Rochester Institute of Technology
RIT Scholar Works
Theses
Thesis/Dissertation Collections
4-1-1998
Image compression using noncausal prediction
J. F. Marchand
Follow this and additional works at:
http://scholarworks.rit.edu/theses
This Dissertation is brought to you for free and open access by the Thesis/Dissertation Collections at RIT Scholar Works. It has been accepted for
inclusion in Theses by an authorized administrator of RIT Scholar Works. For more information, please contact
.
Recommended Citation
Image Compression using Noncausal Prediction
By
J.
F. Philippe Marchand
Rochester Institute of Technology
(1998)
A dissertation submitted in partial fulfillment of the
requirements for the degree of Ph.D.
in the Chester
F.
Carlson Center for Imaging Science
of the College of Science
Rochester Institute of Technology
April 1998
Signature of Author,
~
---,
Accepted by
Henry E. Rhody
Coordinator, Ph.D. program
;tf~
2 2 /
197('
CHESTER F. CARLSON
CENTER FOR IMAGING SCIENCE
COLLEGE OF SCIENCE
ROCHESTER INSTITUTE OF TECHNOLOGY
ROCHESTER, NEW YORK
CERTIFICATE OF APPROVAL
Ph.D DEGREE DISSERTATION
The Ph.D. Degree Dissertation of J.F. Philippe Marchand
has been examined and approved by the
dissertation committee as satisfactory for the
dissertation requirement for the
Ph.D degree in Imaging Science
Dr. Harvey Rhody, Thesis Advisor
Dr.Steven McLaughlin
Dr. Roger Easton
Dr. Raghuveer Rao
Dr. Peter Crean
DISSERTATION RELEASE PERMISSION
ROCHESTER INSTITUTE OF TECHNOLOGY
COLLEGE OF SCIENCE
CHESTER F. CARLSON
CENTER FOR IMAGING SCIENCE
Title of Dissertation:
Image Compression using Noncausal prediction
I, J.F. Philippe Marchand, prefer to be contacted each time a request for reproduction is
made. I can be reached at the following address:
J.F. Philippe Marchand
PO Box 473
Webster, NY 14580, USA
Abstract
Image
compression
commonly
is
achieved
using
prediction
ofthe
value ofpixels
from
surrounding
pixels.
Normally
the
choice
ofpixels
usedin the
predictionis
restricted
to
previously
scanned pixels.
A
better
prediction
canbe
achieved
if
pixels on
allsides of
the
pixelto
be
predicted are
used.A
prediction and
decoding
method
is
proposed
that
is
independent
of
scanning
order ofthe image.
The
decoding
process makes
use of aniterative
decoder. A
sequence
ofimages is
generated
that
converges
to
afinal image
that
is identical to the
originalimage. The
theory
underlying
noncausal prediction anditerative
decoding
is developed. Convergence
properties ofthe
decoding
algorithmare
studied and conditions
for
convergence are
presented.Distortions to the
prediction residual afterencoding
canbe
caused
by
storage
requirements,
suchas
quantizationand
compression and alsoby
errorsin
transmission.
Effects
ofdistortions
ofthe
residual onthe
final decoded image
areinvestigated
by introducing
severaltypes
of
distortion
ofthe
residual,
including (1)
alteration of
randomly
selected
bits in the
residual,
(2)
addition ofa
sinusoidal signalto
the
residual,
(3)
quantization ofthe
residualand
(4)
compression ofthe
residualusing
lossy
Haar
wavelet coding.The
resulting
distortion
in
the
decoded
images
wasgenerally
less for
noncausal predictionthan
for
causal
prediction,
both in terms
ofPSNR
and
visual quality.Most
noticeably,
the
streaks
found
in the decoded Image
afterACKNOWLEDGEMENTS
I
wishto
acknowledge
Dr.
Harvey Rhody
for
his
help
withthe
researchand
the
writing
of
this
dissertation.
I
wishto
acknowledge
Xerox
Corporation for
supporting my
studies atthe
Chester F.
DEDICATION
Table
of contents
Chapter
1
Introduction
1
1
.1Overview
ofLiterature
6
Chapter 2
Prediction-Based
Coding
10
2.1
Conventional linear
predictive
coding
1 2
2.2.
Image
Quality
Measures
14
2.3.
Entropy-based
performance measure
16
Chapter 3
Decoding
withCausal Predictors
17
Chapter 4
Decoding
Methods
19
4.1 Iterative
Decoding
Method
20
4.2
Constrained Iterative
Reconstruction Algorithm
27
4.3 Direct
Decoding
32
Chapter 5
Decoding
using
quantized
representation of residual35
5.1
Problems
withinteger
representationof residual35
5.2 Error
analysis
40
5.3 One-dimensional
error simulation42
5.4
Worst
Case
error45
5.5 Error for Random
truncation
45
Chapter
6
Results
52
6.1
Test
plan54
6.2 Effect
of
adding
randombit-flips to
the
residual56
6.4 Linear
Quantizer
64
6.5 Nonlinear
Quantizer:
Lloyd-Max
optimization
68
6.6
Optimizing
the
noncausal prediction
coefficient a70
6.7
Mathematica Simulation
73
6.8 Effect
ofadding
sinewaves
to
the
residual77
6.9 Effect
of
compressing
the
residual
withthe
Haar
wavelettransform
81
6.10 Description
of program
"Image"85
Chapter 7
Summary
88
7.1
Suggestions for future
work90
Table
of
Figures
and
Tables
Table
5-1
Simple
one-dimensional
decoding
36
Table
5-2
Decoding
with
integer
valued
pixels,
using
truncation
38
Table
5-3
Decoding
withinteger
valuedpixels,
using
truncation:
38
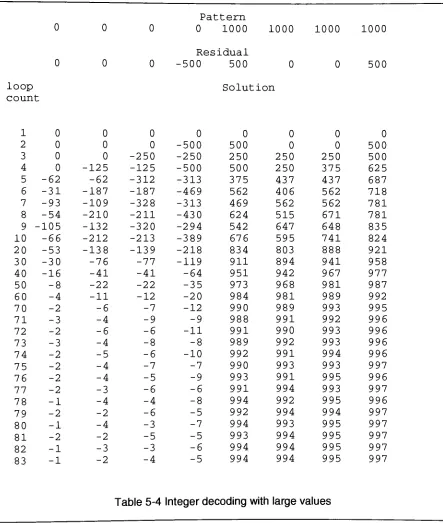
Table
5-4
Integer
decoding
withlarge
values39
Table
5-5
Error
sums and
PSNR for
worst case and random
48
Table
6-1 RMS Distortion
and
PSNR
ofthe
decoded image
78
Figure 1-1
The
neighborhood
of pixelX
2
Figure
2-1 Basic
prediction
block diagram
10
Figure 2-2 Compression
added
to
prediction
1
1
Figure 2-3 Channel
errors added
to
prediction1 1
Figure 2-4 Pixel
neighborhood12
