2017 2nd International Conference on Software, Multimedia and Communication Engineering (SMCE 2017) ISBN: 978-1-60595-458-5
Overlapping Community Discovery Algorithm Based on Local Extension
Hong-tao LIU, Fen LINGHU
*and Jie JIAN
School of Computer Science and Technology, Chongqing University of Posts and Telecommunications, Chongqing 400065, China
*Corresponding author
Keywords: Community discovery, Overlapping community, Social network.
Abstract. Detecting communities in social networks represents a significant task in understanding the structures and functions of networks. However, in real graphs vertices are often shared between communities, thus overlapping mining in the network community is more meaningful. In this paper, we propose an effective method for overlapping community discovery, which is to discover the initial core community and extend the core community until it reaches a stable condition. Through experiments on several real datasets, this method can effectively partition the overlapping communities.
Introduction
In recent years, the research of complex networks attracts more and more domestic and foreign scholars' attention. Community structure is an important feature of complex networks, and the research of community discovery on social network has become an important issue. Current scholars have proposed a large number of community discovery algorithms, in accordance with whether to allow the existence of overlapping nodes can be divided into overlapping community discovery algorithm and non overlapping community discovery algorithm. However, social networks are usually overlapping, for example, a person in a social network can belong to multiple groups, such as universities, companies, families, etc. So mining the overlapping community in the network is more meaningful.
In this article, we propose a method to find an effective overlapping community, the algorithm is mainly based on the local expansion, first find the initial core network through the node important degree, then according to the nodes membership degree function that we proposed in this paper and according to the community structure quality function add the appropriate node expansion the initial core, until the stopping condition is met.
The rest of this paper is organized as follows: the second chapter introduces the related work; the third chapter describes our algorithm; the fourth chapter is the experimental results; the last chapter summarizes and describes the further research work of this paper.
Related Concept
Assuming that the target network is an undirected graph (G={N,E}), N represents a series of network members, E represents a series of undirected edges. Each edge eij is the connection node i and node j.
Figure G can contain a range of communities (C={C0,..., Ck}). Each community (Ck={Nk, Ek})
contains a set of nodes (Nk) and a series of edges (Ek={eij|i,j∈Nk}).
Node Importance. Given a graph G and node u, the node importance NodeI[1] of node u is defined as:
. d * cfc(u) =
NodeI(u) u (1)
.1 e 2 cfc(u) jk
u u d
Where ui,ukN;ejkE. . e d V u uv u
(3)
Where cfc(u) represents the local clustering coefficient[2] of the node u, consider the connection
between the neighbors nodes of the node u. du represents the degree of the node u.euv is the edge
between node u and node v.
Membership Degree. The membership degree refers to the degree to which a node belongs to a community, given a graph G and node u, the membership degree can be defined as:
. v) Sim(u, v) Sim(u, C) B(u, U v v Nb(u)
C v v Nb(u)
(4)
. {v}] [Nb(v) {u}] [Nb(u) {v}] [Nb(v) {u}] [Nb(u) v) Sim(u,
(5)
Where the Nb(u) represents a set of neighbor nodes of node u; Sim (u, v)[3] represents the similarity
between node u and node v.
Quality Assessment Function. We through consideration the connectivity by the quality assessment function CQ to detection of community quality. The quality assessment function CQ can be defined as:
. F F F F CQ 2 out k 2 in k out k in k
(6)
. e F k C v u, uv in k
(7)
. e F
k k,v C
C u uv out k
(8)
Where Fkin represents the number of the internal connection of the community C, Fkout represents
the number of external connections to the community C.euv is the edge between node u and node v.
The Algorithm
Algorithm Description. Input. G= (N, E)
Step 6: If CQ({C}∪{Bn})>CQ(C), will be divided the node Bn into the core community C, delete the node Bn in Bl, to step 4;otherwise, Nb is set up to empty, return to the community C;
Step 7: Deleted the nodes belong to the community C from the NodeI, when NodeI is not empty, to step 3;
Step 8: Export all community C; Step 9: Algorithm ends.
Experiments and Results
[image:3.595.105.493.274.360.2]Experiments. In this part, in order to assess the performance of the algorithm, we through MATLAB platform to implement our method and design experiments, running on a PC with 2.94 GHz, 4GB memory and Windows 7 operating system. And we will consider the algorithm in some real world network. The Table 1 provides some real world networks.
