25
Experimental Analysis on Predicting Customer
Purchase Pattern using Data Mining Algorithm
Usha Gill
1, Yatin Chopra
21
M.Tech. Student (CSE Dept.), CBS Group of Institutions Jhajjar, Haryana 2
Assitant Professor (CSE Dept.), CBS Group of Institutions Jhajjar, Haryana
ABSTRACT
In this Paper, we develop a new technique for more efficient frequent item set mining. Our method scans the database only one time where as the previous algorithms scans the database more than one time.
In this way our proposed algorithm will reduce the complexity of frequent pattern mining. We present efficient techniques to implement the new approach.
Keywords: data mining, predicting, customer, purchase, pattern.
INTRODUCTION
Data mining is primarily used today by companies with a strong consumer focus - retail, financial, communication, and marketing organizations. It enables these companies to determine relationships among "internal" factor such as price, product positioning, or staff skills, and "external" factors such as economic indicators, competition, and customer demographics. And, it enables them to determine the impact on sales, customer satisfaction, and corporate profits. Finally, it enables them to "drill down" into summary information to view detail transactional data. With data mining, a retailer could use point-of-sale records of customer purchase to send targeted promotions based on an individual's purchase history.
Facts, text, or document can be processed by a computer. Today, organizations are accumulating vast and growing amounts of data in different formats and different databases. This includes:
operational or transactional data such as, sales, cost, inventory, payroll and accounting
no operational data, such as industry sales, forecast data, and macro economic data
meta data - data about the data itself, such as logical database design or data dictionary definitions
The patterns, associations or relationships among all this data can provide information. For example, analysis of retail point of sale transaction data can yield information on which products are selling and when.
Information can be converted into knowledge about historical patterns and future trends. For example, summary information on retail supermarket sales can be analyzed in light of promotional efforts to provide knowledge of consumer buying behavior. Thus, a manufacturer or retailer could determine which items are most susceptible to promotional efforts.
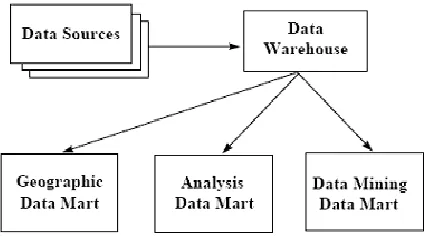
26 Figure 1: Data Warehouse and its Relations with Other Streams
DESCRIPTION OF USED TOOL NetBeans IDE
NetBeans IDE lets you quickly and easily develop Java desktop, mobile, and web applications, as well as HTML5 applications with HTML, JavaScript, and CSS. The IDE also provides a great set of tools for PHP and C/C++ developers. It is free and open source and has a large community of users and developers around the world.
Most developers recognize the NetBeans IDE as the original free Java IDE. It is that, and much more! The NetBeans IDE provides support for several languages (PHP, JavaFX, C/C++, JavaScript, etc.) and frameworks.
Figure 2: NetBeans screenshot
27 RESULT ANALYSIS
The data are collected over three non-consecutive periods. The first period runs from half December 1999 to half January 2000. The second period runs from 2000 to the beginning of June 2000. The third and final period runs from the end of August 2000 to the end of November 2000. In between these periods, no data is available, unfortunately. This results in approximately 5 months of data.
The total amount of receipts being collected equals 88,163. Each record in the data set contains information about the date of purchase (variable ’date’), the receipt number (variable ’receipt nr’), the article number (variable ’article nr’), the number of items purchased (variable ’amount’), the article price in Belgian Francs (variable ’price’ with 1 Euro = 40.3399 BEF) and the customer number (variable ’customer nr’). Note that the article price in the data set equals the unit price of the article times the amount of items purchased.
Over the entire data collection period, the supermarket store carries 16,470 unique SKU’s, but some of them only on a seasonal basis, e.g. Christmas items. Although most of the products are identified by a unique barcode (i.e. the barcode), some article numbers in the data set represent a group of products rather than an individual product item. For instance, this is the case with fruits, vegetables, meat, and a few others. In total, 5,133 customers have purchased at least one product in the supermarket during the data collection period.
Legal Issues
The data are provided ’as is’. Basically, any use of the data is allowed as long as the proper acknowledgment is provided and a copy of the work is provided to Tom Brijs (see details below). For papers with a bibliographic section, reference should be made to the following paper (which is available for download at http://citeseer.nj.nec.com/brijs99using.html) where parts of this dataset were used and described: Brijs T., Swinnen G., Vanhoof K., and Wets G. (1999), The use of association rules for product assortment decisions: a case study, in: Proceedings of the Fifth International Conference on Knowledge Discovery and Data Mining, San Diego (USA), August 15-18, pp. 254-260. ISBN: 1-58113-143-7.
28 Figure 4 : Executing the previous algorithm
29 Figure 6: Result produced by previous algorithm
30 CONCLUSION
In this paper, we presented a novel algorithm for mining web log data sets. Frequent mining of data mining is used for that purpose. Frequent item set mining is crucial for association rule mining. We have evaluated the performance of our proposed algorithm. It is fast. Also it is taking less main memory for computation in comparison to previous algorithm. It is the generation of all frequent item sets that exists in market basket like data with respect to minimal thresholds for support & confidence.