Figure 3-1 Pixel
neighborhood
17
Figure
4-1 Iteration Model
20
Figure
4-2 Encoder
21
Figure
4-3
Iterative decoder
21
Figure 4-4 The
noncausal predictorin
matrixform
26
Figure 4-5 Contraction
mapping
29
Figure 4-6 Convergence
of
iteration
process31
Figure
5-1
Two-dimensional
image
42
Figure
5-2
One-dimensional
image
42
Figure 5-3 Peak
value of
impulse
response
44
Figure
5-4
Magnitude
of
impulse
response
44
Figure 5-5
RMS
error as
function
of a46
Figure 5-6 First-order
entropy Hi
ofresidual
vs.a,
for image
"Lena"47
Figure 5-7 The 1
-Dimpulse
response
of residualimpulse
at n=0
49
Figure 5-8
Same
as
Figure
5-7,
but
withentry
for
a=0.50removed
50
Figure 5-9 1D
errorimage from
rounded residualfor 0.49
>a>0
51
Figure 6-1 The
test
plan54
Figure 6-2
Adding
random
bit-flips to
residualimage
56
Figure
6-3
Using
a median
filter to
reduce
the
effect
ofthe
randombit
flips
58
Figure 6-4 Decoded image. 132
randombit flips. Predictor is
noncausal59
Figure
6-5 Decoded image. 132
randombit flips. Predictor is
causal59
Figure 6-6 Error in decoded image. 132
randombit flips. Predictor is
noncausal59
Figure 6-7 Error in decoded image. 132
randombit flips. Predictor
is
causal59
Figure 6-8 Decoded image. 132
randombit flips. Predictor is
noncausal +5-pixel
median
filter
appliedto the
residual60
Figure
6-9
Decoded image. 132
randombit flips. Predictor is
causal +5-pixel
medianfilter
appliedto the
residual60
Figure 6-10 Error in decoded image. 132
randombit flips. Predictor
is
noncausal
+Figure 6-1 1
Error
in decoded
image.
132
randombit
flips.
Predictor is
causal +5-pixel
median
filter
applied
to the
residual
60
Figure
6-12
Signal-to-noise
ratio of
decoded
image
with
bit
errorsin the
residual
image.
61
Figure 6-13
Quantization
ofthe
residual
63
Figure
6-14
The
causal and
the
noncausal predictors
64
Figure 6-15 Decoded image
withquantized residual, quantization step=20.
Predictor
is
noncausal
66
Figure 6-16 Decoded image
withquantized
residual, quantization step=20.Predictor is
causal
66
Figure 6-17 Error in decoded image
withquantized
residual, quantization step=20.Predictor is
noncausal66
Figure
6-18
Error in decoded image
withquantized
residual, quantizationstep=20.
Predictor
is
causal66
Figure 6-19
Quality
ofdecoded image for
causaland
noncausalpredictors
67
Figure 6-20.
Quality
ofdecoded
image for
causaland
noncausalpredictors
using
uniform quantizationand
Lloyd-Max
optimized quantization69
Figure 6-21 The PSNR
as a
function
ofentropy for
several values of a71
Figure 6-22 The PSNR
asa
function
ofafor
two
values ofthe
resulting
first-order
entropy
72
Figure 6-23 Impulse
responseof
errorin
residualfor
noncausal prediction
74
Figure 6-25
Impulse
response
for
causal and
noncausalprediction
for
different
sizes
ofthe
image
76
Figure 6-26
Adding
a sinusoidal signal
to
residual
image
77
Figure
6-27
Decoded
image
withnoncausal
predictor;
f=2,
amplitudes0
79
Figure 6-28
Decoded image
withnoncausal
predictor;
f=64,
amplitudes0
79
Figure
6-29 Error in
decoded image
withnoncausal
predictor;
f=2,
amplitude=10
79
Figure
6-30 Error in decoded
image
with noncausalpredictor;
f=64,
amplitude=10
79
Figure
6-31 Decoded image
withcausal
predictor;
f=2,
amplitude=10
80
Figure
6-32 Decoded image
withcausalpredictor;
f=64,
amplitudes0
80
Figure
6-33 Error in decoded image
with causalpredictor;
f=64,
amplitudes0
80
Figure 6-34 Error in decoded image
withcausalpredictor;
f=2,
amplitude^
0
80
Figure
6-35
Compressing
the
residual
withthe Haar
wavelettransform
82
Figure
6-36 PSNR
vs.file-size
for
several values ofthe
quantizationstep-size
for the
Haar
wavelet coefficients83
Figure 6-37 Decoded image
with noncausal predictorand
residualthat
wascompressed
withthe Haar
wavelet.Quantization
step=25
84
Figure 6-38 Decoded
image
with causal predictorand residual
that
wascompressed
with
the Haar
wavelet.Quantization
step=2584
Figure 6-39 Error in decoded image
above.PSNR=27dB
84
Chapter
1
Introduction
Images
are
commonly
stored and
transmitted
in digital form
by
assigning
a valueto
each of
the
picture elements
(pixels)
ofthe
image.
These
pixel valuesare
then
storedin
computer
files
ortransmitted
over communication channels.Because
there
aremany
pixels
in
animage the
files
become large
and a
large
amount
ofbandwidth
is
neededto
transmit the images. Image
compressionattempts
to
reduce
the
number ofbytes
needed
to
represent
the
image
and
thus
reduce
the
requirementsfor
storage
and
bandwidth.
Linear
predictionmay be
used as an element ofimage
or signal compression.Predictive
techniques that
weredeveloped for
random signalsand
time
series
have
been
adapted
for
use withimages. The
essentialidea is to
usea
model ofthe
process
to
predictthe
next valuein
adata
sequencebased
on currentand past
values.The
difference between
the
actual and predictedvalue,
calledthe residual,
containsthe
prediction error.
The
originaldata
sequence canbe
reconstructedfrom knowledge
of aset of
initial
conditions andthe
residual sequence.It
may
be
possibleto
encodethe
residual
for
storage ortransmission
withfewer bits
than
wouldbe
requiredfor
direct
encoding
ofthe
originaldata,
particularly
by
simpleencoding
methods.It is
ameans
that
may be
usedto
achieve a significant amount of compressionby
relatively
simple
processing.
