2017 International Conference on Computer, Electronics and Communication Engineering (CECE 2017) ISBN: 978-1-60595-476-9
Task Decomposition Exploration of Image Processing
Applications on FPGA-Based NoC
Ke PANG
1, Virginie FRESSE
2, Zai-feng SHI
3,*and Su-ying YAO
31School of Computer Science and Technology, Tianjin University, Tianjin, China
2Hubert Curien Laboratory UMR CNRS 5516, Jean Monnet University - University de Lyon, Saint Etienne, France
3School of Microelectronics, Tianjin University, Tianjin, China
*Corresponding author
Keywords: Network-on-Chip (NoC), Task decomposition exploration, Data-parallelism decomposition strategy, Task-parallelism decomposition strategy, Task mapping exploration flow, NoC emulation platform.
Abstract. As the key interconnection technique of System on Chip (SoC), Network on Chip (NoC) architecture is widely used in the high-throughput and low-latency image processing system designs. In addition to the bandwidth and latency, managing congestion resulted from imbalance network load is critical to improve the system performance. In this paper, one task decomposition exploration method on FPGA-based NoC is presented. According to different parallel properties of tasks of the application, subtask graphs are generated by taking advantage of different decomposition strategies. These subtask graphs are evaluated in timing latency and energy consumption based on FPGA-based NoC emulation platform. The experiments demonstrate that the proposed task decomposition exploration can help the designer select the most appropriate task decomposition scheme based on properties of the application to balance NoC net-work load and alleviate congestion.
Introduction
As a promising on-chip interconnection architecture, Network on Chip (NoC) provides effective connection between the varieties of processing elements on System on Chip (SoC). This modular and scalable architecture provides high bandwidth, high scalability, and low complexity communication to SoC systems, especially for image processing applications with big data. To achieve the optimal system performance, designers strive for all aspects of efficiency in all parts of the NoC design. In particular, energy consumption and latency penalty of on-chip communication relative to other parts have grown meaningful extremely. For the SoC system based on NoC, the load balance of the network is critical to enhance the transmission capability of NoC.
task nodes to one router or connect one task node to two routers to balance network traffic loads. But it needs one new Network Interface so that it cannot be used in the conventional NoC system.
In specific-application NoC design, one real image processing application can be described as one task graph [7]. One task node usually represents one module of the application which is implemented by one IP core on SoC. For different task nodes, the amount of data needed for processing and transmission is totally different. It easily results in the load imbalance problem on the network, which, in turn, leads to transmission congestion and local hot spots of energy consumption. Meanwhile, with the development of FPGA technology, dramatic growth of FPGA resources makes it feasible that task nodes can be decomposed into subtask nodes to balance the system load according to their properties.
The contribution of this paper is to propose one exploration task decomposition method on NoC. Depending on different task decomposition strategies, different subtask graphs are generated for the specific application. The evaluation of the subtask graphs based on the task mapping exploration flow [8] can provide abundant data about the timing delay results of these schemes. These data can help the designer to determine the most appropriate task decomposition scheme for the special application before implementing the application with real code (i.e. NoC with IPs). This exploration method can effectively shorten the design time and optimize the design quality. The exploration of task decomposition is based on the enough FPGA resources. It is open to any NoC topology.
Decomposition Exploration Method
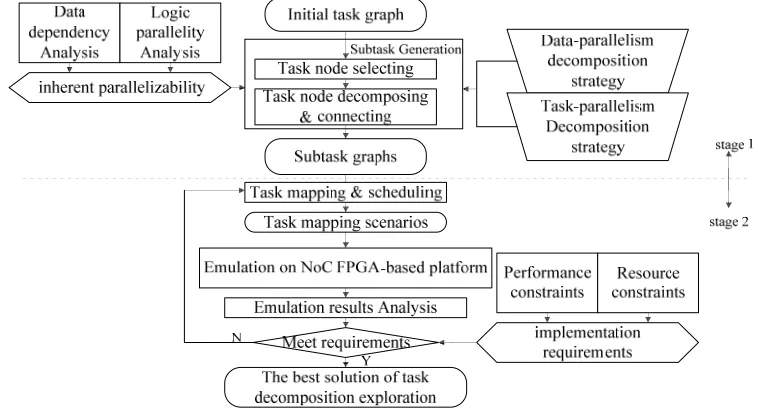
[image:2.612.110.489.369.573.2]Learning from the parallel computing theories, the task graph of the image processing applications can be decomposed into sub-task graphs to balance the network load of the NoC.