REFERENCES
[1]. A.M.Said, P.P.Dominic, A.B. Abdullah. “A Comparative Study of FP-Growth Variations”. In Proc. International Journal
of Computer Science and Network Security, VOL.9 No.5 may 2009.
[2]. Cai-xia Meng, An Efficient Algorithm for Mining Frequent Patterns over High Speed Data Streams. World Congress on
Software Engineering,IEEE 2009, 319-323.
[3]. Dongme Sun, Shaohua Teng, Wei Zhang, Haibin Zhu. “An Algorithm to Improve the Effectiveness of Apriori”. In Proc.
Int’l Conf. on 6th IEEE Int. Conf. on Cognitive Informatics (ICCI'07), 2007.
[4]. Fayyad U. M., Piatetsky-Shapiro G. and Smyth, P. “Data mining to knowledge discovery in databases, AI Magazine”.
Vol. 17, No. 3, pp. 37-54, 1996.
[5]. Tan P.-N., Steinbach M., and Kumar V. “Introduction to data mining, Addison Wesley Publishers”. 2006
[6]. Luo D., Cao L., Luo C., Zhang C., and Wang W. “Towards business interestingness in actionable knowledge discovery”.
IOS Press, Vol. 177, pp. 101–111, 2008.
[7]. Ling Chen, Shan Zhang,Li Tu, “An Algorithm for Mining Frequent Items on Data Stream Using Fading Factor”.33rd
Annual IEEE International Computer Software and Applications Conference.172-179,2009.
[8]. W.LIU, J.CHEn, S.Qu, W.Wan. “An Improved Apriori Algorithm. In Proc. IEEE International Conference, 2008,
pp.221-224”.
[9]. S.P Latha, DR. N.Ramaraj. “Agorithm for Efficient Data Mining”. In Proc. Int’l Conf. IEEE International Computational
Intelligence and Multimedia Aplications, 2007, pp. 66-70.
[10]. M. El-Hajj and O. R. Zaiane. “Inverted matrix: Efficient discovery of frequent items in large datasets in the context of
interactive mining”. In Proc. Int’l Conf. on Data Mining and Knowledge Discovery (ACM SIGKDD), August 2003.
[11]. M. El-Hajj and O. R. Zaiane. “COFI-tree Mining:A New Approach to Pattern Growth with Reduced Candidacy
Generation”. Proceedings of the ICDM 2003 Workshop on Frequent Itemset Mining Implementations, Melbourne, Florida, USA, CEUR Workshop Proceedings, vol. 90, pp. 112-119, 2003.
[12]. Luo D., Cao L., Luo C., Zhang C., and Wang W. “Towards business interestingness in actionable knowledge discovery”.
IOS Press, Vol. 177, pp. 101–111, 2008.
[13]. Ling Chen, Shan Zhang,Li Tu, “An Algorithm for Mining Frequent Items on Data Stream Using Fading Factor”.33rd
Annual IEEE International Computer Software and Applications Conference.172-179,2009.
[14]. Cai-xia Meng, An Efficient Algorithm for Mining Frequent Patterns over High Speed Data Streams. World Congress on
Software Engineering,IEEE 2009, 319-323.
[15]. Q.Lan, D.Zhang, B.Wu. “A New Algorithm For Frequent Itemsets Mining Based On Apriori And FP-Tree”. In Proc. Int’l
Conf. on Global Congress on Intelligent System, 2009, pp.360-364.
[16]. Varun Kumar,Rajanish Dass.Proceedings of the 43rd Hawaii International Conference on System Sciences, 2010 IEEE,
978-0-7695-3869-3.
[17]. Sonali Shukla, Sushil Kumar, Bhupendra Verma,A Linear Regression-Based Frequent Itemset Forecast Algorithm for
Stream Data. International Conference on Methods and Models in Computer Science, 2009.
[18]. ZHOU Jun, CHEN Ming, XIONG Huan A More Accurate Space Saving Algorithm for Finding the Frequent
Items.IEEE-2010.
[19]. Yong-gong Ren,Zhi-dong Hu,Jian Wang. An Algorithm for Predicting Frequent Patterns over Data Streams Based on
Associated Matrix. Ninth Web Information Systems and Applications Conference, 2012. 95-98.
[20]. Mahmood Deypir, Mohammad Hadi Sadreddini, A New Adaptive Algorithm for Frequent Pattern Mining over Data
Streams, ICCKE,2011, 230-235 FLEX Chip Signal Processor (MC68175/D), Motorola, 1996.
[21]. Abdullah Al-Mudimigh, Farrukh Saleem, Zahid Ullah Department of Information System: Efficient implementation of
data mining: improve customer's behavior, 2009 IEEE, (2014), pp.7-10.
[22]. Euiho Suh, Seungjae Lim, Hyunseok Hwang, Suyeon Kim: A prediction model for the purchase probability of