Discrete
time
signals are sequences with a naturalpast
andfuture. To
apply
a process such as scanning.
Raster
scanning
is the
most
commonpattern,
but
othersare possible.
A
B
C
D
X
IL
E.
G_
H_
Figure 1-1 The
neighborhood
of pixelX
If
animage is
scannedin
row orderfrom
top
to
bottom,
then
pixelX in Figure
1-1 is
encountered
afterD but before E.
Preceding
values such asA,
B,
C
andD
canbe
usedto
predict
the
value ofX
that
willbe
seenby
the scanner, but
E, F,
G
andH
can
be
used
only
if
a
delay
buffer is
used.Use
ofa
buffer
poses no
difficulty
for image
encoding, but it does
create a
problemfor
reconstruction.In effect, the
reconstruction
algorithm needs
to
make use of valuesthat
have
not yetbeen determined. In
causalprediction pixel values
surrounding
the
pixelto
be
predicted
are usedin the
predictionprocess,
as shownbelow:
Predicted
value ofX
:P
=CaA
+CbB
+CCC
+CdD
(1-1)
Residual
R
=X-P
=X
-(CaA
The
predictor modelis
defined
by
the
coefficient
values.If
the
values arefixed
they
may
be
chosen
to
minimize
the
prediction
error overa sample
of representativeimages.
If
they
are adjustable
they
canbe
changed
by
an adaptive processto
reflectchanges
in
image
statistics.In
any
case,
they
rely
onthe
idea that
the
nearfuture
canbe
predicted
by
the
present and
recent past.Usually
the
changein
valuefrom
onepixel
to the
nextis
small.Sudden
changesin
the
value ofthe
pixels occur whenthe
image
has
edges
or other specialfeatures.
In
noncausal prediction pixel valuessurrounding
the
pixelto be
predicted areused
in the
predictionprocess,
as
shownbelow:
Predicted
value ofX
:P
=CaA
+CbB
+CCC
+CdD
+CeE
+C,F
+CgG
+ChH
(1
-3)Residual
R
=X-P
=X
-(CaA
+
CbB
+CCC
+CdD+
CeE
+C,F
+CgG
+ChH)
(1
-4)The
noncausal predictorhas
the
causal predictor as a subset.Therefore
anoncausal predictormustgive results
that
arestatistically better
than those
availableto
the
causal predictor.The
key
issue to be
addressedis the
problem ofreconstructing
the
image from
the
residual producedby
a
noncausal predictor.The
purpose ofthe decoder
is to
reconstruct
the
originalimage
from
the
residualimage.
The
residualis
againscanned
from
left
to
right andfrom
top
to bottom.
At
each pixellocation the
value of pixelX is
Causal
prediction:X=R
+(CaA
+CbB
+CCC
+CdD)
(1
-5)Noncausal
prediction*
=R
+(CaA
+CbB
+CCC
+CdD+ CeE
+C,F
+CgG
+ChH)
(1
-6)In the
causal case
(1-5)
this
caneasily
be implemented because the decoder
has
reconstructed
the
values
ofpixels
A,B,C
and
D
by
the time
it
needs
to
usethem
for
calculating
the
value ofX.
After
asingle pass
through
the image
the
originalimage has
been
reconstructed.But
with noncausalpredictors a
problemarises
because the decoder
also needsto
know the
values of pixelsE,F,G
andH. The
reconstructed values ofthese
pixels arenot
available whenit is
trying
to
reconstructthe
valuefor
pixelX.
Hence the
namenoncausal.
The
noncausaldilemma
canbe
avoidedby
using
aniterative decoder. In
the
iterative
decoding
processthe decoder
canreconstructthe
originalimage
by
making
aninitial
guess ofthe image. Rather
than
using
known
valuesfor the
noncausalpixels
E,F,G
andH
the
algorithm uses an estimate ofthose
values.Using
this
estimatethe
decoder then
canapply
the
predictionprocess, together
withthe
known residue, to
generate
a
newimage
that
is
closerto the
original.This
new
image is then
usedto
supply
the
valuesE,F,G
and
H for
a
better
reconstruction ofthe
originalimage. The
decoder
thus
creates a sequence ofimages.
It
willbe
shownthat the
image
sequence
converges under appropriate conditions.
The limit
ofthe
sequenceis
animage that is
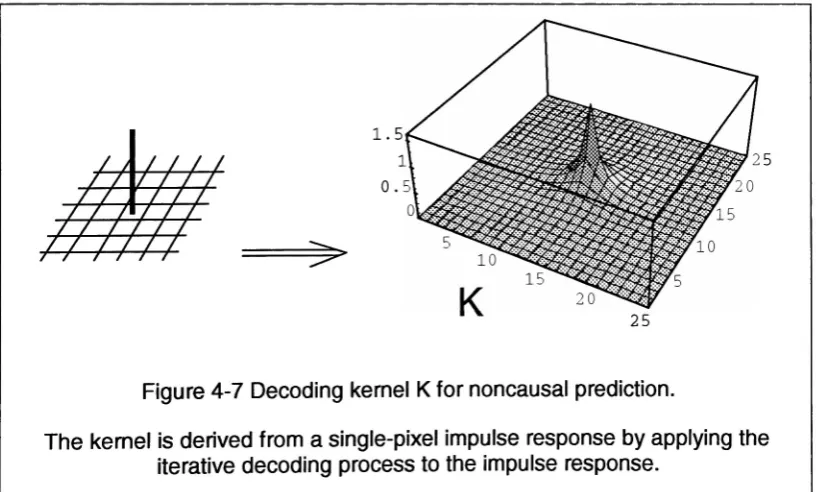
In direct reconstruction, the
iterative
approach
is
replaced
by
a
single-step
process.
In the
case
ofunconstrained
iterative
decoding,
the
process
canbe
replacedby
linear
filtering. The
appropriate
linear
filter
is derived
by
creating
a
convolution ofthe
residual
withthe
impulse
response
ofa single-unit
pixelthrough
the iterative
decoding
process.
This
method
assumes
that
the
reconstructionprocess
is
linear.
This
is
essentially
inverse
filtering,
where
the
reconstructionfilter
is
the
inverse
ofthe
prediction
filter. The
process works
wellbecause
the
predictionfilter is known
exactly.The inverse filter
is thus
obtained
by
performing
the
iterative
decoding
ona single-unit
pixel.
