2017 International Conference on Electronic and Information Technology (ICEIT 2017) ISBN: 978-1-60595-526-1
Overlapping Community and Node Discovery Algorithm
Based on Edge Similarity
Dong-ming CHEN
1, Dong-fang SIMA
1,*and Xin-yu HUANG
11
Software College of Northeastern University, Shenyang, China
*Corresponding author
Keywords: Edge similarity, Line graph, Overlapping community, Over lapping node
Abstract. Most of community detection algorithms are designed from the perspective of nodes, which usually neglect the overlapping structure in networks. Whereas some of them hold the weakness of high complexity, inaccuracy and low stability. To solve the above issues, an overlapping community and node discovery algorithm based on edge similarity is proposed. In this paper, is established according to the incidence matrix. Then the algorithm is proceeding on line graph and finally the community detection results are restored to the original network, thus overlapping community and nodes are discovered. Several experiments are carried out on different datasets, demonstrating that the proposed algorithm is effective.
Introduction
Most of the existing community detection algorithms [1] in complex network [2] are designed from the perspective of nodes, in which a certain node can be divided into only one community. However, in real networks, some nodes usually belong to several communities, which are known as overlapping nodes [3] (or overlapping community [4]).For the overlapping nodes are related to many communities simultaneously, they usually act as a bridge between different communities and play an important role in networks. In the face of increasing scale of networks, further research on overlapping community and node discovery is of great significance.
Mining overlapping nodes in networks is usually achieved by discovering overlapping communities [5]. Although these researches had some achievements in the past, it is still lacking. Pallaet al. [6] proposed the famous Clique Percolation Method in 2005, however, the main problem is that a parameterkis difficult to determine. Gregory
put forward the CONGA [7] algorithm, where as the effect of the algorithm heavily depends on the empirical parameters. Generally, as for the current algorithm of overlapping nodes detection, there are many problems such as high complexity, low accuracy etc. To solve the above issues, this paper proposes an overlapping community and node discovery algorithm based on edge similarity. The object of study is transformed from node to edge, and then the overlapping nodes are discovered by the conversion between the line graph and the original network.
Algorithm Description
Line Graph
Definition 1: AnN×Nadjacency matrix A (Nis the number of nodes) is used to
represent the network G.If the elementAij=1, that indicates there is an edge between node i and node in the network, if Aij=0 , there is no edge between iand j.
Definition 2: AnN×Lincidence matrix B (
L
is the number of links) is used torepresent the network G. If the elementBiα=1, that means the node iis associated with
the edgeα, if the elementBiα=0 , then there is no link between the two.
In incidence matrix, the degreekiof a node and the number of nodes kα are attached to
a link α(always equal to two), shown as follows:
=
i i
k Bα
α
∑
,= i
i kα
∑
Bα(1)
Another expression of adjacency matrix is represented in the following formula:
=
ij i j i ij A B Bα α k
α
δ −
∑
(2) The method of constructing line graph is given by means of node mapping of bipartite network [8], the adjacency matrix C is used to represent the line graph of the network, and Crepresents a L×L incidence matrix. According to the transformation formula
mentioned above, the adjacency matrix expression of the line graph can be obtained:
(1 )
i i i
Cαβ =
∑
B Bα β −δαβ(3) When the element isδαβ=1in the matrix, there is a common node between two edges,
otherwiseδαβ=0, and this transformation does not lose any information in the original
network. Therefore, the theory of line graph is widely used.
Edge Similarity
Suppose that in network G, the edge and edge have a common nodep, we call
a shared node, node iand node jare contribution nodes. In the network topology,
neighbor nodes can usually provide a lot of useful information, so we can reasonably define the edge similarity by means of two nodes associated with one edge and the neighbor nodes between the two nodes.
