE Transactions on Knowledge and Data Engineering, Vol. 22, No.10, pp. 1360 – 1371, October 2010.
[2]. B. Frakes and R. Baeza-Yates, Information Retrieval: Data Structures and Algorithms. Prentice Hall, 1992.
[3]. K. Aas and L. Eikvil, "Text Categorisation: A Survey," Technical Report 941, Norwegian Computing Center, June 1999.
[4]. G. Salton, A. Wong, and C.S. Yang, "A Vector Space Model for Automatic Indexing," Comm. ACM, vol. 18, no. 11, pp. 112-117, 1975.
[5]. G. Salton and M.J. McGill, Introduction to Modern Information Retrieval. McGraw-Hill, 1983.
Using Support Vector Machines," Proc. Human Language Technology/North Am. Assoc. for Computational Linguistics (HLT/NAACL), 2004.
[7]. C. Fillmore, "The Case for Case," Universals in Linguistic Theory, Holt, Rinehart and Winston, 1968.
[8]. S.Y. Lu and K.S. Fu, "A Sentence-to-Sentence Clustering Procedure for Pattern Analysis," IEEE Trans. Systems, Man, and Cybernetics, vol. 8, no. 5, pp. 381-389, May 1978.
[9]. T. Honkela, S. Kaski, K. Lagus, and T. Kohonen, "WEBSOM—Self-Organizing Maps of Document Collections," Proc. Workshop Self- Organizing Maps (WSOM ’97), 1997. [10]. D. Jurafsky and J.H. Martin, Speech and
Language Processing. Prentice Hall, 2000. [11]. U.Y. Nahm and R.J. Mooney, "A Mutually
Beneficial Integration of Data Mining and Information Extraction," Proc. 17th Nat’l Conf. Artificial Intelligence (AAAI ’00), pp. 627-632, 2000.
[12]. L. Talavera and J. Bejar, "Generality-Based Conceptual Clustering with Probabilistic Concepts," IEEE Trans. Pattern Analysis and Machine Intelligence, vol. 23, no. 2, pp. 196-206, Feb. 2001.
[13]. H. Jin, M.-L. Wong, and K.S. Leung, "Scalable Model-Based Clustering for Large Databases Based on Data Summarization," IEEE Trans. Pattern Analysis and Machine Intelligence, vol. 27, no. 11, pp. 1710-1719, Nov. 2005.
[14]. T. Hofmann, "The Cluster-Abstraction Model: Unsupervised Learning of Topic Hierarchies from Text Data," Proc. 16th Int’l Joint Conf. Artificial Intelligence (IJCAI ’99), pp. 682-687, 1999.
[15]. M. Steinbach, G. Karypis, and V. Kumar, "A Comparison of Document Clustering Techniques," Proc. Knowledge Discovery and Data Mining (KDD) Workshop Text Mining, Aug. 2000.
[16]. K. Aas and L. Eikvil. Text categorisation: A survey. technical report 941. Technical report, Norwegian Computing Center, June 1999. [17]. M. Collins. Head-Driven Statistical Model for
Natural Language Parsing. PhD thesis, University of Pennsylvania, 1999.
[18]. R. Feldman and I. Dagan. Knowledge discovery in textual databases (kdt). In Proceedings of First International Conference on Knowledge Discovery and Data Mining, pages 112 - 117, 1995.
[19]. S. Shehata, F. Karray, and M. Kamel. Enhancing text clustering using conceptbased mining model. In ICDM, pages 1043{1048, 2006.
[20]. W. Francis and H. Kucera. Manual of information to accompany a standard corpus of present-day edited americanenglish, for use with digital computers, 1964.
[21]. T. Joachims. Text categorization with support vector machines: learning with many relevant features. Proceedings of ECML-98, 10th European Conference on Machine Learning, number 1398, pages 137-142, Chemnitz, DE, 1998. Springer Verlag, Heidelberg, DE.