The
residualis
a complete
representation ofthe full
image because the
originalcan
be
restoredperfectly
by
the iterative decoding. We
aretherefore
interested in
the
question of
how
changesin the
residual will affectthe
reconstruction.Changes in
the
residual can
be
caused
by
lossy
compression ortransmission
errors.The
effects ofdistortion
ofthe
residualhave been inspected for
severalkinds
ofdistortion: integer
representation ofthe residual,
quantization ofthe residual,
andlossy
compression of
the
residualusing
a
wavelet compression method.Two
quantization
methods were used:
linear
quantization and nonlinearquantizationusing
the
Lloyd-Max
optimization algorithm.
The
wavelet compression method usesthe
Haar
wavelet
transform
followed
by
linear
quantization andGoulomb-Rice
coding.Other distortions
ofthe
residualthat
wereconsidered are:
intentional
corruptions
sine-waves
to the
residual.In
all casesthe
effect
onthe
reconstruction
is
found
to be
a
"soft"degradation. More
changein the
residual produces more change
in the
reconstruction.A
computer
programcalled
"Image" was writtento
implement the
predictionprocess and
the
reconstruction processes.
This
program
was usedfor
evaluating
the
effects
ofdistortion
ofthe residual,
asdescribed
above.The
programImage
wasalso
used
for
empirically
optimizing
the
prediction coefficients.It
wasfound
that there
is
anoptimum value
for the fourth
order noncausal predictioncoefficient
that
givesthe
best
tradeoff
between
compressed
file
size
ofthe
residualimage
and
signal-to-noiseratio
ofthe
reconstructedimage.
A
simulation ofthe
reconstructionprocess
was also performedusing
the
program "Mathematica"
in
orderto look
at
the
effects
of noisein the
residual onthe
reconstructed
image.
1
.1Overview
of
Literature.
There
is
very
little
publishedliterature
that
deals
withthe
subject of noncausalimage
prediction
and
reconstruction.Most
ofthe
publishedworkdeals
with standardscanning
sequences or special
scanning
schemes.This
is different from the
approachin this
dissertation,
wherethe
images
aretreated
as wholeobjects,
andthe
particularscanning
sequence usedis
only incidental,
asit is
neededto
represent
the
image in
In
"Interpolative
DPCM",[7],
Sethia
and
Anderson
apply
noncausal predictionin
an
Interpolative
DPCM
coder.This
lossy
coderis
applied
to
onedimensional Laplacian
and
Gaussian
sources.
These
signals
are speechlike. The
authors report a3 dB
improvement
in
signal-to-noise
Ratio
over
causalDPCM. A
noncausalinterpolator
is
included in
a
closed-loop
coder.
An identical interpolator is
usedin the decoder. The
interpolator
looks
several samples
back
and one sample
forward. The
reconstructionuses
a
direct interpolation
model ratherthan
aniterative
model.Yuan,
Ingle,
and
Manolakis describe "An
adaptiveImage
Coding
Algorithm
based
onNoncausal LPC
andVector
Quantization"[12].
The
algorithmis
appliedto
two-dimensional
images.
The
image
is
partitionedinto
blocks.
Noncausal
Linear
Predictive
Coding
analysis
is
performed
ontwo-dimensional
image blocks
and
the
resulting
linear
predictors areVector Quantized.
The
residualsignals are computed
for
each
block
and coded
with an adaptive vector quantizer.Spectrum
and
residualenergy
information from
the
LPC
codesis
usedto
controlbit
allocation.Experimental
resultsshow
that
goodcoding
quality
canbe
achieved atlow
bit
rates.This
method
implements
lossy
compression.This
decoding
processis
notiterative.
M.
Khansari
has
a
PhD
thesis
and several publications onthe
subject
ofnoncausal coding.
In
his PhD
thesis
[5]
"Block-Oriented Subband Decomposition
And
Linear
Interpolation
Source
Coding",
Khansari
refersto
noncausalprediction
as
Interpolation,
and
describes
methodsfor
performing
perfect
reconstruction onthe
process.
The
rate
ofconvergence
for
the
iterative
reconstruction processis
alsodetermined
.In
"Convolutional Interpolative
Coding
Algorithms"[6], Khansari,
et aldescribe
signal
coding
and
reconstruction
ona one-dimensional
model ofa
two-dimensional
image source,
using
a second-order
noncausal predictor(simple
interpolator).
The
algorithm uses
iterative
reconstruction
andmakes
use offorward
and
backward
refinements,
where
the
iterative
process
is
applied
from
the
beginning
to the
end
andfrom the
end
to the
beginning
ofthe
sequence
of samples.As
eachsample
is
updated,
it is
immediately
usedto
update ofthe
next
sample.This
paper alsodiscusses
quantization
effects
withopen-loop
and
closed-loop
coding.The
method usedhere
operates
withinthe
sequence ofdata
points.It
does
nottreat the
image
as an object.In "Noncausal
predictiveimage
coding"[1], Zhou,
Khansari
andLeon-Garcia
expand
the
processto two dimensional images. Perfect
reconstructionis
achieved
withan
iterative
reconstruction algorithm.To
increase
the
rate
ofconvergence,
the
"whirlpool"
algorithm
is introduced. The iteration is
performedaround
a number of"fixed
points",
wherethe
actual value ofthe image is
transmitted to
the
receiver.The
use of an entireimage
as
a "point"in
the
reconstructionprocess
getsaway
from
the
sequence ofdata
withinanimage
viewpoint.The
concept
ofthe
"fixed
points"analysis
in
Zhou,
etal.,
could
be
embedded as aconstraint
in the
constrained
iterative
decoding
process proposedin this
dissertation.
Note that the
"fixed
points"
referred
to
here
referto
pixelsin
animage
that
have been transmitted
separately
to
facilitate
the
process,
which referto
whole
images
in
a
converging
sequence ofimages.
The fixed
point
in the
iterative
reconstruction process
is the final image to
whichthe
processconverges.
Balram
and
Moura
[8]
[21]
describe
a combination
ofinterpolative
coding
andvector
quantization.
The
residualobtained
afterfourth-order
noncausal predictionis
quantized
in
groups
of4x4
pixels
using
64
code
vectors,
resulting
in
abitrate
of0.375
bits
per pixel.Schafer,
et
al.[19]
describe
a generalframework for
performing
iterative
restoration on signals
that
weredistorted
with adistortion
operator.The distortion
operator,
orits
approximationmatrix,
canbe
usedin
aniteration
to
recover anapproximation
to the
original signal orimage.
Conditions
for
validity
and convergence
are
described. The
paper appliesthe
process
to
several one-dimensional signals.This
algorithm
is described in detail
and applied
to
iterative
decoding
in
chapter4.