Figure 1. The basic flow of the task decomposition exploration.
According to the specific requirements (for example, workload balancing, energy consumption saving, and FPGA resources utilization) of the implementation and the inherent parallelizability of the application, some task nodes in the initial task graph of the application can be selected and divided into several subtask nodes to generate one or several subtask graphs for the application. This process is called ‘task decomposition exploration’, as shown as in Figure 1. It depends on the experiences of the image processing designer to some extent. It includes two stages: the first is to generate subtask graphs based on the analysis of the inherent parallelizability of the application. In the second stage, following the exploration flow proposed in [8], the subtask graphs generated in the first stage will be evaluated on the FPGA-based NoC emulation platform to shorten the evaluation cycle.
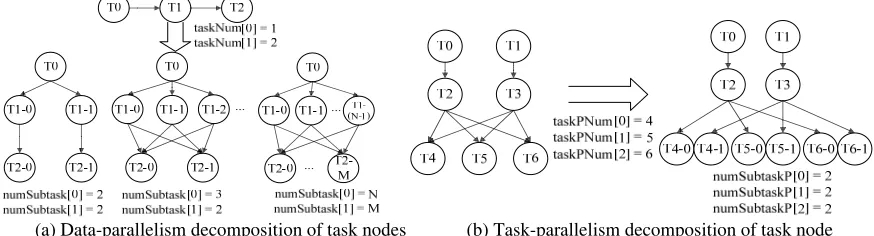
resources constraints into account. Considering the above two points, decomposition parameters are given for each task –ID of decomposed task node (‘taskNum’) and the amount of corresponding subtasks (‘numSubtask’). There are two kinds of decomposition strategies: data-parallelism decomposition and task-parallelism decomposition.
[image:3.612.89.526.126.244.2]
(a) Data-parallelism decomposition of task nodes (b) Task-parallelism decomposition of task node Figure 2. Decomposition principles of task node.
Data-parallelism decomposition always happens in the case that there are great amounts of data transmission between two task nodes. For each decomposed task node, the number of incoming and outgoing data for this task is divided. Depending on the amount of subtask nodes, the execution time of each subtask node reduced to some extent. In the decomposition examples shown in Figure 2(a), ‘E’ and ‘D’ represent the execution time of one task node and the transferred data amount between two task nodes, respectively. Data-parallelism decomposition splits the large amount of data transmission into several smaller ones. It avoids the concentration transmission of mass data, which helps to improve the transmission efficiency and the performance of each PE (subtask node) on NoC. Task-parallelism decomposition is usually executed on task nodes which are the common inputs or outputs for many other task nodes, as shown as in Figure 2(b). Here, the inputs or outputs of subtasks are parts of the original task’s inputs or outputs. The data transfer between every task node -- including original task nodes and generated subtask nodes -- remains unchanged.
Compared with data-parallelism decomposition, task-parallelism decomposition cannot decrease the transferred data amount between each task node directly. It mainly aims at improving the efficiency of PEs. By duplicating several subtask nodes with the same function and fewer inputs and/or outputs, the total data transmission of each corresponding subtask node decreases. Therefore, not only the data transmission is more efficient, but also the performance of each PE (subtask node) will be much better.
Each subtask graph will be evaluated on the NoC emulation platform based on FPGA. System performance is accessed based on the FPGA results. The appropriate decomposition scenario for one specific application is selected according to the evaluation.
Experiments and Discusses
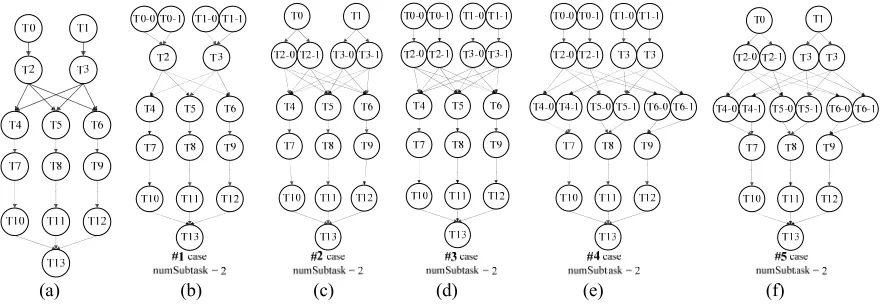
(a) (b) (c) (d) (e) (f)
Figure 3. Task graph of MSIM and decomposition examples in 5 cases with decomposition degree 2.