Table 1. Five real-world networks.
Real-World Networks
Karate[4] Dolphins[4] Polbooks[4] Football E-mail
[5]
Nodes 34 62 105 115 1133
edges 78 159 441 613 5451
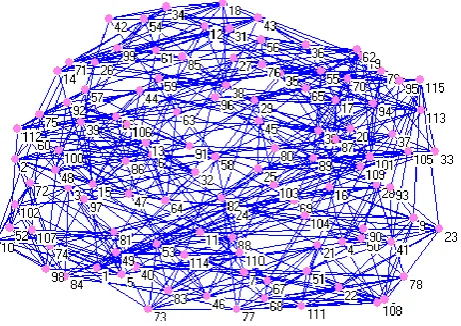
Football Network. The network of American football[6] games between Division IA colleges during regular season Fall 2000, as compiled by M. Girvan and M. Newman. The nodes have values that indicate to which conferences they belong in Figure 1. Is the Original network of football. When we apply our algorithm to this network, the results can be shown in Figure 2.
[image:3.595.183.414.442.605.2]Figure 2. Divided network.
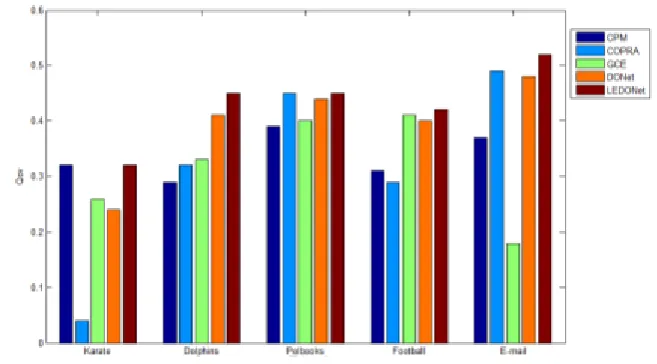
Evaluation criterion. Qov[7] function is an extension of Q[8] function, Qov function can be used to evaluate the structure of overlapping communities. We compared LEDO Net with four well-known algorithms: (1)CPM[5] which implements the clique percolation; (2) COPRA[9] which is based on label propagation; (3) GCE[10] greedy approach; (4) DONet algorithm.
. O O
1 2m
k k A 2m
1 Q
j i c i,j c
j i ij
ov
(9)
Where Qi represents the number of nodes i belonging to the community, m is the number of edges
in the network, Ki is the degree of node i, Aij is the element of the adjacency matrix. The bigger the
module value is, the better the community partition.
[image:4.595.133.462.466.648.2]Foundation of China (61402309), the Fundamental Research Funds for the Central Universities (No. XDJK2014B012), the National Social Science Foundation of China (13CGL146), the National Social Science Foundation of China (15BGL2729), the Study on the Key Common Characteristics of Network Transaction Fraud (14SKF01).
References
[1] Rhouma D, Romdhane L B. An efficient algorithm for community mining with overlap in social networks[J]. Expert Systems with Applications An International Journal, 2014, 41(9):4309-4321.
[2] Watts, D. J., & Strogatz, S. H. (1998). Collective dynamics of ‘small-world’ networks. Nature, 393(6684), 409-410.
[3] Palla, G., Derenyi, I., Farkas, I., & Vicse, T. (2005). Uncovering the overlapping community structure of complex networks in nature and society. Nature,435(7043), 814-818.
[4] Network data. (2013a). <http://www-personal.umich.edu/mejn/netdata/>.
[5] Network data. (2013b). <http://deim.urv.cat/aarenas/data/welcome.htm>.
[6] M. Girvan and M. E. J. Newman, Community structure in social and biological networks, Proc. Natl. Acad. Sci. USA 99, 7821-7826 (2002).
[7] Shen, H., Cheng, X., Cai, K., Hu, M.B.: Detect overlapping and hierarchical community structure in networks. Physica A: Stat. Mech. Appl. 388(8), 1706-1712(2009).
[8] Newman, M.E.: Fast algorithm for detecting community structure in networks. Phys. Rev. E 69(6), 066133 (2004).
[9] Gregory, S. (2010). Finding overlapping communities in networks by label propagation. New Journal of Physics, 12(10), 103018.