In
this
dissertation,
Schafer"s
constrainediterative
restoration algorithmis
usedas one
methodfor
decoding
the
originalimage from the
residualobtained
through
noncausal prediction.
The
predictivecoding
processreplaces
the distortion to
be
eliminated.
The
method enablesthe
use of constraintsthat
canbe
usedto
enforce
known
boundary
conditions ofthe
image,
like
the
fact
that the
value ofthe
image
pixels
is
zero outsideits
boundaries
andthat
each pixelis bounded in
valuebetween
aminimum and
a
maximum value(usually
0
and255
respectively).It
wouldalso enable
Chapter
2
Prediction-Based
Coding.
This
chapter presents
the
basic
concept
of predictivecoding,
whichis
a
methodto
reduce
the
amount
ofdata
encoded
for
eachpixel so
that the
total
image
canbe
represented
withfewer
bits.
Prediction-based coding
makes
use ofthe
fact
that
for
most
images
there
is
a
relationship
between the
value of each pixel andits
neighbors,
and
thus
knowing
the
values ofthe
neighboring
pixels allows oneto
estimate or predictthe
value ofa
pixel.It is
then
possibleto
specify
the
value ofthat
pixelmerely
by
encoding
the difference between
the
actual value andthe
prediction.Because
this
difference usually is
small,
fewer bits
are neededto
representthe
image.
The
residualr
is
the
difference between the
originalimage
xand
the
image
formed
by
the
predictedvalues,
asillustrated in Figure 2-1
.The
residual containsthe
same
information
as
the
original whena
reconstructionprocess exists
suchthat
x'=x.However,
the
residual willhave
a
lower first-order
entropy
andits
usemay,
therefore,
lead to improved
overall performance when combined with common compressionalgorithms such as
Huffman
encoders.S V r I .
^
Prediction
TV
^
reconstruction
Figure 2-1 Basic
predictionblock diagram.
The
introduction
of compressionand
decompression
is illustrated in Figure 2-2.
The
compression anddecompression
canbe
eitherlossless
orlossy.
Lossless
input,
so
that r"=r,
from
which
xcan
be
recovered.
The
performance
measure ofinterest
in that
case
is
simply
the
filesize
of rcrelative
to the
filesize
of x.Lossy
compressionand
decompression
willproduce
anoutput
rVr.The
performance
measurefor
this
casemust account
for the
difference
x'-xcaused
by
the
difference
r"-rand
comparethe
filesize
of rctoxPrediction
compression
de
compression
reconstruction
Figure 2-2
Compression
addedto
predictionThe difference between
causaland
noncausal predictionis in the
choice
ofthe
weight
applied
to
surrounding
pixels
for
the
purpose
of prediction.In
noncausalcoding,
any
pixelin
the
wholeimage
canbe
used,
whereasin
causalcoding
the
choice ofpixels
is limited
to those that
have been
encodedpreviously
in
the transmission
sequence.
The
noncausal approachusually
allows
for better
prediction.
f
.Prediction Transmissionchannel witherrors
decoding
Figure
2-3 Channel
errors addedto
predictionThe
introduction
ofa
lossy
transmission
channelis introduced in Figure 2-3.
Errors in
the transmission
ofthe
residualfrom
the
predictorto the
decoder
willproduce
an
output rVrand
thus
x'*x.The
performance measuresare
the
same as
in the
case
of2.1
Conventional
linear
predictive
coding
Pi
x
p7
p5
Figure 2-4 Pixel
neighborhood
In
most
images,
there is
considerable
correlation
among
the
gray
values ofneighboring
pixels.When
transmitting
the
value of pixelX
(Figure
2-4),
it
is
possible
to
predict
its
valuefrom
neighboring
pixels and
transmit
only
the
difference between
the
predictionand
the
actual value.In
generalthis
residual value canbe
encoded
withfewer
bits
than
the
originalvalue,
resulting
in
image
compression.A
commonway
to
predict
the
value ofpixel
X is
as a
weightedaverage
ofthe
surrounding
pixels.For
images
withfew
suddenchanges
in
intensity (edges)
this
is
a
good assumption.The
number of pixels considered
in
the
averagedetermines
the
"order" ofthe prediction,
e.g.,
an eight order predictor uses all eight neighbors.Better
prediction algorithmsproduce
residuals with smaller variances andlower
first-order
entropy
andenable
higher
overall compression ratios with conventional compression algorithms.Let
N(X)
be
a set
of pointsin the image
usedto
predict
the
value ofX
for the
point
X
shownin
Figure
2-4,
N(X)
=(Pi(X),
P2(X),...Pn(X)}.
The
P,
are
usually
chosento
be
neighbors ofX,
but
may
be located
anywherein the image.
Let
V(X)
be the
value ofthe
image
at a
pointX.
An
estimate ofV(X)
canbe
formed
from the
values ofthe
pixels
in N(X). One
modelis
the
linear
sum:V(X)=
2ciV(Pi)
PiN(X)
The
predictor model
is defined
by N(X)
and
the
coefficients
q.The
residualat
pixelX is:
R(X)
=V(X)-V(X).
(2-2)
The image
canbe
reconstructed
from
knowledge
ofR(X)
and
V(X)
.The
estimateV(X)
can
be
reconstructed
if
the
valuesin
N(X)
have been
computed.2.1.1
Scanning
sequence
Let
X(m)
be the
pixellocation
attime
m.The
scanning
process computesthe
residual
R(X(m))
in
an orderdetermined
by
the
sequence
X(m). The
particularscanning
sequence
is
unimportant
as
long
as
eachpixel
in the
image is
visitedat
least
once.
All
scanning
sequences
containthe
same
information,
and
may
be
considered
as
a
reordering
of somebase
sequence.Reconstruction
ofthe
value at pixelX(m)
requiresthat
V(X(m))
be
calculated
and added
to the
residualV(X(m))
=R(X(m))
+
V(X(m))
The
calculation canbe done
atthe
decoder
providedthat the
valuesin
N(X(m))
are
known.
Let
D(m)
={
X(l),X(2),...X(m)
}
be
the
set
ofpixels
decoded
up to
step
m.Let
us write
N(X(m))
as
the
union oftwo disjoint
sets
N0(X(m))
and
^(XOn))
such
that
N0(X(m))
=N(X(m))nD(X(m-l))
andNx
(X(m))
=N(X(m))
is
"causal"if
N0(X(m))
=N(X(m))
for
mS,2,3,....
Otherwise
the
modelis
"noncausal"or"clairvoyant".
The
advantage
ofnoncausal
linear
prediction over causallinear
predictionis
that the former
yieldsbetter
predictions.