For one task decomposition scheme, timing merits are weighed up. Here, the timing merits include the total latency of all data transmission (TL). Latency is measured in clock cycles. In the experiment, the image processing application – Multispectral image (Figure 3(a)) – will be parallelized in 5 cases. The decomposition degree is from 2 to 9. It means that for each case, the decomposed subtask number of one task node is from 2 to 9 based on the original task graph. Figure 3 (b)-(f) describe the five schemes of task node parallelism when decomposing one task node into two subtask nodes.
Data-Parallelism Decomposition Exploration
For MSIM application, the centralized traffic of data transmission lies between the first 7 task nodes. Therefore, three data parallelism schemes #1 (Figure 3 (b)), #2(Figure 3(c)), and #3(Figure 3(d)) are proposed for the application. They attempt to decompose the task nodes into several subtask nodes to parallelize the data transmission. The decomposition degree is from 2 to 9.
Figure 4(a) depicts the total latency results with different data-parallelism decomposition schemes. The lowest points appears with different decomposition degree. For example, for #1 and #2, the lowest point is with Degree 3. However, for #3, the lowest point appears with Degree 2 and the total latency dramatically decreases compared with the former two. For a specific application, a larger decomposition degree doesn’t mean the better timing result. The designer should explore the best degree for one specific application with different attempts.
[image:4.612.85.532.488.599.2](a) (b) (c)
Figure. 4. Latency results of data-parallelism decomposition and task-parallelism decomposition based on data-parallelism with different degrees.
to equal to the decomposition degree. In contrast, the amount of subtask nodes of T4/T5/T6 depends on the remaining FPGA resources. The latency results shown in Figure 4(b) and (c) illustrate that the timing performance are improved further with task parallelism. The lowest points of the curves also appears with different decomposition degrees.
Summary
This paper addresses the important issue for the NoC design: exploring the most appropriate scheme of task decomposition to balance the network load on NoC. From one task graph of one specific application and the experience of the designer, different subtask graphs are generated according to different decomposition strategies. Following the task mapping exploration flow, these subtask graphs are emulated on the FPGA-based NoC emulation platform and depending on the emulation results, the appropriate decomposition scheme can be given to meet the specific requirements of the implementation. The complete exploration space is required for each decomposition strategy. The experiments show that the exploration method can help the designer to explore the appropriate task decomposition scheme for the specific image processing application to balance the network load on NoC.
Acknowledgement
This research was financially supported by the National Natural Science Foundation of China (NO. 61674115) and the National High Technology Research and Development Program of China (863 program, No.2012AA012705).
References
[1] Mohammadreza Binesh Marvasti and Ted H. Szymanski. An Analysis of Hypermesh NoCs in FPGAs, IEEE Trans. on Parallel and Distributed Systems, 26(10), 2015, 2643-2656.
[2] F.N. Sibai. A Two-Dimensional Low-Diameter Scalable On-Chip Network for Interconnecting Thousands of Cores, IEEE Trans. on Parallel and Distributed Systems, 23(2), 2012, 193-201. [3] Jili Yan. Enhanced global congestion awareness (EGCA) for load balance in networks-on-chip, The Journal of Supercomputing, 72(2), 2016, 567-587.
[4] Ruilian Xie, Jueping Cai, and Xin Xin. Simple fault-tolerant method to balance load in network-on-chip,” Electronics Letters, 52(10), 2016, 814-816.
[5] Jungsook Yang, Chuny Chun, Nader Bagherzadeh, et al. Load Balancing for Data-Parallel Applications onNetwork-on-Chip enabled Multi-Processor Platform, In 19th International Euromicro Conference on Parallel, Distributed and Network-Based Processing, Ayia Napa, Cyprus, 2011, 439-446.
[6] Ting-Jun Lin, Shu-Yen Lin, and An-Yeu (Andy) Wu, Traffic-balanced IP Mapping Algorithm for 2D-Mesh On-Chip-Networks, In 2008 IEEE workshop on Signal Processing Systems, SiPS 2008, Washington DC, 2008, 200-203.
[7] Ruxandra Pop, Shashi Kumar, A Survey of Techniques for Mapping and Scheduling Applications to Network on Chip Systems, Research Report, School of Engineering, Jönköping University, Sweden, 2004.
[8] Ke Pang, Virginie Fresse, Suying Yao, et al. Task mapping and mesh topology exploration for FPGA-based network on chip, Microprocessors and Microsystems, 39(25), 2015, 189-199.