In summary, this paper employs the degree of influence which comes from the common neighbor nodes of the contribution nodes to the two edges connected with contribution nodes, and the degree of influence of the contribution node itself on the edge which it connected with. Improved the RA index [9], and the method of computing the edge similarity is given as follows:
( ) ( )
1 1
( , )
( ) ( ) ( )
ip pj
z i j
S e e
k z i j
∈Γ ∩Γ
= +
Γ ∪Γ
∑
(4) WhereΓ( )i represents the collection of neighbor nodes of the nodei, Γ( )i ∩ Γ( )j is a
set of common neighbor nodes of node i and node j. k z( ) represents the degree of
node z, and Γ( )i ∪ Γ( )j denotes the set of all neighbor nodes of node i and node j.
Algorithm Process
Step 1: network initialization.
1) Build the original graphG V G( ( ), ( ))E G of the network.
2) Calculate the number of nodes and edges in the networkG, and give each node j
e
and edge an identifier, where the identifier of the edge is increased according to the input order .
3) Find the neighbor node set Neighbor i( )of each node i in the network.
4) Construct the line graphG' V G'( ( ), ( ))E G' according to the incidence matrix and
formula (3), and here the mapping relationE G( )→V G'( ) exists.
Step 2: Take the splitting algorithm to divide community in the networkG'.
1) Arbitrarily select two adjacent edges
e
ipande
pj in networkG , calculate thesimilarityS e( ip,epj) between the two edges in accordance with the formula (4). 2) Find the current minimum edge similaritySmin(eip,epj) in network G.
3) By the mapping relationE G( )→V G'( ), find the corresponding edge ep in the line
graphG'following the node in the graph , and remove edge ep.
4) According to modularity calculation formula:
1~ 2
1
[ ][ ] [ ][ ]
[ ( ) ]
j i
m
j m
i
E i j E i i
Q
E E
≠
=
=
= −
∑
∑
(5) Calculate the modularity Qcurrentof the current network G'(the modularity of the
initial community structure is Q0), m is the given number of the community division,E
represents the total number of edges of the network, and E i[ ][ ]j denotes the number of
edges within the communityi.
5) Compare Qcurrent with Qmax. If Qcurrent≥Qmax, the current Q value is recorded as
max= current
Q Q ,and simultaneously record the community partition results of the edge
graph G ',and repeat the procedure in step 2. Otherwise, go to step 3. Step 3: Discovering overlapping communities and nodes.
1) Traverse the edges in G' ,vi∈V G'( ). If vi∈community j[ ] , we can get the
corresponding edge in G by mapping the relation E G( )→V G'( ),that is ei=( , )u v ∈E G( ),
and add the two nodes uand v corresponding to the edge ei to the cluster j( ) (j∈[1... ]c ,
cis the number of communities).
2) ∀ ∈j [1... ],c cluster(1)∩cluster(2)...∩cluster j( ), represents the overlapping part of
the jcommunities.
3) Calculate the number of times in a networkG where each node occurs in
( )
cluster i (i∈[1... ])c , if the number is greater than one, that means the node exists in more
than one community, namely, the node is an overlapping node.
Complexity Analysis
Supposing an undirected network G, the number of nodes is n, the number of edges is m, and the complexity of the proposed algorithm is analyzed below:
a) Compute the similarity of the edges and modularity. The time complexity of the link similarity is the product of the number of nodes and the number of neighbor nodes of these nodes, that is,n*Card( ( ))Γi ,Card() represents the number of elements in a
collection. The time complexity of modularity is the square of the number of nodes in
G', that is m2. Since the time complexity of edge similarity is less than that of modularity, hence the time complexity of modular in step a) is .
b) Remove the edge of the minimum edge similarity, and repeat step a), until
max
current
Q <Q is satisfied. The time complexity of removing edges isO k( ), here k is the
number of edges removed.
Consequently, the overall time complexity of the algorithm is 2 ( )
O km .
p
G
Experimental Analysis
Experiment on Zachary’s Karate Club Dataset [10]
This dataset is used to verify the accuracy of the proposed algorithm. The initial number of community is 1. When the network is divided into 6parts, the modularity reaches its maximum value (0.5524). The nodes in the 6 communities were labeled and marked sequentially. Then, the partition results in the line graph are mapped back to the original network, and the final result is shown in Figure1.