The disadvantage is
the
difficulty
ofdecoding
the
residualThere
are
several waysto
deal
withthe
noncausaldecoding
problem,
andtheir
investigation is the
maintopic
of
this
thesis.
The
algorithms are
introduced in
chapters
3
-5.
Experimental
results and examples are presented
in
chapter
6.
It is
possible
to
usea
number of pixels otherthan the
eight shownin
Figure 2-4
in the
prediction.Indeed,
the
iterative
technique
can usepixels
from
anywhere onthe
image. It breaks
the
scanning
metaphor.In
chapter6
only
the
four
closest pixels(P2,P4,P5,P7)
are usedin
the
noncausal case.The
causal predictoris
uses athird-order
predictor with
the
pixelsPi,P2,P4.-
Some
studies with causal predictorshave
shownthat
often
there
is
only
a
marginal gainin
compression ratiobeyond
a
third-order
predictor[17].
A topic
offuture
researchis
the
investigation
of otherprediction sets.The
theoretical
foundation
for these
predictorsis
establishedhere.
2.2. Image
Quality
Measures.
Signal-to-Noise
ratiois
used as anindication
ofimage
quality
in
systemperformance
assessments.
This does
not
always correspondto
image
quality
as perceived
by
the
human
visualsystem,
but
it
provides an objectivemeasure
for
performance
Let
a
2be the
mean-squared
variation ofthe
values ofimage
xfrom
the
average value.
Let
a
\
be
the
mean-squared
variationin the difference
e=x-x'.A
measure
ofthe
quality
ofthe
reconstruction
is the
signal-to-noise
ratiodefined
as:SNR=
101og^-f-(2-3)
It is
common
to
referto
a\
and
a
\
asthe
"energy"in the
signaland
the
noise,
respectively.
A
common variation onthe
SNR
concept
is the "Peak Signal-to-Noise
Ratio"
(PSNR)
whichis the
energy
ofthe
error signalrelative
to the
maximumpossible
signal energy:
M2
PSNR
=10
log
\
(
2-4
)
\
where
Ms
is the
maximum pixel value.The SNR
andPSNR widely
usedto
evaluatethe
performance of compression algorithms.
A
high
value correspondsto
alow-energy
error.
However,
the
SNR
andPSNR
do
notnecessarily
correlate well with perceivedimage
quality.The Human Visual System
(HVS)
is
more
sensitive
to
some errorpatterns
than
to
others,
and
this
sensitivity
alsodepends
onthe
actualimage
content.For
example,
ringing
aroundsharp
edgesin the image
may
be
very
objectionable,
whilea
small changein
the
intensity
level
ofthe
image
may
notbe
noticed,
eventhough
both
errors
in
the
image
may
lead
to the
samePSNR.
The
main reasonto
usethe
SNR
andPSNR
is
the
fact
that
they
are not contextdependent
and
canbe
directly
computed
2.3.
Entropy-based
performance
measure
The information
content of
animage
xis
represented
by
the
entropy
H(x)
(Shannon,
1948). The
smallest
number ofdigits
that
canbe
usedto
encode x withoutinformation
loss is H(x). Because the image
xand
the
residual rare
informationally
equivalent,
H(x)=H(r).
Common
encoders achieve a
data
rate
that
is
approximatedby
the first-order
entropy.We
will usethe
changein
first-order
entropy,
H1(x)-H1(r)
as
a measure of predictionperformance.
The first-order entropy is
givenby:
H1=-XPxlogpx
(2-5)
X
with
px
the
probability
of occurrence ofany
symbolx.In the
predictionprocess,
we generate a new sequencer(n)
=F(x(n))
sothat
the
first-order
entropy
ofr(n)
is less
than
first-order entropy
ofx(n):The entropy
andthe
first-order entropy
areidentical
if
andonly
if there
is
nocorrelation
between
samples.If
all samples areindependent
andhave
identical
Chapter
3
Decoding
with
Causal
Predictors.
In
this
chapter
we
consider
the
methods
used
for
decoding
the
image
after
causalprediction-based
compression.
Causal
and
noncausal
predictors
aretreated
separately.
The
application
ofiterative
decoding
to
noncausal predictors
is
further
studied
in
chapter
4.
Decoding
is
straightforward
for
a
causal predictor.
The image is
scannedin the
sameway
as
during
prediction,
wherethe
value of pixelX is
predicted
from
the
preceding
pixels
(Figure 3-1).
Pi
P7
P5
Figure 3-1 Pixel
neighborhood
Let
X(m)
be the
pixelto
be decoded
attime
m,
and
N0(X(m))
be the
set ofpixels
used
in the
prediction:R(X)
=V(X)-V(X)
=V(X)-PiN0(X)
(3-1)
The
actual valueV(X)
of pixelX is
calculatedby
adding
the
residual
R(X)
to the
predicted value:
V(X)
=R(X)
+
V(X)
=R(X)
+
XciV(Pi)
PjeNoCX)The
accuracy
ofthe
reconstruction
does
not
depend
onthe
coefficient values.However,
the
first-order
entropy
does depend
on
them
through the
accuracy
ofthe
prediction.
Generally,
the
number
ofpixels
usedin the
predictionaffects
the
quality
ofthe
prediction.
Of
course
abetter
prediction willreduce
Hi
andthereby
the
number ofbits
needed
for
coding
the
residual with conventionalcoding
methods.However,
somestudies
have
shownthat
morethan
these
three
pixels
has
only
a
marginalimprovement
in the
performance of
the
performance[17].
Errors
introduced in the
residualR
afterthe
predictionprocess
will affectsucceeding
pixels; the
process"remembers". The
error propagatesforward
and createsChapter
4
Decoding
Methods.
Scanning
converts
a
two-dimensional
image,
into
a one-dimensional sequence ofnumbers.
Though
necessary
for image
transmission,
the
process
constrainsthe
optionsavailable
for decoding. In this
chapter
we consider aniterative
decoding
methodthat
generates a sequence
ofimages that
converges
to the
originalimage. The
operationsare
based
onthe
entire
image. The
result
is
a method
that
enablesa
larger
class
ofencoding
anddecoding
options.Three
variants ofthe
iterative
decoding
methods willbe
considered:the
base
method,
the
constrainediterative
decoding
method,
andthe
direct
method.Convergence
ofthe iterative
decoding
methods willbe
proven.Errors introduced in the
residual
image
by
transmission
or quantization willresult
in
a
distorted final image
that
4.1
Iterative
Decoding
Method
Figure 4-1
illustrates
the
process
ofiterative decoding. At
eachstep
ofthe iteration
anew
intermediate image is
generated.Each
newimage is determined
by
applying
the
linear
predictorto
each pixelin
the
previousimage
andadding
the
residual.The
residual
is identical from
one
iteration to the
next.The
process
thus
createsa
sequenceof
images,
from the initial to
the
decoded image. The
pixelsin image
Wj
canbe
reconstructed
in any
order orthey
canbe
reconstructedin
parallel,
based
onthe
pixelsin image
wM.Any
image
may
serveas
the initial image.
It is
often convenientto
usea
blank image (all
values=0)asw0.A
block diagram
ofthe
encoderis
shownin
Figure 4-2.
The
residualimage is
calculated
by
subtracting
the
predictedimage
from
the
original.To
differentiate
between
pixels andimages,
pixelswillbe identified
with uppercasecharacters,
(eg.
X),
and
images
willbe
identified
withlower
casecharacters,
(eg.
x and w).The
predictorP
X
p
Px_
G
s
+
Figure 4-2 Encoder
The decoder is
shownin Figure 4-3. The
process
is described
with a series ofintermediate
images
wn.At
eachpass,
a
predictionfor
each pixelis
calculated and
the
residual added.
This iteration
continues
untilno more
changes occur.A
fixed
pointis
achieved when
wn
=wn+1.The iteration
may
be halted
aftera measure
ofthe
difference
falls
below
an acceptablethreshold.
It
willbe
shownthat this
fixed
point represents
the
original
image
x.Wn-1
Equation
(4-2)
describes
the
image
sequence.
The initial
state
is
w0.Normally
this
is the
nullstate
with allpixels
having
the
value
zero.At
eachcycle, the
predictorP
is
applied
to the
image
and
the
residualis
added.
Consider
an operator
P
whichacts
onthe
image
xto
produce
the
image Px. We
require
that
Px
have
the
same
dimensionality
as
x.The
residualis:
r-x-Px
(4-1)
Clearly
allscanning
systems
that
werediscussed in
chapter3
may
be described
by
this
model.
We
now showthat
it is
possibleto
reconstruct xfrom
rby
using
aniterative
process, if P
satisfies certain conditions.Let
w0
be
anarbitrary
image
ofthe
samesize
as
r.Consider
the
sequence of operations:wn=Pwn.1+r
(4-2)
If P
is
additive,
so
that
P(u+v)=
P(u)
+P(v),
then
it is easy
to
seethat:
w1=Pw0+r
(4-3)
w2=P2w0+Pr+r
(4-4)
w =
P3wn+P
r+Pr
+r(4-5)
3 -J. YV0
And
we can expresswn
as:'n=Pnw0+XPkr.
(4-6)
where
Pk
denotes
the
application
ofP k times
and
Px
=x.
A
sequence
w0, w,, w2
wn
ofimages
is
generated
by
this
process.
Let
us consider
the
properties
ofthis
process.
Theorem.
Let
P
be
animage
operator
that
has
the
following
properties:1.
P(u+v)
=P(u)
+P(v)
(additive).
2.
IIPxll<llxll
3.
Px=x;P=l
for
any
xand a suitable
norm.A
matrix
normis
a measure
that
satisfies
the Matrix-Norm
Consistency
Condition [29]:
II
Pz II
<IIP
II Hz II
(4-7)
Matrix
norms
whichsatisfy
the
consistency
conditioninclude:
n
LA
norm:II
z|L
= maxYl
Z,,
I
(4-8)
j=l,2...n^
which
is the largest
column sum of absolute valueL
norm:llzll_
=max__IZ,,
I
(4-9)
i=l,2,..nZi
J=l 1Jwhich
is
the
largest
row sum of absolute valueThen the
sequence generatedby
n-1
k=0
Proof. Note
that
w-x =
Pnw0+
(4-11)
substitute
r=x-Px'n-x=
Pnw0+XPkx
(4-12)
n-l n-1k=0 k=0
All
but
the
first
and
last terms in the
sums are
identical,
and
thus disappear
by
subtraction.
Hence:
wn-x=
Pnw0+Px-Pnx-x
(4-13)
Since
Px
=xwe
have
wn-x=
Pnw0-Pnx
(4-14)
wn-x=
Pn(w0
-x)(4-15)
Since II
Pn(w0
-x)
II
<II
Pnl(w0
-x)
II
by
condition2,
this
is
adecreasing
sequence
ofpositive
terms.
The limit
limHPn(w0
-x)ll=0
(4-16)
n->oo
so
that
limNw
-x
II
=0
(4-17)
n->~>
Therefore
xis the limit
point ofthe
sequence,(more properly, the limit
point and
xare
not
equalona set
of measure0).
For
animage
with afinite
set
ofpixels, the
limit
point
limwn=x
(4-18)
n-*A
two-dimensional
image
x ofsize
N
by
M
can representedby
a
one-dimensional
vector ofsize
NM
by
lexicographic
ordering.The
prediction operatorP is
represented
by
a square
matrix withdimension NM
xNM. The
matrixP
shownin Figure
4-4
is
the
result of a
fourth-order
predictorfrom Figure 1-1
wherethe
elementsB, D,
E
and
G have the
value a and all other elementshave
the
value0. Note
that
all nonzerocoefficients are
in
a
band
aroundthe
diagonal
ofthe
matrix.The
zero values shownin
bold
arethe
result ofthe
boundary
conditionthat
all pixelssurrounding
the
image
arezero.
The
norm ofthe
matrixP
canbe
taken
as
the
L_
norm,
the
maximum value ofthe
sum ofthe
absolute values ofthe
coefficients on each row:Norm(P)
SI P II
=maxrow
__|prow,col|
(4-1
9)
col
In
this
case offourth-order
predictorthe
norm ofthe
matrixis
4a
.This is because
eachpredictorcaused one of
the
coefficientsin
each rowto
be
unity.There
arethus
4
onesin
each row.The
normis
thus the
sum ofthe
absolute values ofthe
predictorcoefficients.
For the
general
case,
any
predictor
P that
satisfies
(4-20)
is
a valid predictor.
for
allrows
col
(4-20)
P
=
a
A
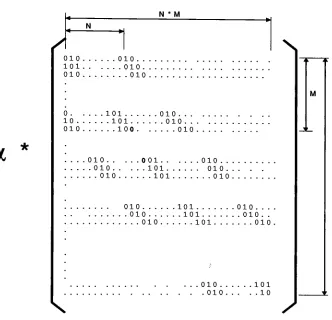
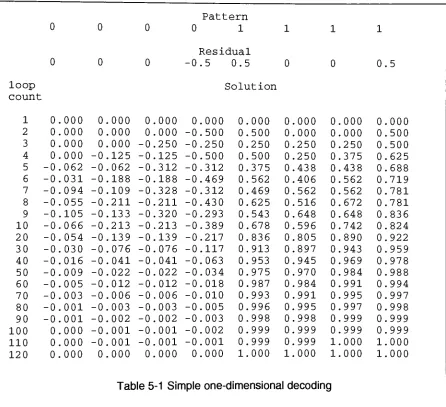
N * M N 010 101 010010. . . 010. . . 010
0 101 010...