Figure 1. Labeled network structure of the Zachary’s Karate club.
Figure 1 shows that some nodes are connected with the same color edge, and some are connected with different color edges, the nodes that connect the edges with more than one color means they belong to different communities, and these nodes are overlapping nodes. The nodes that link with the edges of the network G are added to
[image:4.612.104.507.345.435.2]the set of cluster corresponding to the edges, and the overlapping portions of these clusters are overlapping communities. The detailed results are shown in Table 1.
Table 1. Cluster of nodes for the Zachary's karate club dataset inG.
Cluster Node Cluster Node Cluster Node
C1
1, 2, 3, 4, 5, 6, 7, 8, 9, 11, 12, 13, 14, 18,
20, 22, 32
C2
2, 3, 4, 8, 9, 10, 13, 14, 18, 20, 22, 28,
29, 31
C3 5, 6, 7, 11, 17
C4
3, 9, 15, 16, 19, 21, 23, 24, 26, 27, 28,
30, 31, 32, 33
C5 25, 26, 28, 29, 32 C6
9, 10, 14, 15, 16, 19, 20, 21, 23, 24, 27, 28,
29, 30, 31, 32, 34
[image:4.612.99.514.493.582.2]The overlapping areas of these clusters are overlapping communities, and the nodes that appear repeatedly are overlapping nodes. Extract the network information from above and get the result as shown in Table 2.
Table 2. Overlapping communities and nodes distributions in Zachary club network.
Cluster Node Cluster Node Cluster Node
C1∩C2∩C4∩C6 9 C2∩C5∩C6 29 C1∩C2∩C6 14, 20
C1∩C4∩C5∩C6 32 C1∩C2 2, 4, 8, 13, 18, 22 C2∩C4∩C6 31
C2∩C4∩C5∩C6 28 C1∩C3 5, 6, 7, 11 C4∩C5 26
C1∩C2∩C4 3 C2∩C6 10 C4∩C6
15, 16, 19, 21, 23, 24, 27, 30, 33
To sum up, Zachary karate club network has 12 overlapping areas, and except node 1, 12, 17, 25, 34, the rest of the nodes are subordinate to several communities. we can conclude that everyone in this karate club, there are more or less different identities with other people, such as, it can be assumed that it was the same coach, whether they competition together etc. Therefore, each person corresponds to an overlapping identity and exists in overlapping groups.
Experiment on Dolphin Social Network Dataset [11]
corresponding clusters, and the overlapping portions of those clusters are overlapping communities.
Figure 2. Labelled network structure of the Dolphin social network.
[image:5.612.114.500.216.333.2]The detailed results are shown in Table 3.
Table 3. Cluster of nodes for the Dolphin social dataset in G.
Cluster Node Cluster Node Cluster Node
C1
0, 3, 4, 7, 8, 10, 11, 15, 18, 21, 23, 24, 28, 29, 35, 36, 39, 40, 43, 45, 50, 51, 52, 55, 59
C3
0, 3, 8, 12, 14, 16, 21, 24, 33, 34, 36, 37, 38, 40, 43, 44, 45, 46, 49, 50,
52, 53, 58, 61
C4
0, 7, 8, 10, 16, 18, 19, 20, 25, 26, 27, 28, 30, 36, 38, 42, 44, 47, 50
C2 0, 2, 10, 16, 42, 44,
50, 53, 61 C6 5, 6, 9, 13, 32, 41, 56, 60 C5
1, 5, 6, 7, 9, 13, 17, 19, 22, 25, 26, 27, 28, 31, 36, 39, 41, 48, 54, 57
The nodes that appear repeatedly (numbered with 0, 3, 5 6, 7, 8, 9, 10, 13, 16, 18, 19, 20, 21, 24, 25, 26, 27, 28, 36, 38, 39, 40, 41, 42, 43, 44, 45, 50, 52, 53,61) in the above Table 3 belong to more than one community, so these nodes are overlapping nodes. Dolphin social network totally has 62 nodes, representing 62 dolphins.As we know, dolphins are social animals, and a key member left the group will make the population splitting into several smaller groups. So it can be inferred that, if different dolphin groups are connected, there are overlapped parts.
Comparison Experiment
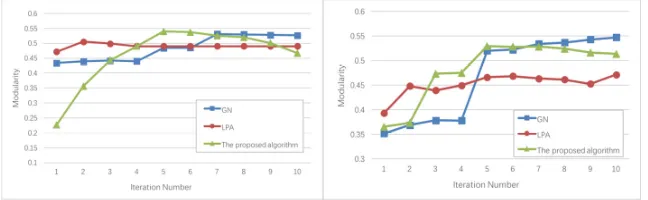
[image:5.612.145.469.545.645.2]Figure 3shows the clustering accuracy of the proposed algorithms comparing with GN [12] and LPA algorithm [13] on different datasets. The results indicate the proposed algorithm can get high modularity and the optimal classification results in less number of iterations. Therefore, it is concluded that the algorithm proposed in this paper outperforms GN algorithm and LPA algorithm in classification accuracy. Moreover, overlapping communities and overlapping nodes can be discovered simultaneously.
Figure 3. Clustering accuracy of different algorithms on Zachary data set and Dolphin dataset.
Conclusions
social network verified the algorithm is effective. With the comparison of GN and LPA algorithm, the proposed algorithm has higher efficiency and better accuracy. In addition, this algorithm has certain universality to the analysis of complex network structure in practice with general applicability. The next step is to apply the proposed algorithm in distributed environment to deal with large scale networks.
Acknowledgement
This work was partially supported by Liaoning Natural Science Foundation under Grant No. 20170540320 and Research project of Liaoning Department of Education under Grant No. L2015173.
References
[1] Kakkar S, Beniwal S. Discovering overlapping community structure in networks through co-clustering[C]//International Conference on Inventive Computation Technologies. IEEE, 2017.
[2] Gao Z K, Small M, Kurths J. Complex network analysis of time series[J]. Epl, 2016, 116(5):50001.
[3] Ahn Y Y, Bagrow J P, Lehmann S. Link communities reveal multiscale complexity in networks. [J]. Nature, 2010, 466(7307):761.
[4] I. Psorakis, et al., "Overlapping community detection using bayesian non-negative matrix factorization," Physical review, vol. 83, p. 066114, 2011.
[5] Todeschini A, Caron F. Exchangeable Random Measures for Sparse and Modular Graphs with Overlapping Communities [J]. 2016.
[6] Palla G, Barabási A L, Vicsek T. Quantifying social group evolution. [J]. Nature, 2007, 446(446):664-667.
[7] Gregory S. An Algorithm to Find Overlapping Community Structure in Networks[C]// European Conference on Principles and Practice of Knowledge Discovery in Databases. Springer-Verlag, 2007:91-102.
[8] Evans T S, Lambiotte R. Line graphs, link partitions, and overlapping communities. [J]. Physical Review E Statistical Nonlinear & Soft Matter Physics, 2009, 80(2):145-148.
[9] Hsu I W H, Volkova M S S. Link Prediction in Social Networks [J]. Springerbriefs in Computer Science, 2016:246-250.
[10] Zachary W. An information flow model for conflict and fission in small groups [J]. Anth Res, 1977, 33: 452-473.
[11] Amaral L.A.N, Scala A, Barthelemy M, et a1. Classes of small-world networks [J]. Proc. Natl. Acad. Sci. USA, 2000, 97(21): 11149-11152.
[12] Girvan M, Newman M.E.J. Community structure in social and biological networks [J]. Proc Natl. Acad. Sci. USA, 2002, 99(12): 7821-7826.