10 101 010..
010 100 010
010. . . 010. . . . 010
-.001 010...
...101 010..
....101 010
N
010 101 010....
.010 101 010..
...010 101 010.
010.. . . 010. .
[image:39.521.100.432.168.488.2]101 . 10
\
N * Ms
4.2
Constrained
Iterative
Reconstruction
Algorithm
In
some
cases,
a priori
information
about
the
image
to
be
decoded may
be
usedto
advantage
in the
decoding
process.
Usually,
the
image is known
to
be
zerooutside
its
boundaries,
and also
that the
values
ofthe
pixels
inside
the
boundaries
may
be known
to
lie in
a certain
range.These
nonlinear conditions
may
be incorporated in
constraintsthat
are
canbe
used
in
the
decoding
process
[19].
If the
image
to
be decoded is
represented
by
x, the
predictorby
P,
andthe
residual
by
r,
we can writer=
(I-P)Cx
(4-21)
where
I is the
identity
operator.The
constraint operatorC
canbe
usedto
enforcesome
boundary
condition onthe
image,
eg., the
image is
always positive withinsome
defined
region and zerooutside.
For
all allowedimages
x:x =
Cx
(4-22)
To
obtainaniteration
equation,
we cancombine
(4-21)
and
(4-22)
to
obtain
the
identity:
x =
Cx +A(r-(I-P)Cx)
(4-23)
This
equationis in
the
form
where
the
operator
F
is defined
by
Fx
=Ar+Cx-A(I-P)Cx
=Ar
+
Gx
(4-25)
with
G
={I-X{I-P))C
(4-26)
The
signal xthat
satisfies
(4-24)
is
called a
"fixed
point
ofthe
transformation
F". A
standard method
for
finding
suchsolutions
is the
method
ofsuccessive approximations
based
uponthe iteration
equationxk+1=Fxk=Ar
+
Gxk
(4-27)
The
parameterX
canbe
usedto
controlthe
rate
ofconvergence
ofthe iteration.
Any
valid
image
canbe
chosenfor the initial image
Xn.Often the
nullimage is
chosen as amatter of convenience.
Note
that
whenthe
explicit constraintC is
removed
andX is
chosen
as
1
, equation(4-27)
becomes
the
sameas
equation(4-2).
4.2.1 Convergence
It is
assumedthat the
images
xand
the
outputs ofthe iteration
xk
are members
ofa
complete normed
linear
vectorspace,
with normllxll
defined,
for
example,
by
H-"=|
[allpixels
__X|2|(4-28)
Suppose
that
Fxs-FXj\\<y\\xs-Xj
(4-29)
In the
range
0
<y
<1,
the
operatorF is
said
to
be
a"contraction
mapping"[19]. If
y
=1the
operatorF is
saidto
be
nonexpansive.
If
y
=1
and(4-29)
holds only
if
X|=Xj
then the
operator
F is
strictly
nonexpansive.The
term
IIjc,-jc;II
canbe interpreted
asthe
distance
between two
images,
Xj
and
Xj.A
contractionmapping
has the
property
ofreducing
the
distance between
images,
as
illustrated in Figure 4-5.
Figure 4-5 Contraction mapping
If
the
operatorF
is
acontractionmapping
then
it has
a uniquefixed
point xsuchthat
x=Fx.Every
sequencedefined
by
the iteration
convergesto
xfor
every
choice ofA
consequence
of(4-29)
is
\\x-xk\\<-
\\x-x0\\
(4-30)
\-y
Thus,
every
sequence
ofiterations
converges
geometrically
to the
uniquefixed
pointxin the
sense
that
lim^^
II x-xk
11=
0
.From
above
it
also
follows
that
II
Fx{
-FXj
INI
Gxi
-Gxj
II
(4-31
)
If F is
a contraction operator
then
G
is
a contraction
operator,
and
the
iteration
willthus
converge
witheither
F
orG
being
a contraction operator.
The
convergence properties
canbe
controlledby
the
choice
ofthe
parameterX
in
(4-25).
By
making
X
sufficiently
smallit is
always
possibleto
ensure
that
F is
acontraction mapping.
As
anillustration
ofthe
behavior
ofthe
convergence
process as afunction
ofX,
the
image
"Lena"was
coded
using
this
process.The difference between
the decoded image
and
the
originalimage
as a
function
ofthe
iteration
number
is
shown
in
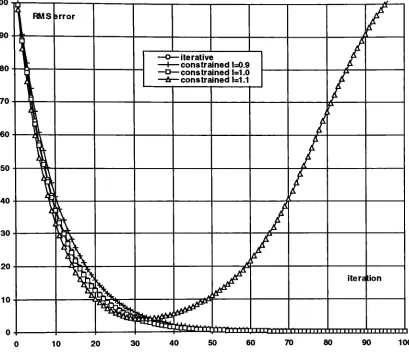
Figure 4-6 for three
values ofX:
0.9, 1.0,
and
1.1. The
constrained
iteration
with
X
=1
.0behaves exactly
asthe
standarditeration
processdiscussed
above.The
process with
X
=1.1
convergesat
first but
starts
to
diverge
afterabout
40
iterations.
100
90
80
70
60
50
40
30
20
10
T
RMS
srror0 iterative
Ined 1=0.9 a constrained1=1.0
A constrained1=1.1
iteration
- iiinrnnOJULLrrrmin 1 1 1 1 1 11"mi ii ii
[image:44.521.57.466.98.454.2]10 20 30 40
4.3
Direct
Decoding
Sometimes
it is
preferable
to
usea
one-step
decoding
process
instead
ofthe iterative
solution
described before. This may be
due to
computational
limitations
suchas speed
or
storage requirements.
The
one-step
process
may
be faster
to
computethan the
iterative
process.
For
large images memory
required
to
store
the
wholeimage
may
be
a
problem.
However,
the
direct
method can
be
implemented
efficiently
in
a
way
that
only
part of
the
image
is
needed
in
memory
at
any
time.
If the
estimation
operatorP is line